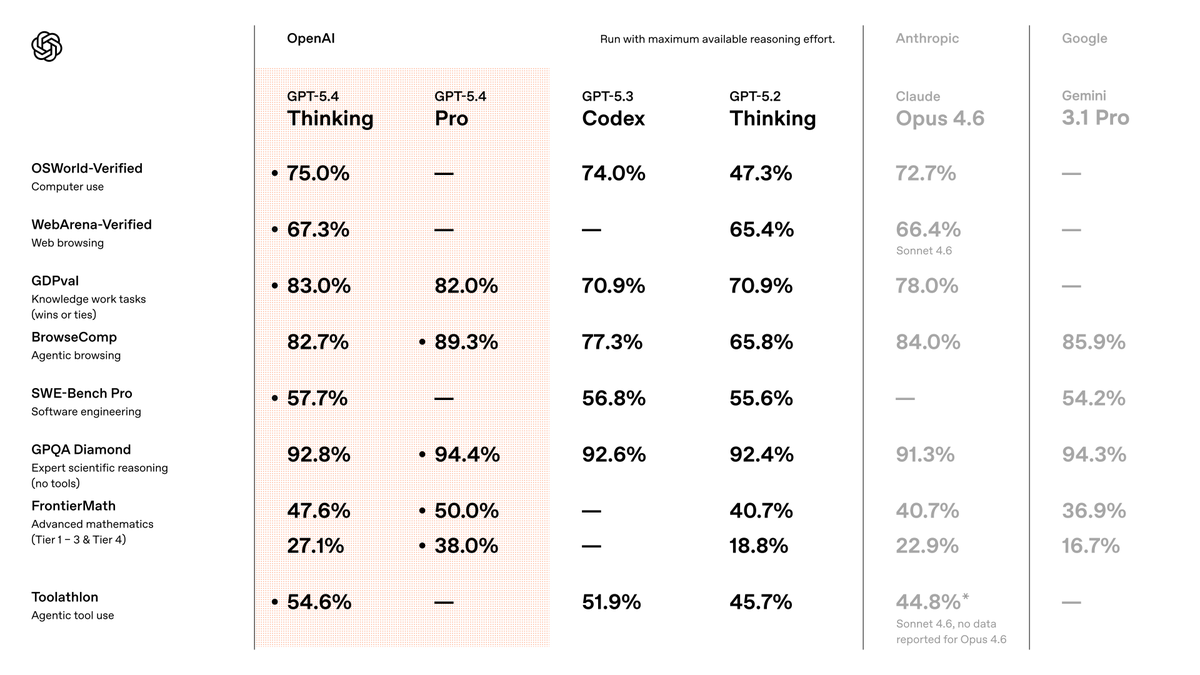
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model.
Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models.
We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising.
We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a .
This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement.
We are looking forward to more controlled evaluations in the next round!
https://t.co/jtLCOhJftv #1stProof
🧄GPT-5.2 is here – one small step on version number, one giant leap in capabilities. 🚀
With *incredible* @Song__Mei@yaodong_yu@Yuf_Zh@ofirnachum and rest of the @OpenAI team, we applied new techniques to bring our frontier reasoning model to the next level. GPT-5.2-Thinking is much stronger on intelligence, agentic coding, professional use, long-context understanding, and extended thinking.
It’s also better on science/theory research – try pairing with it!
Congrats also to @yanndubs@ericmitchellai @.ishaan @christinahkim, and heartfelt thanks to the leadership @_aidan_clark_@max_a_schwarzer@markchen90@merettm@sama for making this come together!
When and why can AI be trusted to make decisions in the high stakes settings where it can have the most value?
The @DARPA Artificial Intelligence Quantified (#AIQ) program kicked off before the holiday, aiming to developing mathematical foundations for AI evaluation.
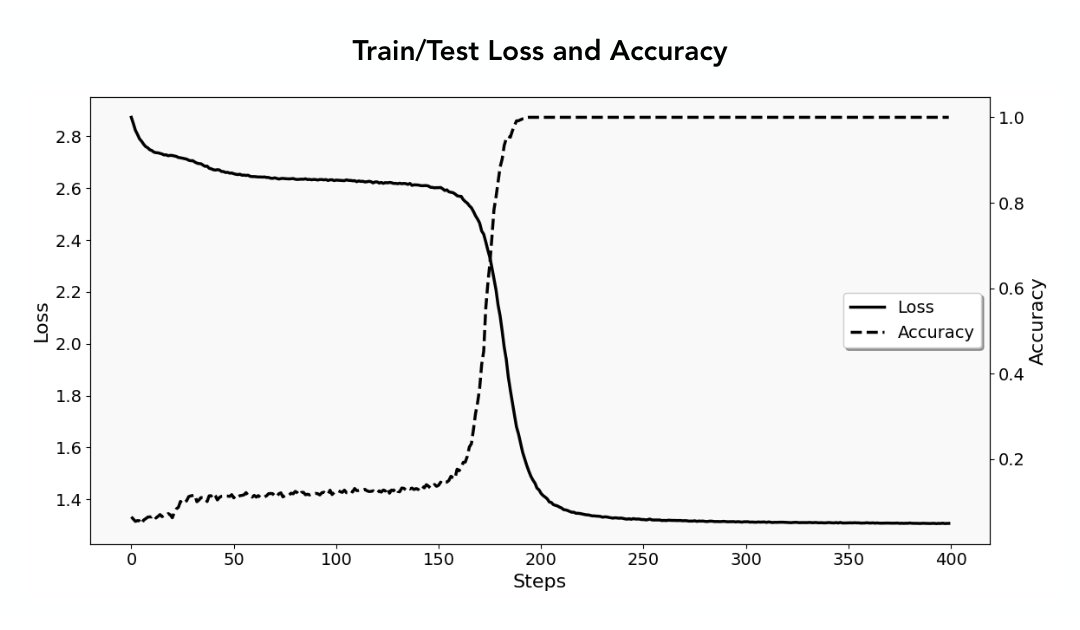
What happens behind the "abrupt learning" curve in Transformer training? Our new work (led by @GopalaniPulkit) reveals universal characteristics of Transformers' early-phase training dynamics—uncovering the implicit biases and the degenerate state the model gets stuck in. ⬇️
I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
https://t.co/1kN7XneMlY