✈️ Heading to ICLR 🇧🇷 Apr 22–27.
Come to our oral on Fri, Apr 24 (10:30 AM–12:00 PM, Room 202 A/B) or find me at our poster (3:15 PM–5:45 PM, P3-#521).
We study why LR decay can hurt curriculum-based LLM pretraining — and how to fix it.
Happy to chat!
🙏 Great honor to collaborate with @BranSun10, @Dunk_KD1998, @Harry_Chen_, with advice from Professor Kaifeng Lyu @vfleaking, and under the support and leadership of Professor Wenguang Chen.
Thanks to all contributors who made this work possible!
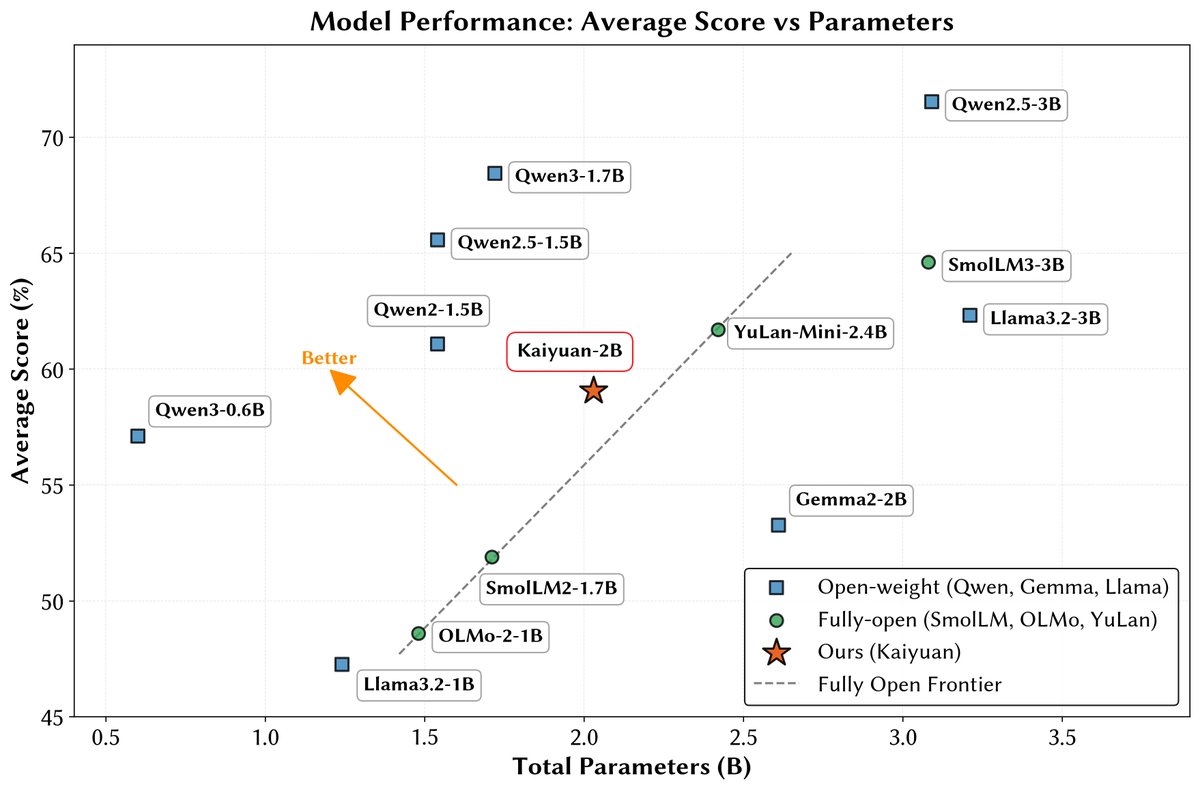
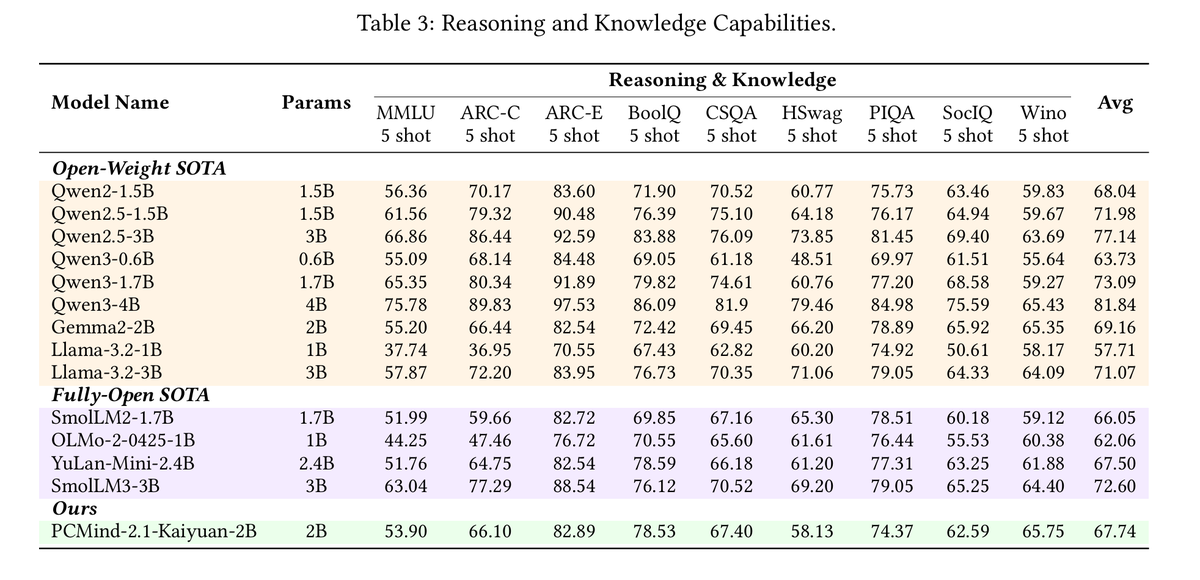
🚀 Announcing PCMind-2.1-Kaiyuan-2B
A new frontier for fully open-source models.
Not just weights—full pretraining pipeline & recipe.
Specs: 2B params, 2.2T tokens
Approach: data-centric pretraining
Status: SOTA among fully-open models
🤗 HF: https://t.co/G86k7ja08P
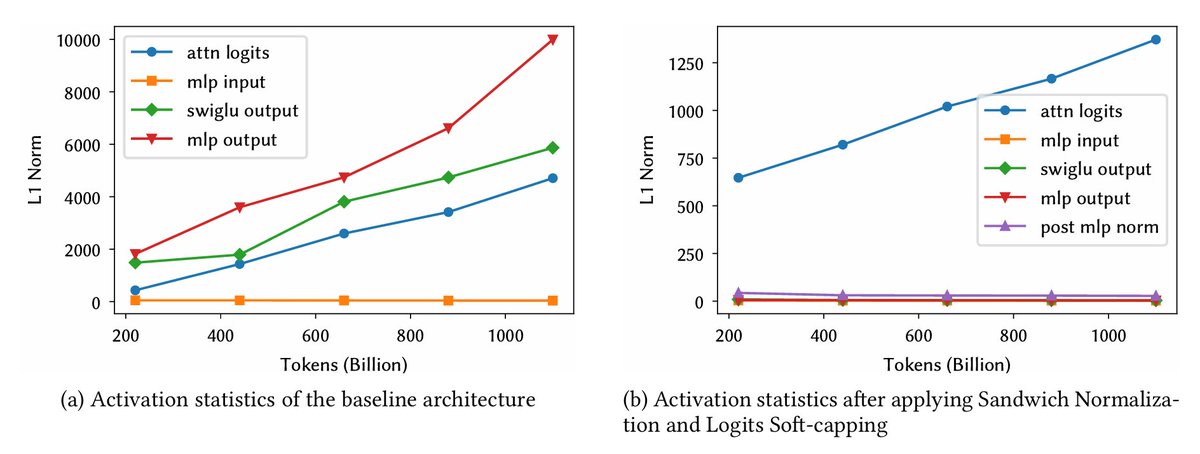
⚙️ Infrastructure: Kaiyuan-Spark
Built on Spark & Chukonu (https://t.co/8ZSX4EJcti) for scale.
