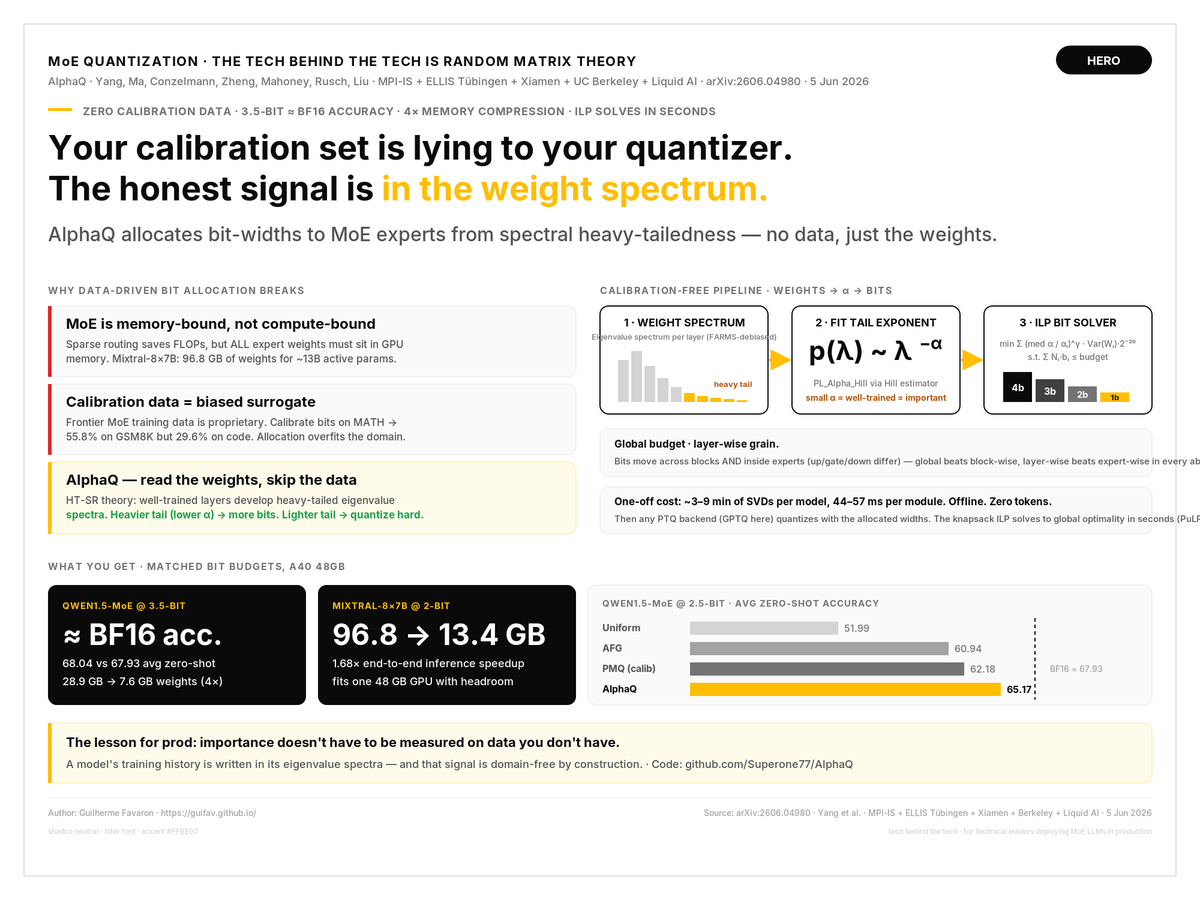
Deploying MoE LLMs? Your memory bill isn't set by the experts that compute — it's set by the ones that just sit in HBM. Mixed-precision quantization fixes that, but today's bit allocators ask calibration data which experts matter. That's the trap.
New from @MPI_IS + @ELLISInst_Tue (AlphaQ, arXiv:2606.04980) by @Shiwei_Liu66, @tk_rusch (@LiquidAI_), Michael Mahoney et al. — the importance signal was in the weights all along.
