@norpadon Wow, really? I admit it was a completely random guess 😄 but it seems relevant some of our recent work. In Delta-rule based models we found that bfloat16 is not great for the triangular inverse part. See Figs. 1 and 2. Happy to chat more if its relevant.
https://t.co/UTKgMpUfth
GPT-5.2 solves our COLT 2022 open problem: “Running Time Complexity of Accelerated L1-Regularized PageRank” using a standard accelerated gradient algorithm and a complementarity margin assumption.
Link to the open problem: https://t.co/A3ZbJshudE
All proofs were generated by GPT-5.2 Pro. The key bounds on the algorithm’s total work (in the COLT’22 open-problem setting) have been auto-formalized using a combination of GPT-5.2 Pro, @HarmonicMath's Aristotle, and Gemini 3 Pro (High) on Antigravity.
Link to the proof: https://t.co/hgJ0iBcWJe
Link to the Lean code: https://t.co/DeMFDlwSC9
Link to the informalization of the Lean code: https://t.co/V5BwYoIycN
Link to my GPT-5.2 prompts: https://t.co/xwh5c6S81B
In addition to the formalization of the main result, I checked the proof myself twice. I hope I didn’t miss anything, but if I did, please let me know and I will try to fix it.
Story behind the paper and relevant work
In 2016, I worked on the convergence rate of the Iterative Soft-Thresholding Algorithm (ISTA) for l1-regularized PageRank.
Link to the corresponding paper: https://t.co/pDMN9QKkGh
Surprisingly, the running time of the algorithm depends only on the number of non-zero nodes at optimality. It was only natural to ask the same question for accelerated methods, such as FISTA. However, we quickly realized that FISTA activates more nodes than the number of non-zeros at optimality, even though it eventually converges to the same active set. In practice, we would still observe that FISTA is fast.
Link to empirical work: https://t.co/VQFJugQk0m
I tried for about three months to bound the total work of FISTA and other accelerated algorithms, and from time to time I would come back to the problem while I was a postdoctoral fellow. Eventually, I gave up. I gave it another try around 2021, and I failed again. I asked my excellent former student, Shenghao Yang, and he also failed, unfortunately. I asked a couple of prominent researchers if they think the problem is solvable, they quickly mentioned that it seemed hard. We ended up publishing it as an open problem at COLT 2022.
In 2023, David Martínez-Rubio et al. provided the first successful solution. Their solution is “orthogonal” to what was proved by GPT-5.2.
Link to their paper: https://t.co/YPUrfGhG2T I loved their work btw, I also met David in person at ICML 2024, one of the few ML conferences I ever attended.
Their proposed accelerated algorithm is not necessarily faster than ISTA; however, it does offer a new trade-off between the teleportation parameter of PageRank and the total work per iteration. More importantly, the proposed method isn’t necessarily practical, since it involves solving an expensive subproblem. To be fair, in the COLT 2022 problem, we didn’t impose the additional hard constraint of using standard accelerated methods. The problem was posed as a theoretical problem. The solution proved by GPT-5.2 establishes acceleration for the standard FISTA algorithm, which performs only one gradient computation per iteration. It also offers a clean parameterization of the total work with respect to a complementarity margin, which, for certain graph structures, shows a clear speed-up compared to ISTA.
In 2024, Zhou et al. (https://t.co/Agq5ANfhuS) gave it another go. However, in my view, their work has important drawbacks. In particular, their guarantees for accelerated localized methods (e.g., localized Chebyshev / Heavy-Ball) assume a condition on the geometric mean of certain active-ratio factors (described as Θ(\sqrt{α})) in order to obtain an accelerated bound.
Two distinctions matter for our setting:
First, their accelerated runtime bounds are parameterized by evolving-set quantities and a residual-ratio assumption, which can be evaluated during a run but is not typically interpretable or verifiable a priori from graph structure alone. The solution by GPT-5.2 instead provides an explicit transient-phase bound in terms of a standard optimization-structure condition, and converts this directly into a total work bound.
