Interesting to work on this report with Epoch. We found that AI progress speeds have been accelerating since ~mid 2024 (on 3/4 of the metrics we considered).
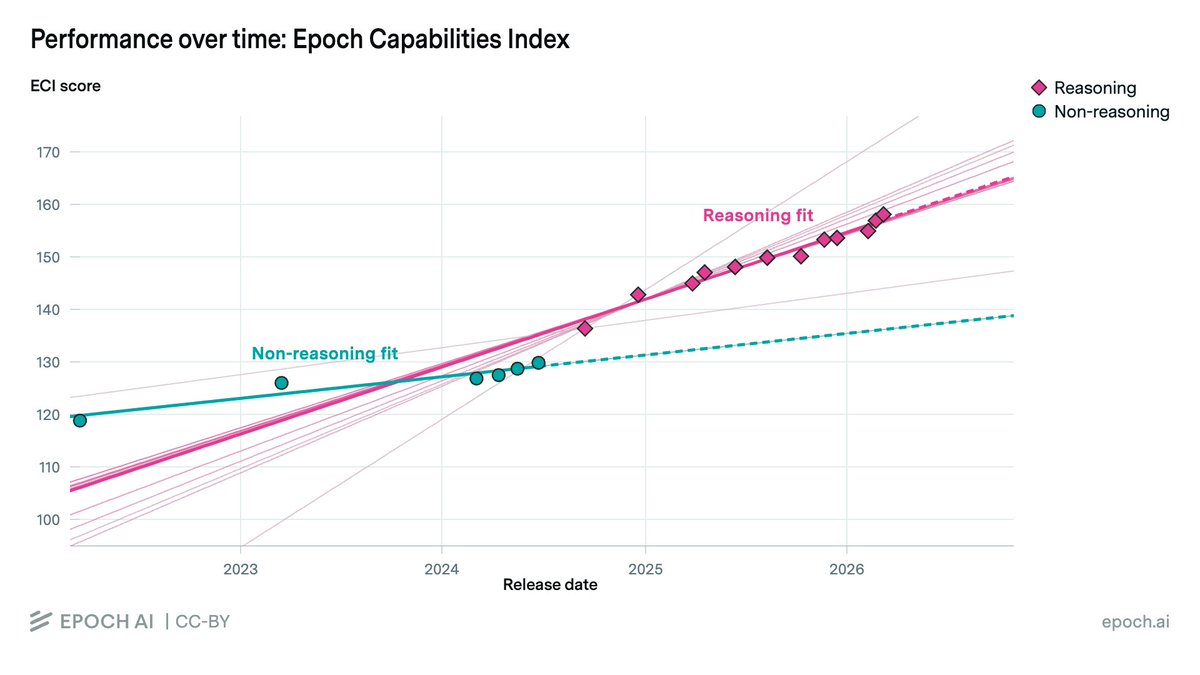
Treating reasoning models as a trendbreak made the best predictions, but not enough data to be very confident.
Have AI capabilities accelerated?
On 3 out of the 4 AI capability metrics we investigated, we found strong evidence of acceleration, around when reasoning models emerged.
Yeah the predictions seem pretty crazy here. I expect people were just unaware of what the current values are? Vs strongly predicting a slowdown.
Looking at the questions they did specify it was asking directly about METR time horizon, but didn't give the current values or trends.
Continuing with tradition I used Opus 4.8's AECI values to predict its METR time horizon: estimated 50% time horizon of 20.0 hours, 80% time horizon of 2.8 hours.
See more details (including why METR's early Mythos Preview results have been misinterpreted) in my post below
Help us produce the most useful work on AI by taking our 5-minute survey: https://t.co/W2tLu3e4WW
(You can sign up at the end to join our compensated user research panel.)
(1) We are likely on track to develop AI systems capable of causing human extinction/permanent disempowerment, quite possibly within the next few years
Excited to announce I am joining @EpochAIResearch as a senior researcher. My remit will include managing the Epoch Capabilities Index, as well as other projects to understand progress trends.
If you have any ideas for improvements/extensions to the ECI please reach out!
I hadn't thought about reproducibility before, it is an interesting idea.
Tracking cost is something I'm very interested to look into in the future (although it isn't totally obvious how to combine it with the current ECI approach), since it is increasingly going to become very clear that spending 1000x more will almost always boost benchmark scores by some amount.
Was fun to work on this as a first application of the domain-specific ECI. I think this (and other) approaches should expand our ability to understand LLM abilities in a more fine-grained way.
Claude is typically better at software engineering and worse at math than frontier competitors.
Aggregating benchmarks to create our domain-specific ECI, we find the Claude family has an average SWE-ECI 2.7 points higher than their general ECI, and a Math-ECI 1.8 points lower.