The problem: frontier MoE training data is proprietary, so every calibration set is a biased surrogate. Calibrate Mixtral's bit map on MATH: 55.8 on GSM8K, 29.6 on code. Calibrate on GitHub-Code: 37.7 on code, 13.7 on math. Same model, same budget.
AlphaQ throws the data away. Random Matrix Theory (HT-SR): well-trained layers develop heavy-tailed weight spectra. Fit the power-law tail exponent per layer (Hill estimator, FARMS-debiased) — heavier tail = better trained = more bits. Then one global ILP (a knapsack) assigns 1–4 bits per projection layer under a single budget. Spectra: 3–9 min, once, offline. Solver: seconds. Tokens: zero.
Results:
- Qwen1.5-MoE @3.5-bit ≈ BF16 accuracy at 1/4 the memory (7.6GB)
- Mixtral-8x7B: 96.8 → 13.4GB @2-bit, 1.68x faster
- beats calibration-based PMQ/Hessian/AFG at matched budgets
The lesson for prod: importance doesn't have to be measured on data you don't have. The checkpoint already knows.
Code: https://t.co/KbuTe8Rbwf
Most long-context LLM serving stacks already use sparse attention + KV-cache offload to CPU. But two costs survive — and at 128K they ARE your decode bottleneck.
New from @NVIDIAAIDev (SparDA, arXiv:2606.04511) by @Guangxuan_Xiao, @songhan_mit et al. — the bottleneck isn't FLOPs. It's data movement in time.
1) Offloaded KV must be fetched back over PCIe every step — synchronous, on the critical path.
2) Sparse attention is O(T), but the top-k SELECTION step stays O(T²) and overtakes attention as context grows.
SparDA adds a 4th per-layer projection beside Q/K/V — the Forecast. At layer L it predicts the KV blocks layer L+1 will need, ONE step ahead. So the CPU→GPU prefetch overlaps the current layer's compute, and selection uses 1 head per GQA group (no softmax) instead of one per query head.
It's a 0.41% (33.5M) add-on: train only the Forecast via KL-distillation against the original selector. Base model frozen. Now at @thinkymachines.
Results on H100, MiniCPM4.1-8B & NOSA-8B @128K:
- 1.69x decode, 1.25x prefill vs sparse-offload
- up to 5.3x decode throughput vs non-offload (bigger batches)
- selection cost cut >2x; accuracy matches/beats sparse (+2.3 avg), gap widening with length
The lesson for prod: profile data movement, not just FLOPs — and schedule the fetch one step ahead.
Code: https://t.co/t15P0dBMZG
Speculative decoding is how most production LLM stacks hit throughput today. The frontier moved twice: autoregressive drafts -> block diffusion drafts (one forward pass predicts the whole block). DFlash set the SOTA. Then block-diffusion drafts hit a ceiling: scaling draft depth stopped helping.
New from @PKU1898 + @TencentAI_News (DFlare, arXiv:2606.02091, Jun 1 2026): the ceiling wasn't depth. It was conditioning.
DFlash fuses 5 target-model hidden states through ONE FC layer, then injects that same vector into every draft layer. Identical input across layers -> no specialization -> depth saturates.
DFlare's fix is almost free: 63 learnable scalars (D=7 draft layers x T=9 target states). Each draft layer attends to its OWN softmax-weighted combination of target hidden states. Plus heterogeneous KV projections so target-context and draft-positions stop sharing Wk/Wv. No new modules. Inference adds virtually zero latency.
Results on @Alibaba_Qwen 4B/8B and GPT-OSS-20B (greedy, wall-clock):
- 5.52x on Qwen3-4B (+10.6% vs DFlash)
- 5.46x on Qwen3-8B (+8.1%)
- 3.91x on GPT-OSS-20B (+5.4%)
- Acceptance length 7.47 / 7.33 / 4.93 (DFlash plateaued; DFlare keeps scaling with depth and data 800K -> 2.4M)
For tech leaders: when your speculative-decoding speedup plateaus, the bottleneck is usually conditioning topology, not draft params. The cheap fix is per-layer.
