@makinai_ and @philna00 presenting our paper on calibration-free in-training compression of SSMs at #ICLR2026 in Rio 🇧🇷
Paper link: https://t.co/BQ7E5kZoLV
Three years ago we started working on a stealth project that we weren’t sure we’d ever talk about publicly... until today.
Breakthrough: Introducing LFM-Zero: the first foundation model trained on 0 tokens.
No pretraining. No finetuning. No data. Instead, we initialize from an implicit probabilistic prior over the underlying data-generating process, allowing the model to converge without ever observing data.
LFM-Zero matches or surpasses models trained on 10T+ tokens across reasoning, coding, and multimodal tasks. Turns out that pretraining was just regularization that was holding us back.
> Read our Tech Report here: https://t.co/aIWbx77IEf
Today, we release LFM2.5-350M. Agentic loops at 350M parameters.
A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle.
<500MB when quantized, built for environments where compute, memory, and latency are constrained.
🧵
🚀 Small is the new big in AI.
In “The Curious Case of In-Training Compression of State Space Models,” @tk_rusch et al. introduce CompreSSM: compressing state space models already during training.
💡 Faster, leaner, and still high-performing.
Accepted at @iclr_conf 2026! 🇧🇷
Read the full breakdown on our website: https://t.co/wCvcZs6R5T
🧵[1/5] Qwen3.5 demonstrates the potential of hybrid LLMs. But how well do the Linear Attention layers manage their associative memory?
Previous research indicates a low effective rank, which we show:
1. Amplifies query noise
2. Poorly conditions gradients
3. Wastes memory.
🧵[4/5] We demonstrate that (Gated) DeltaNet states can be pruned by ~50% with minimal degradation in perplexity or zero-shot reasoning.
This structured reduction delivers:
🚀 speedup in training throughput
📉 reduction in peak VRAM usage.
🧵[3/5] Why prune? Because low rank doesn't just waste memory. It hurts retrieval & training stability.
