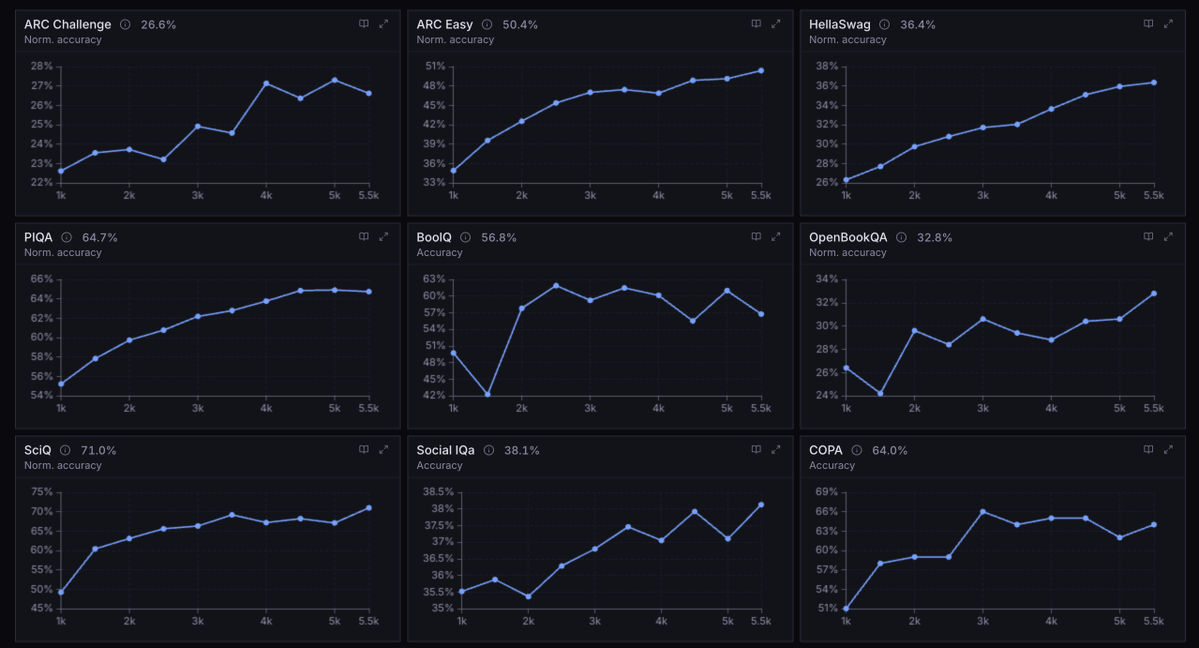
Since I started getting interested in ML I got it in my head that all I wanted to do was one smart thing that I could look back on and be satisfied that I did. Most papers are kinda bad even if they get accepted - the idea is very incremental, or it's just not that good an idea, or it doesn't really matter.
I never was able to do this all through PhD or my time at Amazon. All the papers I did there got into various places, but I never really thought they were actually that good. And I'd pretty much given up on this because Pluralis meant I couldn't really devote enough time to research myself. But in February I decided I didn't care and spend two months focused on a specific problem that had been going round in my head for about a year that I felt we needed to solve, and the solution came to me, and @ChaminHewa picked it up and generalised the approach and ran a bunch of novel experiments I hadn't thought of, and pulled everything together into an actual paper. And yesterday we presented this work at NeurIPS.
This is the first and probably only work I will ever do that for me feels like "ok that was GOOD". I don't care if it racks up a bunch of citations and disperses into the field or not, I don't care if someone repackages the ideas and takes all the credit for it, I don't care. For me there is an internal checkbox that just got ticked after more than ten years of trying. Anyone in ML will understand what I'm trying to say. Special day I'm going to remember for a long time.
@tyleraromero@MicrosoftAI I really like the way you guys wrote the report - no overclaiming, laid everything out clearly etc. etc. Gives me olmo vibes, and is far more valuable than just releasing the weights - thankyou!
One particular aspect of LLM pretraining that often gets under-discussed in research is the fault-tolerance properties of the underlying system. Even in large centralised datacenter settings, tech reports such as Llama-3 or the recent Laguna tech report from Poolside openly talk about the importance of handling device and node failures. For example, Llama-3 training faced about 419 unexpected interruptions, with about half of those related to GPU/HBM/device-class failures one way or another (to understand the magnitude of these failures, that’s a GPU-related issue every 6 hours!).
When running distributed LLM pretraining, fault-tolerance is not a luxury; it’s a necessity. Devices can go offline for various reasons, including workers voluntarily leaving the training stack. In this setting, being able to have a resilient system that continues training without interruption is a massive engineering push, let alone the fact that the entire run is happening in geographically distributed compute.
