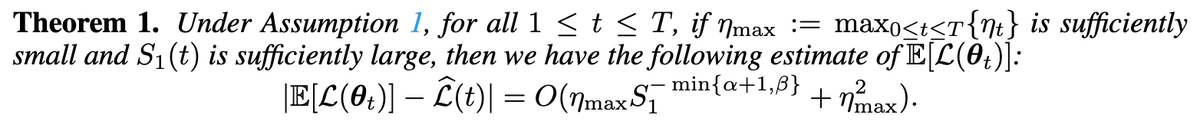Playing with an optimizer speedrun is something that never gets old.
Built on top of https://t.co/n7gbPOCTPT and Claude should take all the credit for hypertl tuning.
I won't be at ICLR this year but @xingyudang will help present Fantastic Optimizers https://t.co/DgKRId21DO!
Stop by at Pavilion 4 P4 5309 this afternoon to see what we have found in extensive sweeping and more importantly, what we learned after the paper that leads to Hyperball!
We find the key issue is learning rate decay.
If you just use a standard LR decay schedule, you’re essentially wasting your best data: high-quality data is only seen at small learning rates.
Instead:
• use a larger ending LR
• or just replace LR decay with model averaging — see our method: Curriculum Model Averaging (CMA)
Paper: https://t.co/TvjQXFqg50
I’m not at ICLR this time unfortunately, but Kairong Luo will be there. Come to our oral talk or stop by the poster!
• Oral: Fri Apr 24, 10:30–12:00 (Room 202 A/B)
• Poster: 3:15–5:45 (P3-#521)
Due to the scarcity of high-quality pretraining data, a natural idea is to design a curriculum: train on low-quality (but abundant) data first, then switch to high-quality data.
Sounds reasonable. But in practice, it often doesn’t work very well. Why is that?
✈️ Heading to ICLR 🇧🇷 Apr 22–27.
Come to our oral on Fri, Apr 24 (10:30 AM–12:00 PM, Room 202 A/B) or find me at our poster (3:15 PM–5:45 PM, P3-#521).
We study why LR decay can hurt curriculum-based LLM pretraining — and how to fix it.
Happy to chat!
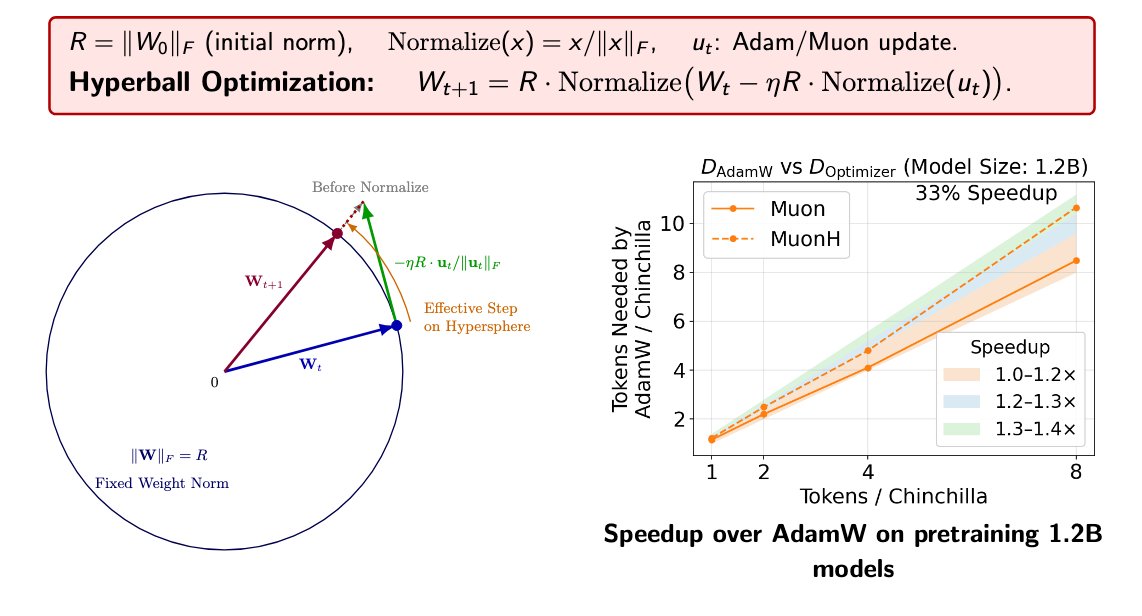
Excited to introduce Hyperball!