Second, they explicitly note that FISTA-style acceleration violates the monotonicity property needed to bound the per-iteration accessed volume, and emphasize that guaranteeing intermediate sparsity in accelerated frameworks is challenging. The margin-based analysis by GPT-5.2 directly targets this gap: even without any monotonicity of intermediate supports, GPT-5.2 bounded how much spurious activation can occur before the iterates enter a neighborhood of the unique minimizer, thereby yielding a concrete locality certificate for the accelerated proximal-gradient trajectory.
Since 2024, every time OpenAI or Google released a new major model, I would give it a go. This time, with GPT-5.2, it seems to have worked.
@JannisBorn wrote a very nice teaser about our Neurips paper Quantum Doubly Stochastic Transformers (spotlight). Check it out in San Diego, and in EurIPS. You can find links to the paper, video, and poster below.
#quantum#LLMs#Transformers
https://t.co/8xAPPnhA3E
We have a new preprint with Almudena Carrera Vazquez @anedumlACV, one of the last (and favorite) works that I contributed to before leaving IBM.
It is about quantum algorithms for approximating spectral gaps between consecutive pairs of eigenvalues. Link:
https://t.co/17BjPyjmkA
Dear everyone, I have been using X less and less lately. Let's stay connected on Bluesky and/or Linkedin:
https://t.co/LfwbLCkAov
https://t.co/tTbWVvZTss
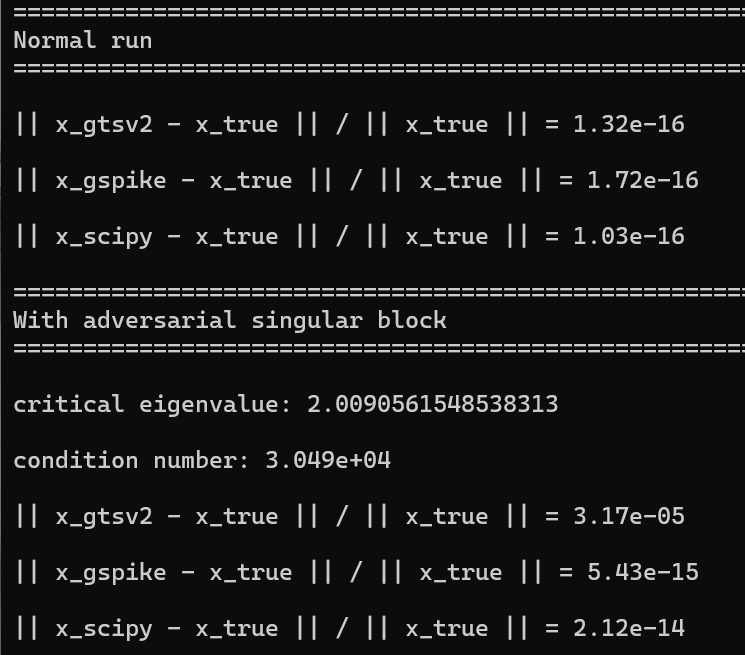
A little less than ~10 years ago we developed a cuda kernel to solve tridiagonal linear systems of equations. I was recently trying out WSL on my personal laptop, which has a dedicated GPU, and I thought to try to run that rusty code and see what happens. Some findings:
3) A numerical bug of the cuSPARSE gtsv solver that we reported in the 2015 paper is still there..! By planting a small adversarial non-invertible block of size 32*32, gtsv2 struggles to solve the linear system, while both gspike and scipy solve it to 16 digits of accuracy.
I want to also thank the anonymous reviewers for quality feedback, and all the people who provided helpful discussions (listed in the preprint), especially Ryan Schneider and Daniel Kressner who promptly (and independently) pointed a technical detail in the initial draft.
I'm happy to share that a revised version of our paper has been accepted at #NeurIPS2024. I want to thank my co-authors, Marko Mladenović and my phd supervisor Mathieu Luisier for the excellent collaboration, and my manager @teodorolaino for all the support.
We have a new preprint on DFT and eigenvalue algorithms:
"Hermitian Pseudospectral Shattering, Cholesky, Hermitian Eigenvalues, and Density Functional Theory in Nearly Matrix Multiplication Time". Link to Arxiv:
https://t.co/zHhVJfy9LS