Code (Tencent/AngelSlim): https://t.co/HIZEeCWbzI
The agentic apps you ship are stateful programs. The serving system underneath them was built for single-shot requests. That mismatch is the real cost.
New from @UChicagoCS (Ding, Hosseini, Gholami, Xiang, Hoffmann -- ConServe, arXiv:2606.01839, Jun 1 2026): raise the scheduling unit from the turn to the conversation, and per-turn brittleness disappears.
Per-turn schedulers must PREDICT what they cannot see: decode length, tool behavior, KV growth. Any predictor will eventually misjudge -- SLO miss grows linearly in error rate. The brittleness is in the unit, not the predictor.
Zoom out one level. A conversation = one heavy turn-1 prefill (compute-bound) + a long memory-bound tail of decode + short append-prefills. The original prefill-decode abstraction, at the right granularity.
ConServe (on @vllm_project + @lmcache):
- Route turn-1 prefill to a high-throughput prefiller
- Transfer KV exactly once
- Pin the conversation to one decoder for its entire tail
- Two observables only: input length + active KV occupancy. No learned cost model.
vs the AMPD per-turn predictor on SWE-bench (4x A40, Qwen3-0.6B):
- p95 TTFET -51.08% (time-to-first-effective-token)
- Energy +7.51%; +22.75% more on heterogeneous tiers
- Zero SLO violations at saturation
For tech leaders: per-turn TTFT lies about what your users wait on. Measure TTFET, pin conversations to decoders.
https://t.co/CewAi37dta
Your MoE training stack was built for humans. The coding agents that will extend it pay a hidden tax for that.
New from @ruihanglai + @XiongChenyan + @tqchenml at @CarnegieMellon (PithTrain, arXiv:2605.31463, May 29 2026): a compact, agent-native MoE training framework + a new metric production stacks were missing — agent-task efficiency (ATE).
The hidden tax. Megatron-LM = 149K LoC. DeepSpeed = 167K. Plugin systems, registry indirection, in-tree CUDA. Great for human engineers; expensive for an agent that has to locate code, trace what runs at a call site, and verify a change.
Four agent-native principles:
• Compact codebase (PithTrain: 11K LoC)
• Python-native (Triton DSL for kernels only)
• No implicit indirection — what runs is what you read
• Agent skills in-repo (SKILL.md + scripts)
Throughput parity. On Qwen3-30B-A3B, GPT-OSS-20B, DeepSeek-V2-Lite across H100/B200, PithTrain matches @nvidia Megatron-LM on 4/5 configs via DualPipeV + torch.compile(fullgraph=True).
ATE-Bench, fixed agent = @AnthropicAI Claude Code Opus 4.7:
• Q&A: up to 67% fewer turns vs Megatron
• Train & Evaluate: 38.5 vs 55.5 min, 92 vs 163 turns
• MoBA integration editing: 4.7K vs 13.1K vs 22.2K tokens
• Skills ablation, validate-correctness: 114 → 34 turns
For tech leaders: if a coding agent is going to evolve your training stack, framework structure is the new bottleneck — not just FLOPS.