This story actually started a few years ago, when Zhiyuan Li (@zhiyuanli_) and I observed that weight decay eventually drives the dynamics toward an equilibrium, in which the parameter norm and the effective (angular) step size stay constant.
https://t.co/NEoqNm4XuN
If that is the case, why not remove weight decay altogether and directly control the norm and effective step size?
(1/n) Introducing Hyperball — an optimizer wrapper that keeps weight & update norm constant and lets you control the effective (angular) step size directly. Result: sustained speedups across scales + strong hyperparameter transfer.
Excited to share our #NeurIPS2025 spotlight!
LLMs train on massive web scrapes + small knowledge-dense datasets. But how much knowledge is learned from this small proportion?
Unlike linear scaling for single domains, we find that data mixing induces phase transitions. (1/3)
📢 Come meet us at #NeurIPS2025!
We'll be presenting our paper: Adam Reduces a Unique Form of Sharpness: Theoretical Insights Near the Minimizer Manifold
🗓️Friday 5 Dec 4:30 p.m. PST-7:30 p.m. PST
👀Exhibit Hall C,D,E Poster Location: #5102
Expect your feedback!
Very good question! Actually, tr(H¹ᐟ²) and tr(Diag(H)¹ᐟ²) are not the same. A key difference is that tr(H¹ᐟ²) is rotational invariant, so it only depends on the eigenvalues of H. In contrast, tr(Diag(H)¹ᐟ²) is not invariant to rotation, just like Adam's training trajectory isn't.
For example, if H = ((2, 2), (2, 2)), then H¹ᐟ² = ((1, 1), (1, 1)) and thus tr(H¹ᐟ²) = 2.
But Diag(H)¹ᐟ² = ((sqrt(2), 0), (0, sqrt(2))), tr(Diag(H)¹ᐟ²) = 2 sqrt(2).
🚀 Our NeurIPS 2025 paper: An SDE-based mathematical characterization of how adaptive gradient methods (e.g., Adam, Shampoo, etc.) implicitly reduce the sharpness of the local loss landscape.
Under label noise, it is known that SGD implicitly minimizes tr(H). We show that Adam implicitly minimizes tr(Diag(H)¹ᐟ²) — a very unique form of sharpness!
In sparse linear regression with diagonal nets, this difference in implicit bias enables Adam to recover the sparse ground truth with much fewer samples than SGD.
👥 Work from our group at Tsinghua, with undergrad intern Xinghan Li @XinghanLi66 and first-year PhD student Haodong Wen @herrywen1.
Adam prefers a different minimizer than SGD (exemplified below), but how? 🤔
Our NeurIPS 2025 Paper: Based on our Slow SDE approximation of Adam, we show that under label noise Adam implicitly minimizes tr(Diag(H)^½), whereas prior works showed that SGD minimizes tr(H).
🧵1/n
Excited to share our new method ✏️PENCIL! It decouples space complexity from time complexity in LLM reasoning, by allowing model to recursively erase and generate thoughts.
Joint work w. my student @chenxiao_yang_ , along with @BartomNati and @McAllesterDavid.
Excited to present our paper this morning at ICLR 2025, revealing the gap in CoT reasoning between RNNs and Transformers!
Poster Presentation:
🗓 Saturday, April 26
📷 10:00 AM – 12:30 PM
📍 Hall 2, Poster #640
Check out our new paper! We explore the representation gap between RNNs and Transformers. Theory: CoT improves RNNs but is insufficient to close the gap. Improving the capability of retrieving information from context is the key (e.g. +RAG / +1 attention). https://t.co/LojGoxdhVd
What's the optimal learning rate schedule for LLM pretraining?
Come meet us this afternoon!
Poster Presentation:
🗓 Friday, April 25
🕒 3:00 PM – 5:30 PM CST
📍 Hall 3 + Hall 2B, Poster #237
📢 Come meet us at #ICLR2025!
We'll be presenting our Multi-Power Law — a new approach to predicting full pretraining loss curves across LR schedules — during the poster session:
🗓 Friday, April 25
🕒 3:00 PM – 5:30 PM CST
📍 Hall 3 + Hall 2B, Poster #237
Expect your feedback!
Thrilled to share that our paper “Safety Alignment Should be Made More Than Just a Few Tokens Deep” has received an ICLR 2025 Outstanding Paper Award!
