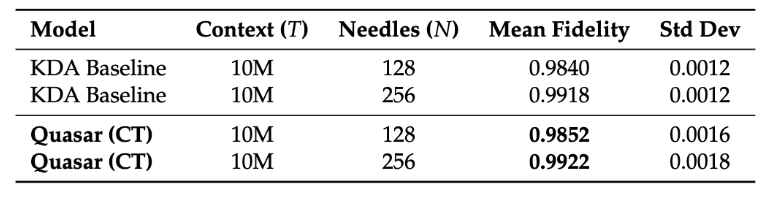
@QuasarModels Interesting! The KDA baseline seems already very strong tho, 99% at 10M context length. Is it the same model as in Table 7 ? Also, would it be possible to have the raw NIAH scores for the two models of Table 7?
@Ji_Ha_Kim uhm I meant in general, even if batch size is not fixed, it disappears in the ratio : mB/mD = (B'/B)/(D'/D) where D'=B'*num_iters and D=B*num_iters_base so the B' and the B cancel
We’ve been lucky enough to test Mamba-3 ahead of the curve. 🧪
Here is how it integrates into Hybrid Models (Spoiler: it unlocks Muon for SSMs for the first time). 🧵
Interesting optimizer that projects the gradient onto a tangent n-dimensional ball on the loss landscape. Unfortunately, the experiments are fairly basic, but i quite like the idea.
🔗https://t.co/cjljvNkWCJ