Repo: https://t.co/aozpUV8ftn
https://t.co/EGOQvbJkdH
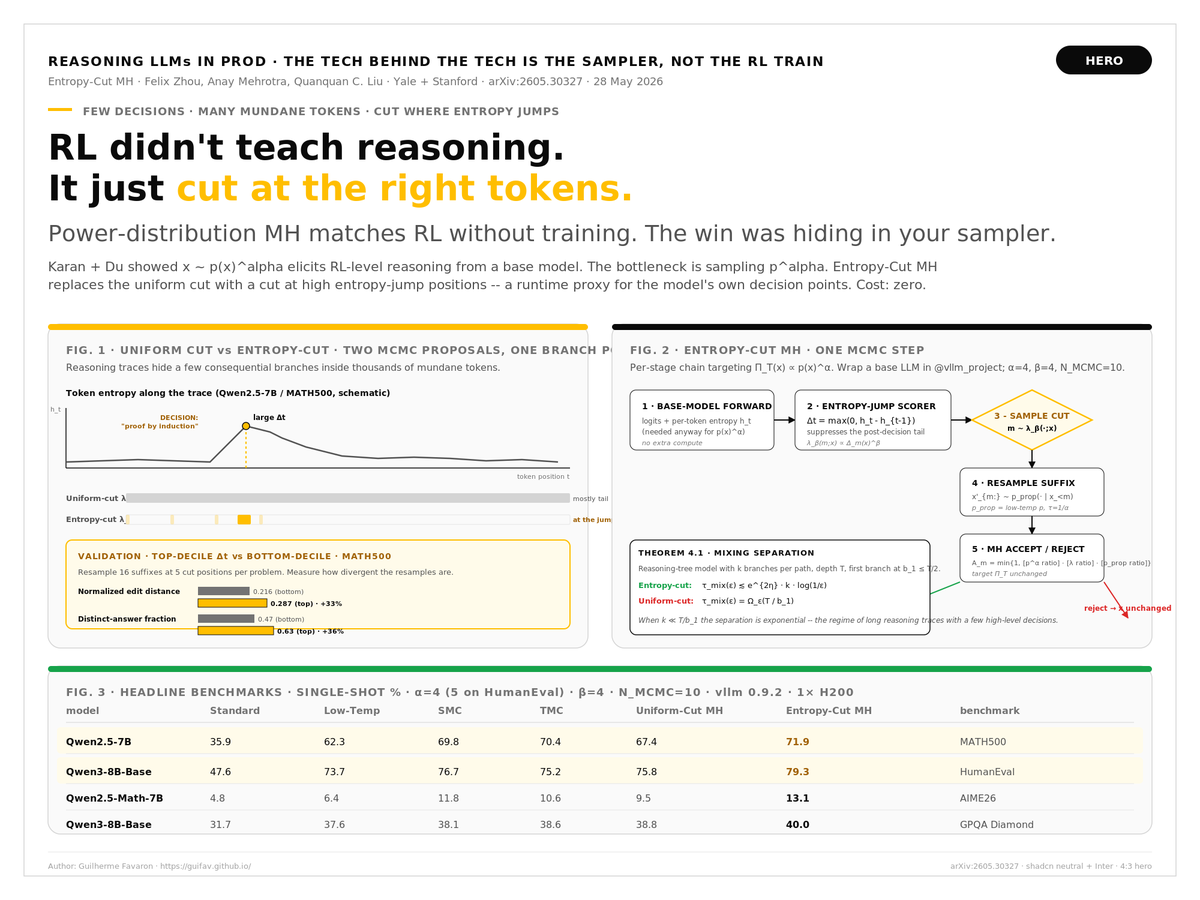
Your "RL-trained reasoner" is mostly a sampler.
RL post-training doesn't teach base LLMs new reasoning — it concentrates mass on traces the base already rates plausible. @aakaran31 + @du_yilun (Harvard, arXiv:2510.14901) showed you can match RL by sampling x ∝ p(x)^α — no training, no data, no verifier.
Catch: p^α is intractable. Their MH sampler picks a uniform cut and resamples the suffix. But reasoning traces hide a few consequential decisions in thousands of mundane tokens — a uniform cut mostly rewrites the tail.
New from @felix_zhou_cfz + @AnayMehrotra (@Yale + @Stanford, arXiv:2605.30327, May 28 2026): Entropy-Cut Metropolis-Hastings. Same MH frame, same target. Cut where next-token entropy jumps: Δt = max(0, h_t − h_{t−1}).
Validated: top-decile Δt cuts give 1.33× more edit distance + 1.36× more distinct answers than bottom-decile. Entropy spikes mark decisions; the tail executes.
Theory: mixing O(k) in semantic decisions vs Ω(T/b₁) in tokens — exponential separation when k ≪ T.
Across MATH500 / HumanEval / GPQA / AIME26 on Qwen2.5-7B, Qwen3-8B-Base, Phi-4-mini:
• Qwen2.5-7B MATH500: 35.9 → 71.9
• Qwen3-8B HumanEval: 47.6 → 79.3
• Qwen2.5-Math-7B AIME26: 4.8 → 13.1
Beats Standard, Low-Temp, SMC, TMC, Uniform-Cut MH. pass@k diversity preserved.