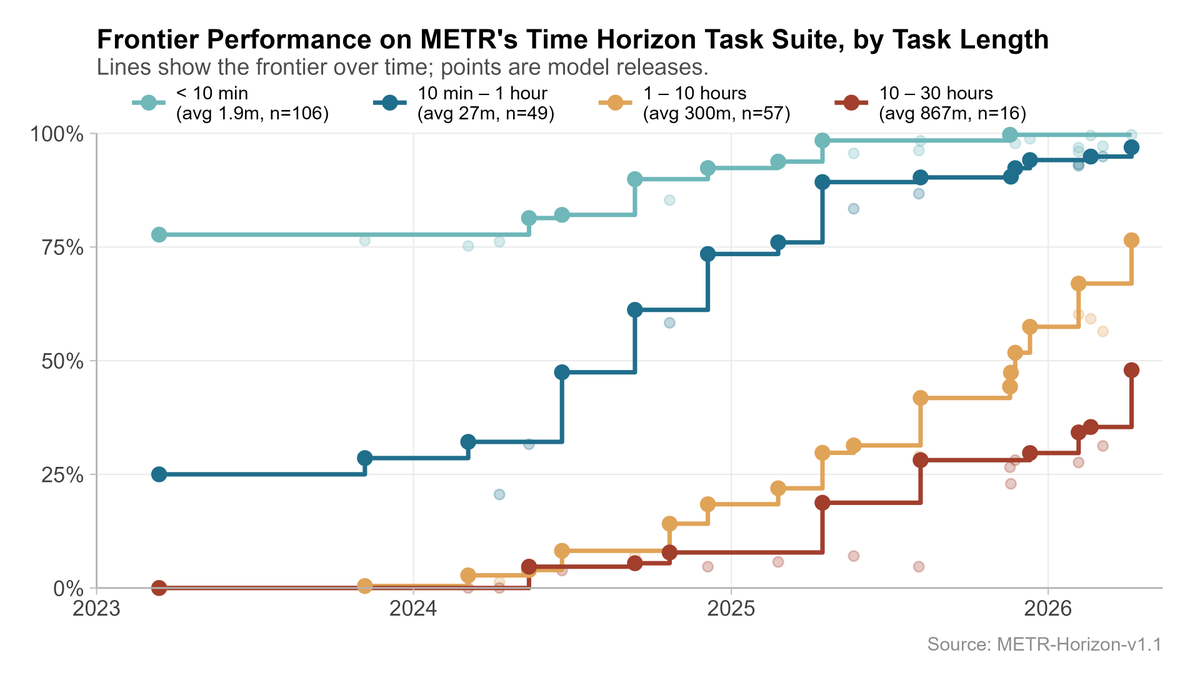
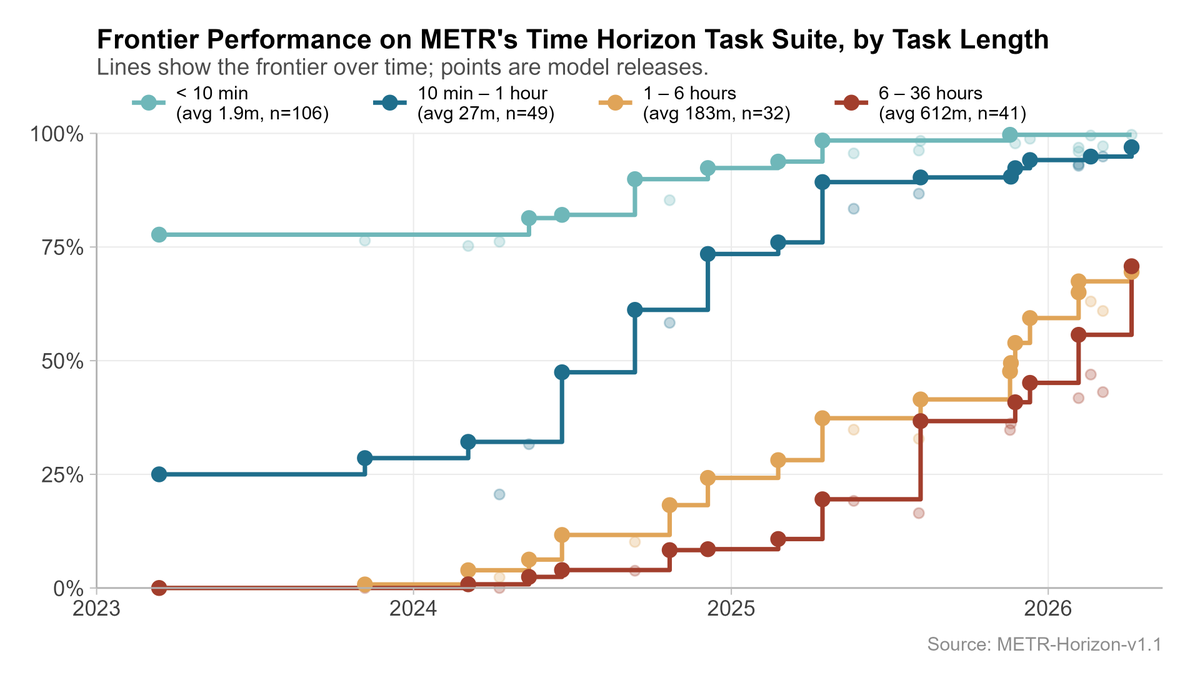
@YafahEdelman Here is my take, I found slightly different buckets more natural (although now we get the weird case where 6-36 hour performance is above 1-6 hours, but this is just what the data actually shows!)
I think (but am not totally sure) that while the METR TH results were based on an early checkpoint of Mythos Preview, the AECI results I used to estimate THs were based on the April 7th launch version.
As per AISIs recent updates the launch version seems notably stronger, so presumably its 80% TH would be higher than the early checkpoint, but I'm not sure by how much.
@YafahEdelman@xeophon Seems correct to me (although I'm not sure if mirrorcode itself was a very big update for me, performance has always varied a lot across different tasks in the time horizon suite, see the messiness stuff in the original paper etc)
@xeophon@YafahEdelman I'd assume the claim is that Mirrorcode tasks are unrepresentative of most real tasks, and that the rest of the TH task suit might similarly be unrespesentative as well.