Asking if LLMs are 'Stochastic Parrots' or sophisticated reasoners is a category error…
LLMs are the instantiation of the human language memeplex in silico. LLM behaviour can be better understood once viewed through this conceptual framework.
Paper: https://t.co/jUZq2HM72z
@Dan_Jeffries1 Did some exponential-pilled bros finally realize that real-world processes have irreducible time constants and that you can't run the real world faster than real time?
Human cognitive friction has long been acting as a regularizer for a lot of digital infrastructure. It made software APIs less terrible and codebases less complex.
Now LLM disintermediation is causing this effect to fade, which in turn will cause runaway software complexity.
The same is of course true of software -- to solve a problem in a scalable manner requires a lot more work and a lot more code compared to a simple non-scalable solution.
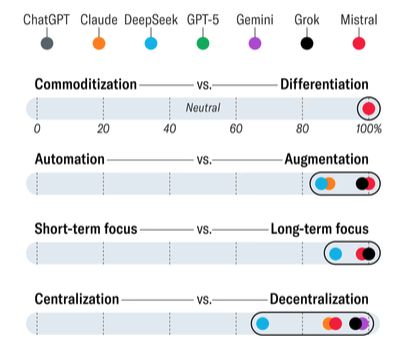
Leaders might assume that LLMs are able to offer neutral strategic advice. New research found that LLMs are heavily biased and consistently recommend strategies that align with modern managerial buzzwords... https://t.co/TYNF8nLfA6
Hot new developer skills for 2026:
1) Adversarial verification
2) Zero trust control scaffolding
Agentic coding isn't a free lunch: you're building systems to manage a superintelligent, delusional, liar.
"The IT department: Where AI goes to die".
Mollick identifies a real issue many orgs are currently struggling to articulate.
My take: Technology Departments in high perorming organisations will be unrecognisable a few years from now.
https://t.co/nIkAB9MgzX
Given the current geopolitical situation, vessel tracking with AIS data seems to be a hot topic right now. Here's a link to a paper I wrote a couple of years ago: "Interpretable Anomaly Detection on AIS Spatial Data using Generative Deep Learning" https://t.co/E5fyvH3CK4
Powerful new Harvard Business Review study.
"AI does not reduce work. It intensifies it. "
A 8-month field study at a US tech company with about 200 employees found that AI use did not shrink work, it intensified it, and made employees busier.
Task expansion happened because AI filled in gaps in knowledge, so people started doing work that used to belong to other roles or would have been outsourced or deferred.
That shift created extra coordination and review work for specialists, including fixing AI-assisted drafts and coaching colleagues whose work was only partly correct or complete.
Boundaries blurred because starting became as easy as writing a prompt, so work slipped into lunch, meetings, and the minutes right before stepping away.
Multitasking rose because people ran multiple AI threads at once and kept checking outputs, which increased attention switching and mental load.
Over time, this faster rhythm raised expectations for speed through what became visible and normal, even without explicit pressure from managers.
You cannot trust AI to handle your bank account or run a business if it randomly breaks down when you change a single word in your instructions.
A new Princeton University paper reveals that AI agents are crushing accuracy benchmarks but completely failing at actual dependability.
They tested 14 different models across 500 benchmark runs to rigorously measure their performance under pressure.
And proves that these tools are actually way too unpredictable to handle any serious tasks on their own right now.
The technology industry currently evaluates LLMs purely on average success rates, completely ignoring whether systems can get the exact same answer twice.
The authors borrowed aviation engineering principles to break true reliability down into consistency, robustness, predictability, and safety.
Consistency means the model produces the exact same correct result every single time it tries a task.
Robustness measures if the system survives minor technical glitches or a slight rephrasing of your prompt.
Predictability checks if the agent actually knows when it is confused instead of confidently guessing.
Testing proved predictability is overwhelmingly the weakest link across all modern language models.
They discovered that simply building larger models does not automatically resolve these massive dependability failures.
----
Paper Link – arxiv. org/abs/2602.16666
Paper Title: "Towards a Science of AI Agent Reliability"
LLMs are a breakthrough in NLP. They're not a breakthrough in reasoning, knowledge representation, planning, vision, robotics, multiagent systems, or any other area of AI, no matter how much you tweak them with pseudo-RL. People are confused about it because language is so protean, but the bottom line is: we have a long way to go.
The risk of AI for education is not students cheating in exams, it is people in general cheating themselves into believing they understand things they don’t.
My brain broke when I read this paper.
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2.
It's called Tiny Recursive Model (TRM) from Samsung.
How can a model 10,000x smaller be smarter?
Here's how it works:
1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess.
2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens.
3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?"
4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer.
5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution.
Why this matters:
Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost.
Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability.
Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere.
This isn't just scaling down; it's a completely different, more deliberate way of solving problems.
Two things can be true at the same time:
1. Without additional advances, LLMs won't get us to general intelligence.
2. Even without additional advances, LLMs will radically transform the economy.
Asking if LLMs are 'Stochastic Parrots' or sophisticated reasoners is a category error…
LLMs are the instantiation of the human language memeplex in silico. LLM behaviour can be better understood once viewed through this conceptual framework.
Paper: https://t.co/jUZq2HM72z