Cost: zero. Entropies already in the forward pass. Drop-in inside @vllm_project.
For tech leaders: reasoning gains aren't gated by RL budget — they're gated by where your MCMC cuts.
https://t.co/QcsFqZ8lAQ
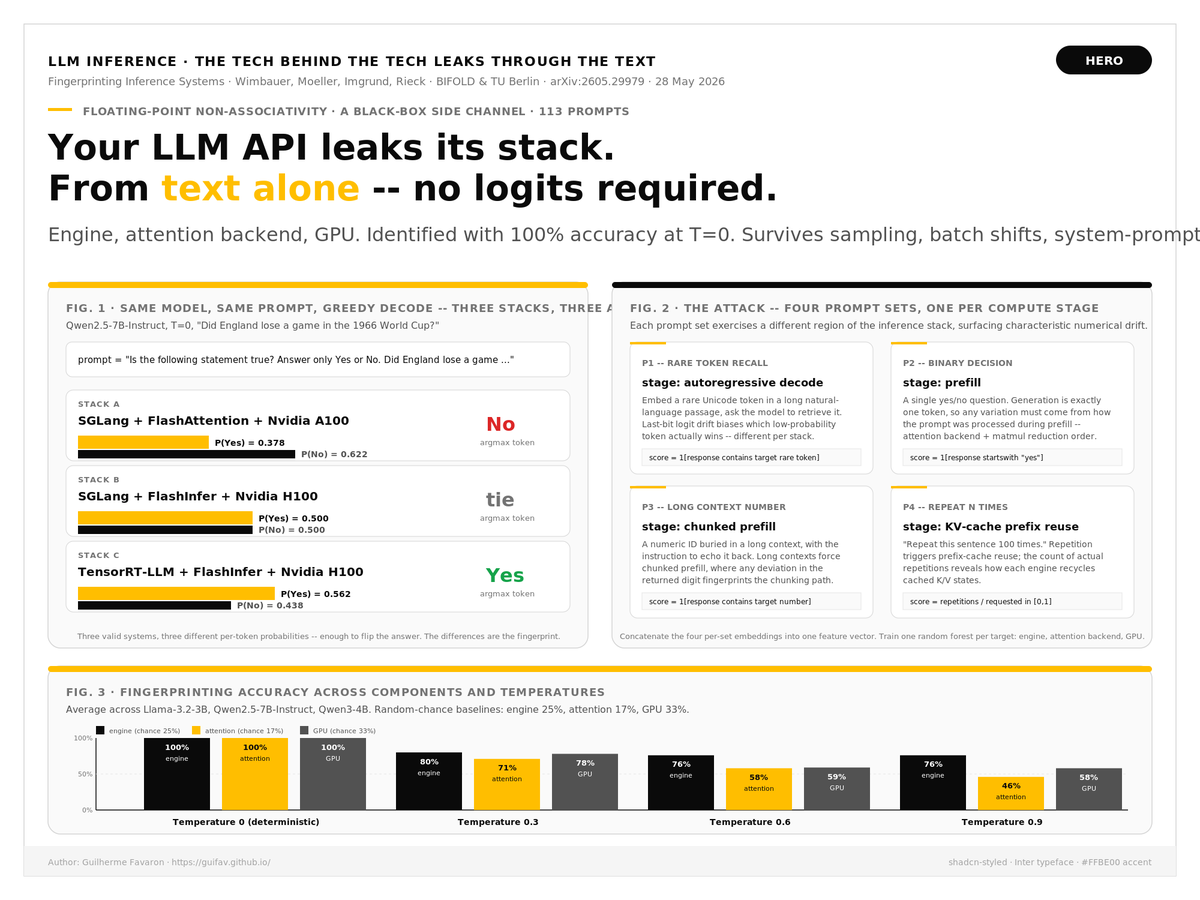
Your LLM API is leaking its stack — not the model, the stack underneath.
@mlsec at @bifoldberlin / @TUBerlin (arXiv:2605.29979, May 28 2026): floating-point non-associativity is a side channel. Same model, same prompt, different engine / attention / GPU → different tokens. From chat output only — no logits.