This project began as an effort to defend against fine-tuning attacks with constrained supervised fine-tuning (SFT). Along the way, we found that one important trick is to constrain the first few tokens somehow so that their logits are preserved better after fine-tuning. Is it just a technical trick? We later recognized that the effectiveness of this trick, and the success of many jailbreak methods, reveal a deeper issue in the current alignment method: it primarily adapts the base model’s generative distribution only over the very first few output tokens to induce a basic refusal response. We call this shallow safety alignment.
This insight motivated us to further ask: What if the safety alignment were deeper? We proposed a data augmentation approach to make alignment deeper and demonstrated promising improvements for mitigating multiple vulnerabilities.
We hope this work provides useful insights for future alignment research. Huge credit to our first author, Xiangyu Qi (@xiangyuqi_pton). Let me also forward his tweet, which gives a great summary of our journey and shares many deep insights. I honestly can’t write anything better than that.
Also grateful to work with other amazing collaborators!
@PandaAshwinee@infoxiao@sroy_subhrajit@abeirami@prateekmittal_@PeterHndrsn
Thrilled to know that our paper, `Safety Alignment Should be Made More Than Just a Few Tokens Deep`, received the ICLR 2025 Outstanding Paper Award.
We sincerely thank the ICLR committee for awarding one of this year's Outstanding Paper Awards to AI Safety / Adversarial ML. Special thanks go to the reviewers and area chairs for their strong support and recommendations. Throughout the rebuttal period, the reviewers remained deeply engaged, raising thoughtful questions that helped enhance the rigor of our experiments and manuscript. I am also profoundly grateful to my collaborators (@PandaAshwinee@vfleaking@infoxiao@sroy_subhrajit@abeirami) for their joint efforts and my advisors (@prateekmittal_@PeterHndrsn) for their invaluable guidance and support.
+ On a personal note, I also defended my PhD at Princeton in February and joined OpenAI last month, where I will continue working on AI safety and adversarial robustness. I'm looking forward to catching up with old friends and meeting new friends around the Bay!)
------
Below are some of my reflections and thoughts on our awarded paper:
Adversarial robustness has been an ongoing topic since the early rise of deep learning in 2013 (https://t.co/Squ5sX8GCz). Over the years, we've observed the community swing from pessimism—epitomized by Nicholas Carlini's adaptive attacks (https://t.co/EE9O5aLcRd) systematically dismantling various defenses, fostering the sentiment "adversarial examples are hard"—to skepticism, as adversarial examples appeared to have limited impact on practical AI applications for a while, prompting the notion "adversarial examples are not even important."
With the emergence of ChatGPT at the end of 2022, deep learning entered a new era towards AGI, shifting AI safety from theoretical speculation to mainstream practical concern. This is also when adversarial robustness again gets more attention. For example, following our 2023 demonstrations that adversarial examples pose fundamental threats to AI safety alignment (https://t.co/WZM7wfYqa3, https://t.co/g7IQA8D1nY, https://t.co/e5jOcIvFzU), adversarial examples reemerged as the "Sword of Damocles" hanging over AI safety (memorably illustrated by Zico Kolter at ICML 2023 in Hawaii, who humorously preempted his talk on the GCG attack with a Terminator slide captioned, "adversarial examples are back"). More concerningly, in the context of AI safety, disrupting safety alignment through fine-tuning is even simpler and harder to mitigate than adversarial examples (https://t.co/P9o5KGH9mM, https://t.co/2D0HYXcnCb, https://t.co/gH8wW6Nx9V, https://t.co/PK1nlICXzo, https://t.co/jrqD8XQfxB).
In 2023, conducting attack research was enjoyable—simply formulating and demonstrating the existence of vulnerabilities sufficed, as the effectiveness of an attack is inherently compelling. However, in 2024, my advisors started to heavily push me toward working on robustness defense, asserting that identifying problems without striving for solutions is not ambitious enough. While I wholeheartedly agreed, I was acutely aware of the profound challenge in achieving genuine robustness. After a lot of struggle, we eventually still developed this paper. Initially, our exploration focused on constrained supervised fine-tuning (SFT) against fine-tuning attacks. During this process, we discovered a critical bias—models exhibit substantial "first-few-tokens bias" concerning safety (here we acknowledge similar findings by https://t.co/irDKwTmsNb and https://t.co/ZceJPx37yg, despite differences in our ultimate directions). Using this bias as a technical trick, we impose strong constraints on the losses of only the initial tokens, relaxing constraints for later tokens. This achieved robustness with significantly lower utility regression. Nevertheless, we soon recognized that this bias is not merely a technical trick but represents a fundamental issue. Consequently, we shifted our focus to exploring the broader implications of this phenomenon itself, ultimately shaping the current paper. In writing this paper, I intentionally echoed the style of two seminal works: "Adversarial Examples Are Not Bugs, They Are Features" (https://t.co/lOmPqbo6B3) and "Shortcut Learning in Deep Neural Networks" (https://t.co/IdeWjpNygQ). The two papers deeply influenced my research style, and receiving the Outstanding Paper award at the culmination of my PhD journey, using a similar writing style, feels both fulfilling and like a tribute to these classics.
