Martin Scorsese is an advisor to Black Forest Labs.
He's spent six decades shaping how the world sees stories. Now he's helping us shape visual intelligence with human taste and craft at the center.
We sat down with him for a working storyboarding session using FLUX.
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
“The digital world lacks physical information. The physical world lacks dense digital information. Games perfectly merge these two together, and we believe that’s just the next phase of pretraining.”
Every few weeks @gen_intuition ships new emergent capabilities that are orthogonal to anything you see in the LLM world.
Watch GC’s @max_rimpel in conversation with @PimDeWitte.
Chapters
00:00 — Introduction
00:10 — The World's Biggest Private RuneScape Server
03:09 — From RuneScape to Ebola
07:41 — Mapping the Unmappable
09:47 — Why LLMs Can't See the World
13:45 — The Accidental Foundation of General Intuition
19:10 — Turning Down a Life-Changing Acquisition Offer
21:12 — One Foot in Front of the Other
24:04 — Atoms to Atoms
27:33 — The Talent Flywheel
30:20 — Protecting the Last Weird Corner of the Internet
I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools.
With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments.
Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know.
I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars.
(One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.)
There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
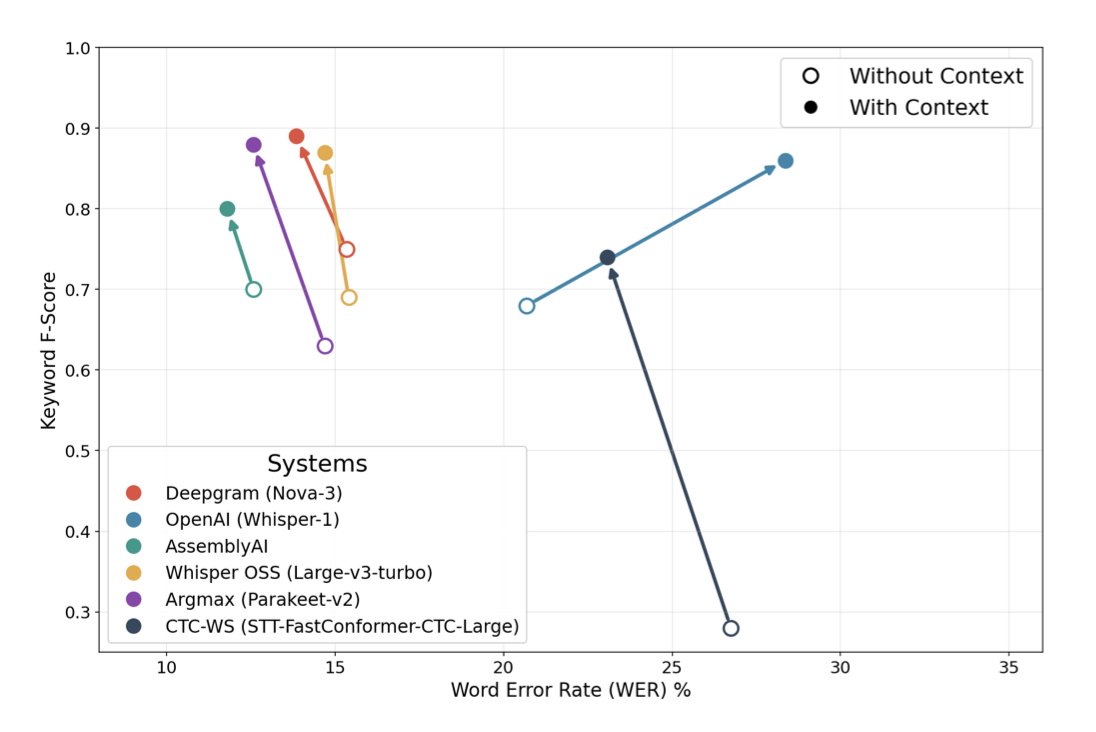
This is what context does to your speech-to-text system!
Our new paper studies the impact of contextual information on the accuracy of leading open-source and proprietary systems.
localhost Ep. 2
Bryan Catanzaro (@ctnzr) on @NVIDIAAI's open models and risky bets
(00:20) Who is Bryan?
(07:38) Getting Nvidia to care about Deep Learning
(14:13) Why did Bryan leave Nvidia right when Deep Learning was taking off
(18:02) Leadership: Aligning a village of researchers
(24:12) Will the frontier flip back to open?
(32:16) Nvidia's models: Side project or core business?
(38:19) Efficiency leads to edge inference: Does Apple capture inference?
(42:43) Nvidia’s risky bets: Fewer and fewer bits
(47:19) Nvidia's misstep with Volta
(52:30) Every model is already obsolete as soon as you stop training it
Why is the 100 ms barrier for Qwen3-TTS (1.7b) this important?👇
Nvidia GPUs scale up amazingly, but they don't scale down well to serving a single user with sub-3b Transformers. They are throughput-maximizers, not latency-minimizers.
@Alibaba_Qwen's Qwen3-TTS paper showed that an optimized vLLM implementation on Nvidia GPUs achieved 101 ms time-to-first-byte latency under idealized conditions: no concurrency and no network round-trip latency.
Argmax TTSKit achieves as low as 70 ms on Apple Silicon Macs in the post below, but the takeaway is not 70 vs 101 ms here.
The takeaway is that, when we move from idealized conditions to the real world:
- Mac will actually serve a single user without an internet round-trip, and the user will experience sub-100ms latency as-is
- Nvidia GPUs will serve many users concurrently in the cloud, resulting in at least 3-5x higher latency. Most importantly, latency will have high variance.
Real-time streaming inference for sub-3b Transformers is where on-device inference is differentiated from cloud, and companies pay the premium for this today.
This is the only commercially relevant market segment where the broadly repeated but rarely substantiated claim of "on-device is faster" actually holds, not running 1T LLMs on 2 Mac Studios.
Two observations:
1. @demishassabis has done more for the UK by demanding DeepMind remain headquartered in London than arguably any Briton in recent decades (never mind all of his other achievements for the world). His actions will single-handedly account for the majority of the UK’s future growth, if the politicians can manage to stay out of the way. What a legend.
2. Sequoia appear to be back and playing aggressively again.
We are open-sourcing TTSKit!
Run state-of-the-art text-to-speech models on your Mac and iPhone.
The launch version supports @Alibaba_Qwen Qwen3-TTS and generates audio faster than real-time playback with sub-200 ms time-to-first-byte.
Voice cloning and advanced speed optimizations will be in the next version. Link to the GitHub repo and models on @huggingface in comments.
Pro tip: When using @superwhisper for AI meeting notes, select Parakeet (voice to text) + Sonnet 4.5 (text to summary) and put all of your company jargon in Vocabulary. Thank me later.
Great piece from my partner @AlexaLiautaud. Devs are only ~1% of the workforce, but code runs the economy. This new era of software developer products treat the remaining ~99% as first-class citizens, and it’s going to put consumers back at the center of value creation
We’ve raised €1.7B to accelerate technological progress with AI!
This Series C funding round, led by @ASMLcompany, fuels Mistral AI scientific research to keep pushing the frontier of AI to tackle the most critical technological challenges faced by strategic industries.