Example. Qwen2.5-7B, greedy, "Did England lose a 1966 World Cup game?":
• SGLang + FlashAttention + A100 → P(Yes)=0.378
• SGLang + FlashInfer + H100 → P(Yes)=0.500
• TensorRT-LLM + FlashInfer + H100 → P(Yes)=0.562
The attack: four prompt sets, each probing one stage:
1) Rare-token recall → autoregressive decode
2) Yes/No → prefill
3) Numeric ID in long context → chunked prefill
4) "Repeat N times" → KV-cache reuse
Score responses, train a random forest.
Across 4 engines (@vllm_project, @sgl_project, TensorRT-LLM, LMDeploy), 6 attention backends, 3 GPUs (@nvidia H100/A100/L4) on Llama-3.2 (@AIatMeta) + Qwen (@Alibaba_Qwen):
• T=0: 100% ID on engine, attention, GPU
• T=0.6: 76% engine / 58% attention / 59% GPU
• 113 prompts is enough
• Survives unseen batch sizes + app prompts (99.7%)
Why prod leaders should care: pin your engine and an attacker aims CVE-2026-22778 (vLLM RCE) or CVE-2026-5760 (SGLang RCE) at it. "Just unify the kernels" isn't a defense — unified stacks add 100%+ latency.
Real mitigations cost utility: noise breaks deterministic decode, rate-limits are Sybil-evadable.
Determinism is now a security property.
https://t.co/rclQJfiaed
Your "temperature 0" LLM service is not deterministic. Same prompt, different batch, different tokens.
@thinkymachines's fix: rewrite every matmul/attention/RMSNorm kernel as batch-invariant. Always correct. Always slow — +119% to +143% over BF16.
LLM-42's fix: re-decode every token under a deterministic verifier. Also correct. Still slow — +50% to +70%.
New from @uconn_cse + @ucdavis (arXiv:2605.30218, May 28 2026): MarginGate. Three measured facts:
1) Across 5 open-weight LLMs + MATH500 / GSM8K / HumanEval — only 0.3% to 1.3% of greedy decode steps actually flip when the batch changes. Over 98.7% are already stable.
2) Before a flip, the K/V cache shows no drift. The branch point is local to the current column.
3) Flipped steps share a fingerprint: top-1 / top-2 logit margin near zero. Stable steps have N(Δ)≈1; divergent steps have N(Δ)≈2.
Policy: stay on the BF16 fast path; invoke the @vllm_project-style deterministic verifier only when the margin gate fires; on a confirmed mismatch, overwrite a single K/V column.
Results on Llama-3.1-8B (@AIatMeta) + Qwen2.5-14B:
• 100% sequence-level determinism
• 18.56% / 15.05% verifier triggers
• 2.23× / 1.99× lower latency overhead than always-on LLM-42
• MATH500-calibrated, transfers to GSM8K / SharedGPT / HumanEval
For tech leaders: determinism in prod isn't a kernel rewrite, it's a 1% problem. Pay verifier cost only on steps the model already flags as risky.
https://t.co/lwOmofHq03
The thing slowing down RLVR for reasoning isn't the reward. It's the baseline.
New from @USTCGlobal + @LSEStatistics + @oxengsci (arXiv:2605.27293, 26 May 2026): BASIS — Batchwise Advantage estimation from Single-rollout Information Sharing.
Tech behind the tech: PPO pays a critic network. GRPO pays 8 rollouts per prompt to estimate one value. REINFORCE++ shares ONE global mean across the batch — cheap, but noisy.
BASIS keeps the single-rollout budget and replaces the baseline with a per-prompt weighted average of OTHER prompts' rewards in the same batch. Weights from a Best Linear Unbiased Estimator (Prop. 1): w_ij ∝ V_i V_j / σ_j², w_ii = 0. Seed V_i with an offline KL-regularized estimate from @deepseek_ai-style reference rollouts, recalibrate β online.