Standard pruning can break the causal convolutions. Our fix? Employing semi-orthogonal axis-aligned transformations that preserve their per-channel structure.
🧵[2/5] Consequently, we propose a rank-based structured pruning framework which:
✂️ Allows removing ~50% of Key/Query channels
📉 Has Minimal impact on perplexity
⚙️ Remains fully compatible with causal convolutions.
🧵[1/5] Qwen3.5 demonstrates the potential of hybrid LLMs. But how well do the Linear Attention layers manage their associative memory?
Previous research indicates a low effective rank, which we show:
1. Amplifies query noise
2. Poorly conditions gradients
3. Wastes memory.
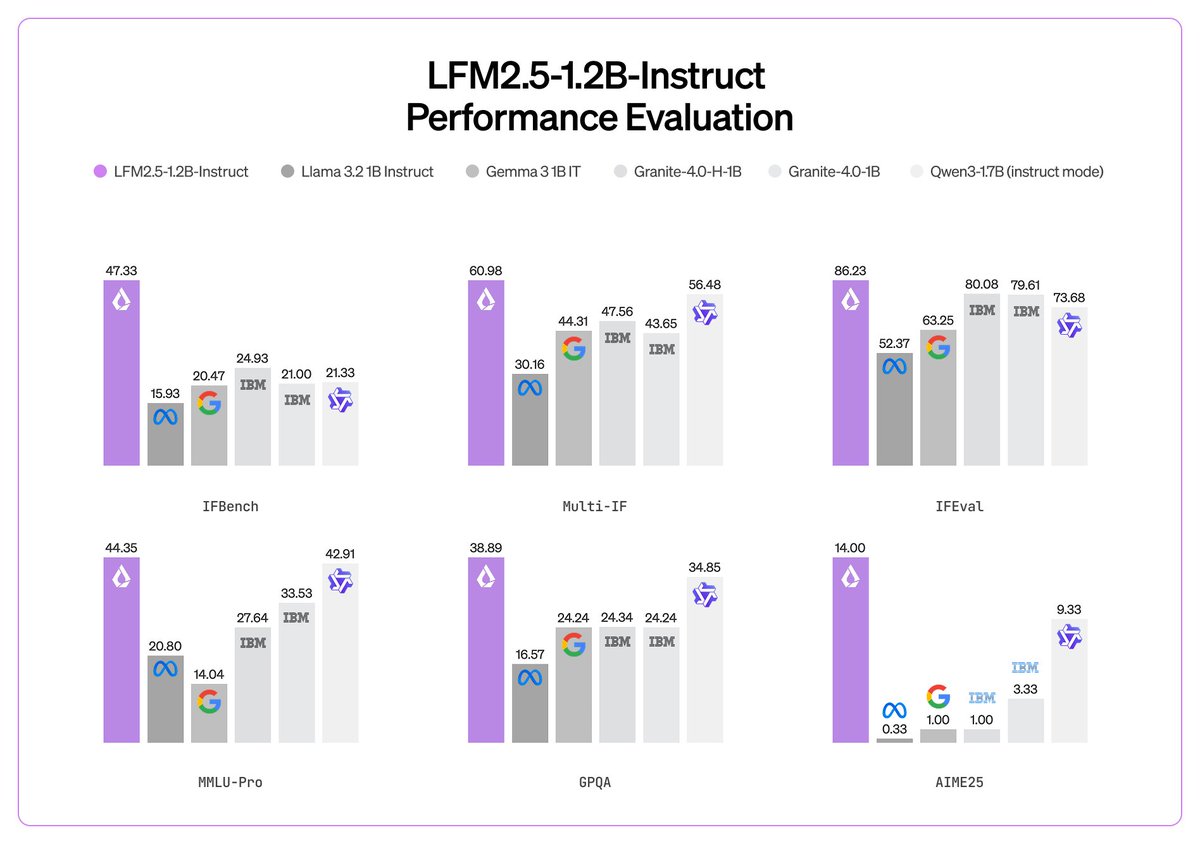
Today, we release LFM2.5, our most capable family of tiny on-device foundation models.
It’s built to power reliable on-device agentic applications: higher quality, lower latency, and broader modality support in the ~1B parameter class.
> LFM2.5 builds on our LFM2 device-optimized hybrid architecture
> Pretraining scaled from 10T → 28T tokens
> Expanded reinforcement learning post-training
> Higher ceilings for instruction following
🧵
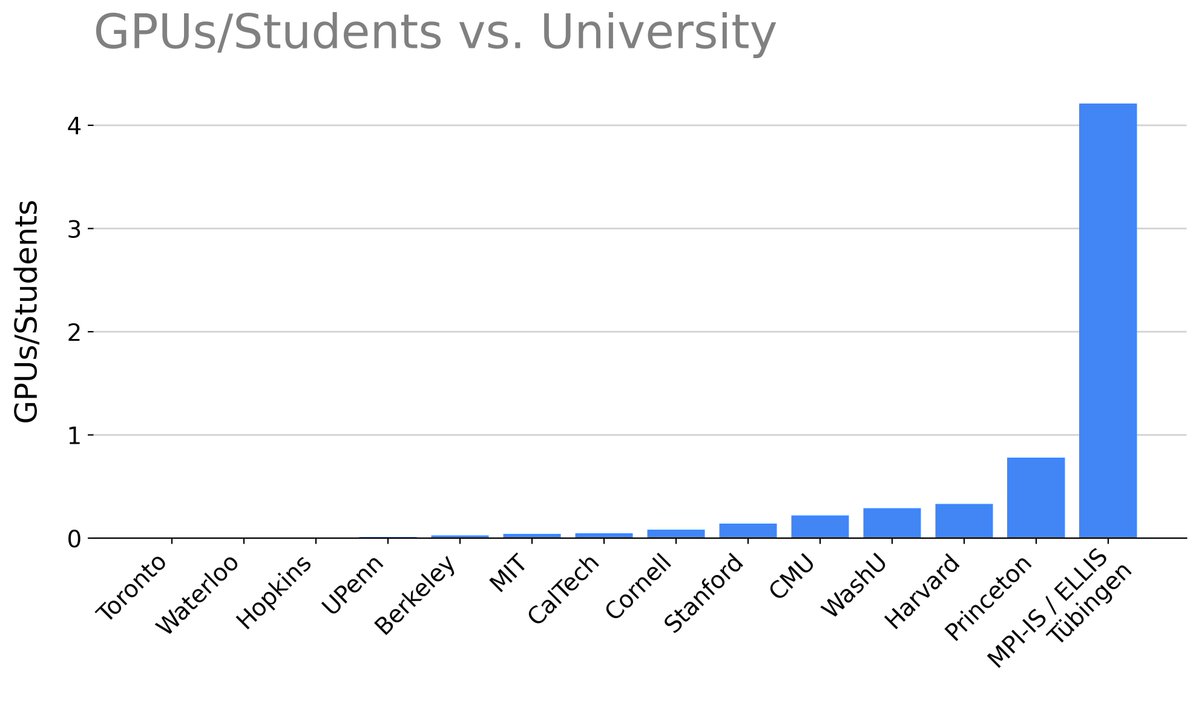
Added @MPI_IS@ELLISInst_Tue to the plot below. And this is only considering A100 or newer (H100/B200) GPUs.
Periodic reminder to join us in the small beautiful town of Tübingen where we have a good ratio of GPUs per researcher (better than most academic places) and great PIs!
Today we introduce Liquid Labs, our advanced research unit, with the goal of understanding and building efficient and adaptive intelligence systems.
Liquid Labs consolidates our existing research efforts at Liquid across architecture of foundation models, multimodality, training, data, and inference. The lab also will be home to new frontier research work across the broad range of foundation model build-up stack.
Read the full announcement: https://t.co/huPO1di46d