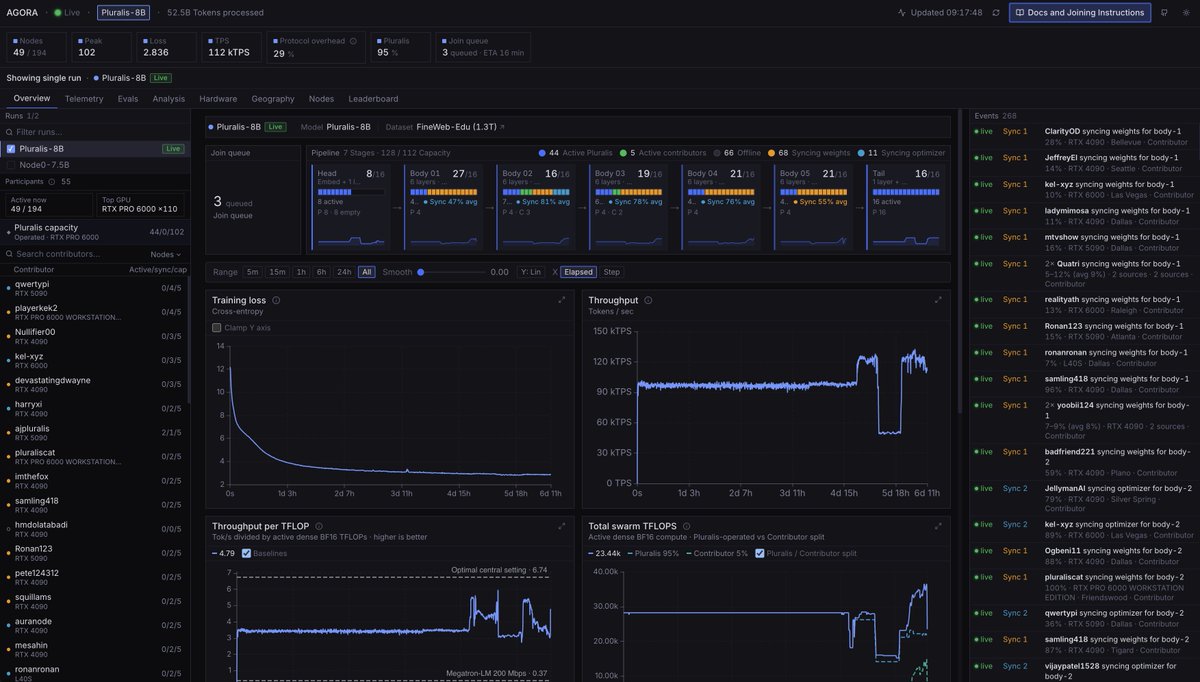
Agora has now been up and running for more than two weeks on prosumer volunteers across North America, with nodes joining/leaving our pretraining run on an almost hourly basis. Despite this churn, training has been going smoothly so far and the training loss continues its downward trajectory at a stable throughput.
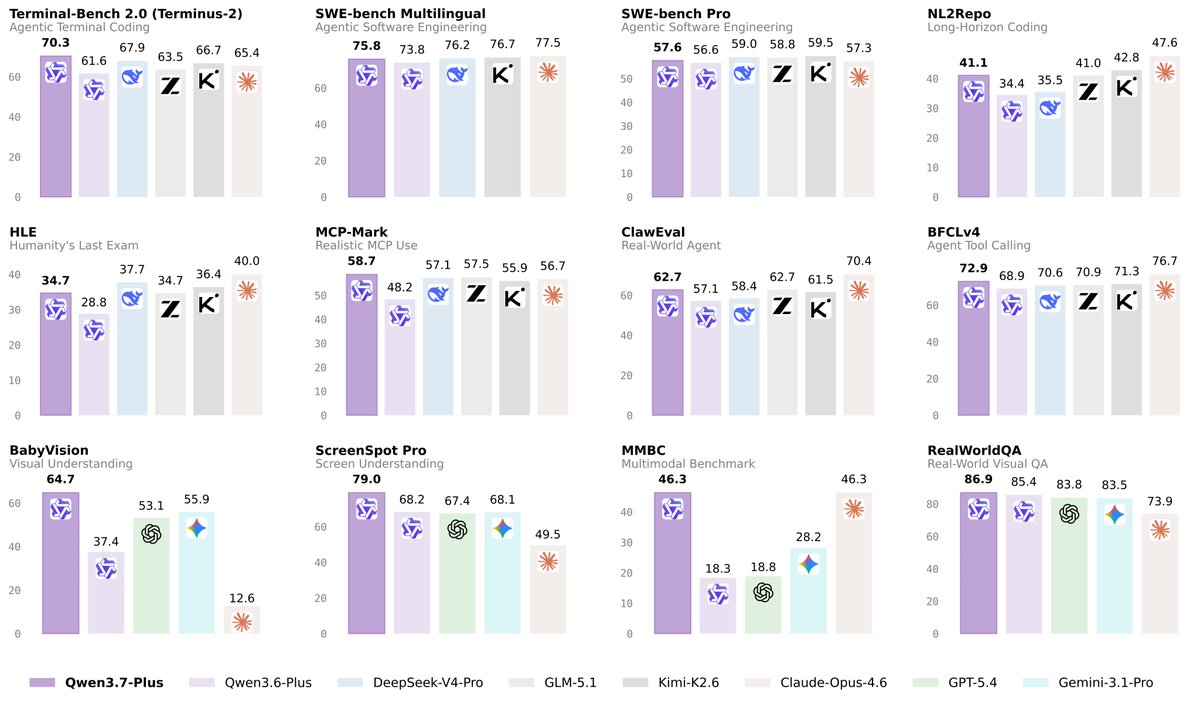
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
The events of the last 6 months in technology are arguable amongst the most important in human history
The tools now increasingly exist for recursive self improvement of models & agents
We are likely in very early lift off & exponential
Largely unnoticed outside of tech
> protocol learning isn't possible
> ok maybe it's possible but it's too expensive <-- we are here
> ok maybe it won't be too expensive but it will never get enough compute
> ok maybe it can get enough compute but you won't have the secret training recipies for large scale runs
> these open large scale runs are irresponsible, unsafe and need to be shut down
Today, among the goods that are universally intended for everyone, we must also include new forms of property, such as patents, algorithms, digital platforms, technological infrastructure and data. In a context where the wealth of nations depends increasingly on knowledge and technology, when these goods remain concentrated in the hands of a few, without adequate forms of sharing and access, a new imbalance is created that contradicts the universal destination of goods. In turn, it widens the gap between the included and the excluded, between those who can participate in the digital revolution and those who remain on the margins. #MagnificaHumanitas
Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters
Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.
Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters
Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.