Value estimation on @Alibaba_Qwen Qwen2.5-Math-7B:
• −69% MSE vs REINFORCE++ with G=1
• lower MSE than GRPO with G=8
Policy optimization on Qwen3-4B / DAPO-Math-17K, avg of AIME 24/25, AMC, MATH-500, Minerva, Olympiad, HMMT:
• GRPO+BASIS G=1, 150 steps: 47.3% in 8.3h
• GRPO G=8, 300 steps: 47.1% in 15.5h
• Matches the 8-rollout baseline at ~half the wall clock.
• +4.2 pp over GRPO+REINFORCE++ at −9.4h.
For tech leaders: cheaper RLVR isn't a rollout problem — it's a baseline problem. And the information you need is already in the batch.
https://t.co/EJqm1csXL0
The training objective that makes your MoE great at training is silently slowing it down at inference.
New ICML 2026 from @Beihang1952 + @Huawei (arXiv:2605.27081, 26 May 2026): ReMoE — Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference.
Tech behind the tech: standard MoE training adds a load-balancing loss to spread tokens across experts. Great for expert-parallel training. Bad for single-request decoding on a phone or Jetson, where few experts fit in fast memory and the rest live on UFS / SSD. Every step pulls a different expert set; every step thrashes the cache.
ReMoE fixes this without touching architecture, weights, or kernels. Freeze everything except the gate; fine-tune the router with two losses: a temporal-locality term (reuse mass over the previous step's Top-K) and a Trust-KL anchor to the pretrained router so semantics don't drift. Top-K is non-differentiable, so the surrogate is the mass Pt puts on last step's set, stop_grad on it.
Bound: under recency cache with C ≥ K, avg fetches ≤ K(1 − EOR).
Results on @deepseek_ai V2-Lite and @Alibaba_Qwen 1.5-MoE-A2.7B:
• +26–27% expert overlap, no downstream regression
• @vllm_project GPU-CPU offload: +8.4% throughput
• @ggerganov llama.cpp on Jetson Orin NX: −44–50% TPOT, 1.77–1.99× decode speedup
For tech leaders: edge MoE serving is no longer a FLOPS problem. It is an expert-I/O problem, and the upstream lever is the router itself.
https://t.co/yNooGUOpMi
The hidden bottleneck in agentic AI isn't the model. It's the harness around the model.
New from @ShangdingG95714 at @berkeley_ai (arXiv:2605.26112, 25 May 2026): once your foundation model is wired to tools, terminals, repos and memory, performance is no longer set by next-token prediction. It is set by a system of six components: R reasoning, M memory, C context, S skill router, O orchestration, G verification & governance.
P_H = Φ(R, M, C, S, O, G).
Model scaling improves R. System scaling improves M, C, S, O, G. Once R clears a capability threshold, leverage moves down the stack.
Three bottlenecks — and three failure modes already familiar in production:
• Context governance: bigger windows do not buy you better attention. Failure: exposure without access. Move: per-turn assembly as a selection policy.
• Trustworthy memory: storage is not the hard part. Failure: stale-but-confident. Move: per-entry confidence + recency, verified vs the environment.
• Dynamic skill routing: confident-but-unchecked subagents accumulate as silent debt. Move: learned routing + post-condition checks per skill.
Empirical anchor: in BrowseComp multi-agent runs, token usage alone explains 80% of variance; +tool calls +model choice → 95%. Compute allocation, not model identity, dominates.
For tech leaders: stop reporting one-shot accuracy. Measure trajectory quality, memory hygiene, drift across sessions.
https://t.co/7K7qsc6KHi
@elonmusk Ok. Thanks for sharing. Nothing to do until it's publicly released.
Not sure about the relationship between grok and cursor. Please detail it.
The reason FlashAttention beat naive attention was never about FLOPs. It was about I/O — bytes moved between HBM and SRAM. That insight rewired every modern serving stack.
New from @AleksandrosSob1, Pál András Papp and @zouzias at Huawei Zurich (arXiv:2605.23751, 22 May 2026): FlashAttention is not the floor. Its I/O cost is Θ(n²·d²/M) — quadratic in sequence length. The trivial lower bound only needs Ω(n·d): just read the inputs, write the output.
That gap is not closed by smarter tiling. It is closed by *what* you compute.