We are hiring: https://t.co/s2cWDFixbU
Also find us at NeurIPS 2025 exhibition hall! 🚀
We @LiquidAI will be at #NeurIPS2025 this year! ⚛️
If you are
> doing a PhD in ML / NLP / CV / RL
> a strong engineer with a first-principled mindset
> interested in training best-in-class multimodal foundation models 🚀
Join us @LiquidAI!! Find us at Booth #1605 — and DM me for an invite-only dinner
🚀 The new call for Principal Investigators at the ELLIS Institute Tübingen is now open!
We are looking for Principal Investigators as Hector Endowed Fellows in all areas of Machine Learning, Artificial Intelligence, and related fields. These positions offer the exciting possibility of co-appointments with the @MPI_IS and the Tübingen AI Center.
📌 Apply here: https://t.co/zkrJh3zsiD
🗓 Deadline: December 15, 2025
Join our team of Principal Investigators and help shape the future of AI research!
#Hiring #AI #MachineLearning #PrincipalInvestigator #Research #Tübingen
@ELLISforEurope
Our Principal Investigators @orvieto_antonio , @CeleMenDu, @maximilian_dax , Rediet Abebe, @Shiwei_Liu66, @tk_rusch, and @wielandbr are looking for motivated students interested in doing an internship at the ELLIS Institute Tübingen.
The start date and duration of the internship can be discussed directly with the PI, or you can mention your preferences in your motivation letter.
Learn more about their research groups on our website: https://t.co/aqKa1cgjcD
Apply by completing the form here: https://t.co/C5CBKGCwrM
Join the ELLIS Institute Tübingen and become a part of the @Cyber_Valley community! 🙌
















![philna00's tweet photo. 🧵[1/5] Qwen3.5 demonstrates the potential of hybrid LLMs. But how well do the Linear Attention layers manage their associative memory?
Previous research indicates a low effective rank, which we show:
1. Amplifies query noise
2. Poorly conditions gradients
3. Wastes memory. https://t.co/ietJfQqlW6](https://pbs.twimg.com/media/HBYSELuXIAAqPde.png)