Frankly, our work still stands far from fully resolving adversarial robustness. In fact, during writing, we deliberately reduced/avoided using the term "defense," resulting in some critique that our paper reads more like a position paper. Rather, our contribution primarily provides just a simple yet concrete explanation (shallow alignment) for a broadly exploited class of vulnerabilities, enabling causal interventions on models to explore the counterfactual of shallow alignment—deep alignment—and demonstrating that such interventions genuinely improve robustness. Fundamentally, our intervention underscores that model alignment must span the entire generation process rather than being confined to the first few token distributions—a principle articulated explicitly in our paper's title. This concept resonates with several other studies, such as Andy Zou et al.’s Circuit Breakers (https://t.co/ul9h7tWVXC), Youliang Yuan et al.’s refusal at every position (https://t.co/DEOBQpOF3i), and Yiming Zhang et al.’s backtracking (fri). To some extent, improved robustness in reasoning models’ safety alignment (https://t.co/F4fNc7BLOu) might also be related to this principle, as large-scale reinforcement learning for reasoning spontaneously enhances self-correction and recovery.
Yet, adversarial robustness remains unresolved. Adaptive attacks will continuously emerge, potentially perpetuating many cycles of a cat-and-mouse game again. Furthermore, our challenges extend beyond AI safety and jailbreak issues. As frontier models rapidly advance in agentic capabilities, we eagerly anticipate their large-scale deployment to automate numerous tasks. However, currently, robustness and prompt injection significantly hinder this vision. As AI increasingly manages critical workloads and computational systems, robustness failures could pose severe systemic security risks.
Finally, we again extend our sincere appreciation to all friends in the AI safety and AdvML research communities for their ongoing support and encouragement. Let’s continue working together to advance the research on AI safety and adversarial machine learning.
We will present this paper at #ICLR2025!
1. 𝐎𝐫𝐚𝐥 𝐒𝐞𝐬𝐬𝐢𝐨𝐧 𝟏𝐃 (𝐓𝐡𝐮𝐫𝐬𝐝𝐚𝐲 𝟏𝟎:𝟒𝟐𝐚𝐦)
@PandaAshwinee will give a talk
2. 𝐏𝐨𝐬𝐭𝐞𝐫 𝐒𝐞𝐬𝐬𝐢𝐨𝐧 𝟒 (𝐅𝐫𝐢𝐝𝐚𝐲 𝟑𝐩𝐦)
Come to chat with @PandaAshwinee@vfleaking@infoxiao@abeirami
Unfortunately, I won’t be at Singapore in person. But my DM is always open :)
The success of RLHF depends heavily on the quality of the reward model (RM), but how should we measure this quality?
📰 We study what makes a good RM from an optimization perspective. Among other results, we formalize why more accurate RMs are not necessarily better teachers!
🧵
Joint work with Tsinghua talents Kairong Luo @openhonor, Shengding Hu @DeanHu11, Zhenbo Sun @BranSun10, and my incoming PhD student Haodong Wen @herrywen1—already doing great research! Enjoyed collaborating with Professors Zhiyuan Liu @zibuyu9, Maosong Sun, and Wenguang Chen!
Can we quantify the effect of learning rate schedules? Empirically, what's the best schedule for LLM pretraining?
🚀Excited to share our ICLR paper! https://t.co/wUENLTSqEn
With ≤3 runs, you can fit our empirical law and optimize your schedule—a WSD-like schedule is the best!
🔍How does pretraining loss evolve under different LR schedules?
🌟Meet our Multi-Power Law: predicts the full loss curve for various schedules!
🌟Accurate enough to optimize LR schedules directly.
🌟Result? A WSD-like schedule that outperforms the rest!
🔥Accepted at #ICLR2025
Does our empirical formula look weird to you? Even when optimizing a quadratic loss with SGD, the expected loss has to take such a complex form.
Check out Section 4 of our paper for details. Happy to chat more about the theory!