Building on Alman & Song's polynomial-approximation algorithm (NeurIPS'23), the authors prove tight upper *and* lower I/O bounds for approximate attention in the red-blue pebble model. The mechanism: a degree-g polynomial replaces softmax, so A ≈ D⁻¹·U₁(U₂ᵀV). The non-linearity disappears, the two matmuls reorder, and the cost becomes almost-linear in n across most cache regimes.
• Case I (M = Ω(d·r), r = n^o(1)): Θ(n·d) — matches the trivial lower bound. FlashAttention is Θ(n²·d²/M). The gap grows with n.
• Cases II–IV: still almost-linear in n; lower bounds tight up to constants when g = O(1).
Honest caveat: r = C(d+g, g) is combinatorial, so cache pressure is real and a hardware-grade kernel is future work.
For tech leaders running long-context inference: the lesson isn't "swap FlashAttention". The next-decade bottleneck is the I/O cost of exactness — and there is now a proven near-linear floor below it.
https://t.co/hbmIcQKZzg
The frontier of LLM serving is not the model — it is the memory the model edits while it decodes.
Softmax attention keeps an unbounded KV cache. Linear attention compresses it into a fixed-size recurrent state — constant-memory decoding, linear-time prefill. The price: every association shares that finite space, so what gets overwritten matters more than what gets written.
New from @ahatamiz1, @YejinChoinka and @jankautz at @NVIDIAAI (arXiv:2605.22791, 21 May 2026): Gated DeltaNet-2 unties a quiet bottleneck shared by Gated DeltaNet, KDA and Mamba-3 — one scalar β_t controlling two different decisions every step.
The tie: how much old content to erase on the key side, and how much new content to commit on the value side. β_t was doing both. GDN-2 splits them into a channel-wise erase gate b_t and a channel-wise write gate w_t. Each coordinate of compressed memory negotiates its own overwrite policy. Recovers KDA when b_t = w_t = β_t·1. Same chunkwise WY kernel, gate-aware backward, no throughput tax.
1.3B params, 100B FineWeb-Edu tokens, vs Mamba-2 / GDN / KDA / Mamba-3:
• Commonsense avg: 53.11 recurrent / 53.97 hybrid — best in class
• MK-NIAH-1 @4K (multi-key retrieval): 37.8 recurrent / 48.0 hybrid — top
• S-NIAH-3 @4K: 99.6 recurrent
If your serving stack lives or dies by long-context recall on a fixed memory budget, the lesson is operational: stop sharing one knob between erase and write.
https://t.co/hD7PNkjYMH
code: https://t.co/wYcYN0IShn
Test-time compute only makes a model smarter when its inner dynamics actually converge to the right basin. Otherwise you are just paying for the same wrong answer, faster.
New paper from @ZhengyangGeng, Benhao Huang and @zicokolter at @SCSatCMU (arXiv:2605.21488, 20 May 2026, ICML 2026) makes this concrete.
Equilibrium Reasoners reframe iterative reasoning as a learned fixed-point system z_{k+1} = f_θ(z_k; x). Training shapes an attractor landscape; inference descends it. Stable fixed points = valid solutions.
Two task-agnostic interventions on top of a weight-tied iterative backbone:
1) Randomized initialization (sample z₀ per trajectory, not fixed) so breadth at test time hits diverse basins.
2) Noise injection (β·ε at each step) so depth at test time escapes narrow / spurious attractors.
One 5M-param block, trained at 16 iterations, unrolled to ~1,024 iters at test time. That is ~40,000 effective layers.
Sudoku-Extreme: feedforward 2.6 → HRM 55.0 → TRM 84.8 → EqR 99.8
Maze-Unique: feedforward 0.0 → TRM 44.9 → URM 51.4 → EqR 93.0
Operational gift for production: residual ‖f_θ(z;x) − z‖ tracks accuracy. Restarts can be ranked without a verifier. NFE = D × B is the real compute knob.
If the inner loop is your product (planners, code agents, multi-hop QA), train the dynamics — not just the output.
https://t.co/pnzYoXx61Z
code: https://t.co/bBGos2O3Bk