- Capabilities: Massive deduplication & mixing.
- Speed: Optimized C++ kernels.
- Reproducibility: Reconstruct our exact training set via config files.
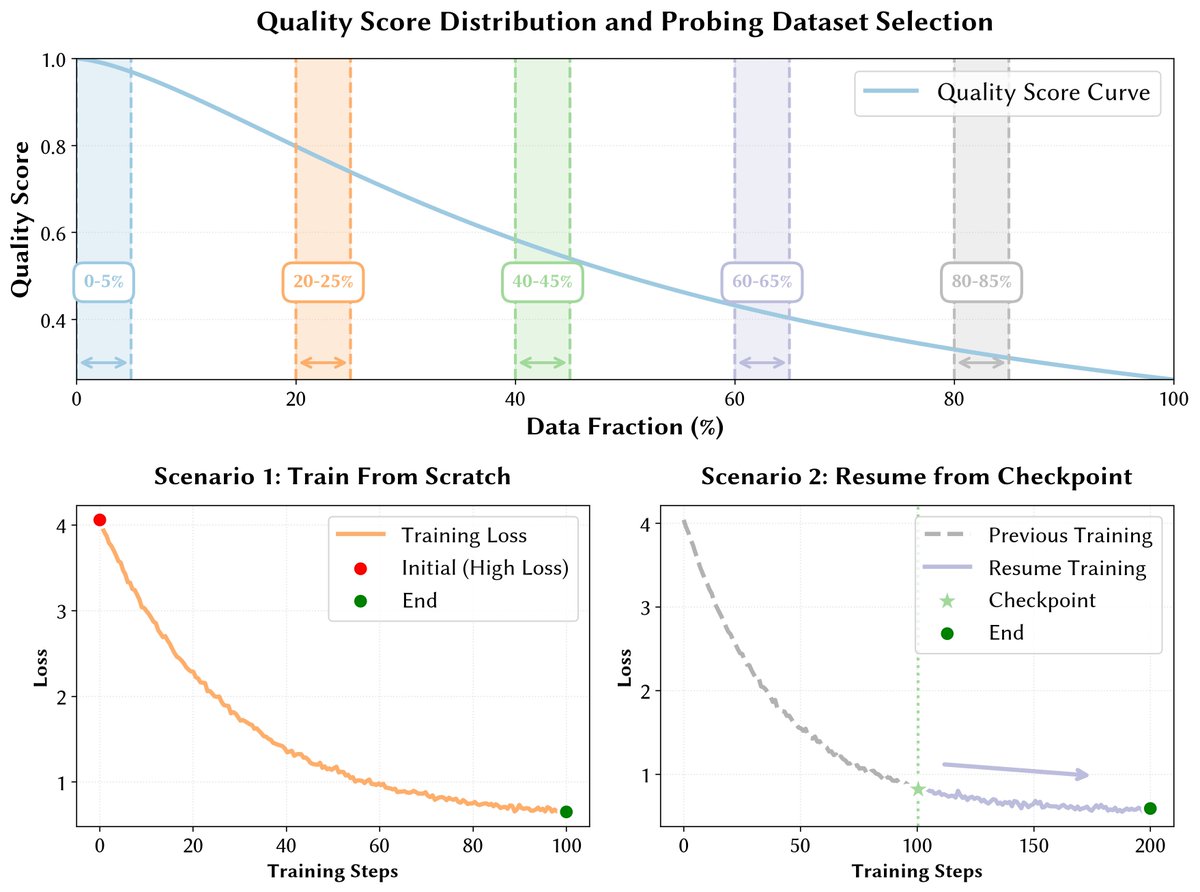
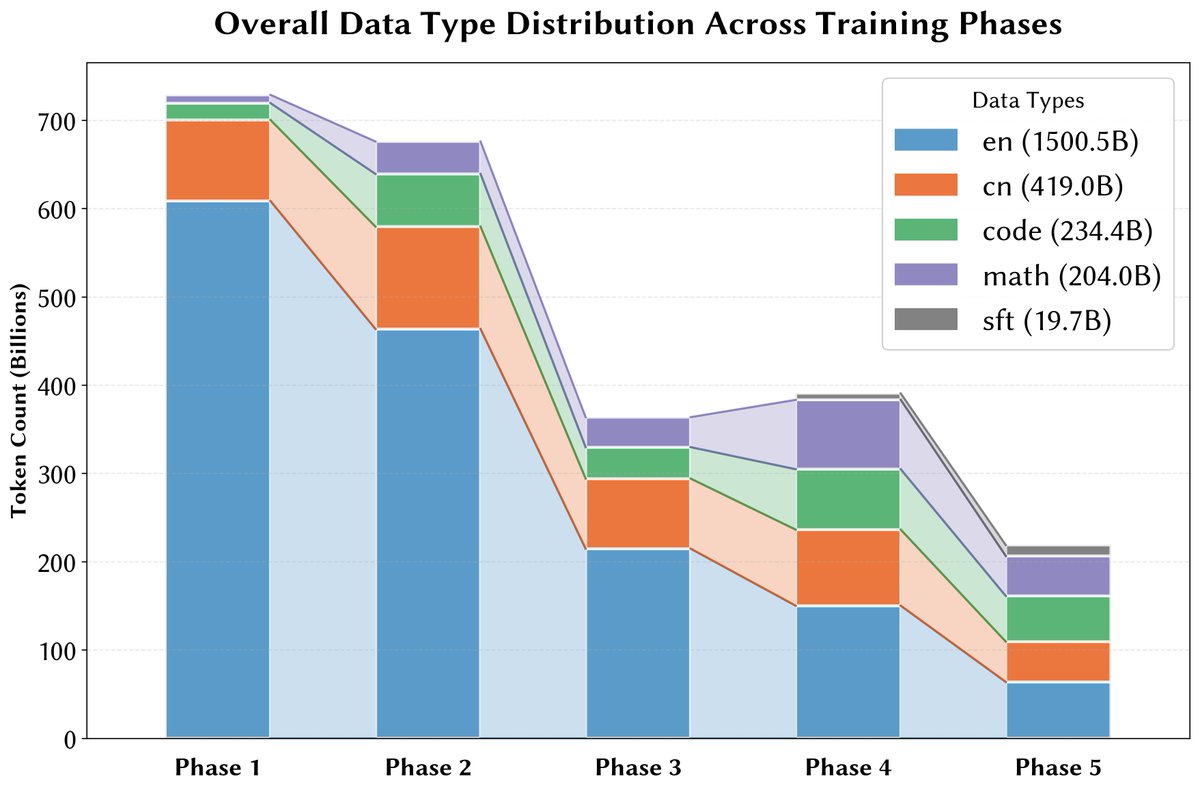
📈 Innovation 3: Quality Curriculum
Samples sorted by quality (ascending), then interleaved globally.
- Progressive Exposure: Model sees "textbook quality" data only when mature.
- Stable Mix: Domain ratios (Chinese/Code/Math) remain fixed while quality ramps up.
🔄 Innovation 2: Strategic Repetition
High-quality data is finite. We use a multi-phase approach to repeat the best data without overfitting.
Method: Retain top 50% → 30% → 10% in later phases.
Result: Top 10% samples seen 4x; low-quality samples seen only once.
🧐Challenge: Heterogeneity & Scarcity
Open datasets (DCLM, FineWeb) are great but vastly different. High-quality tokens are potent but rare.
How to compare/mix heterogeneous sources?
How to max efficiency with sparse "gold" data?
Focus on these and run data-centric training.👇
📢 Come meet us at #ICLR2025!
We'll be presenting our Multi-Power Law — a new approach to predicting full pretraining loss curves across LR schedules — during the poster session:
🗓 Friday, April 25
🕒 3:00 PM – 5:30 PM CST
📍 Hall 3 + Hall 2B, Poster #237
Expect your feedback!
🔍How does pretraining loss evolve under different LR schedules?
🌟Meet our Multi-Power Law: predicts the full loss curve for various schedules!
🌟Accurate enough to optimize LR schedules directly.
🌟Result? A WSD-like schedule that outperforms the rest!
🔥Accepted at #ICLR2025
📢 Come meet us at #ICLR2025!
We'll be presenting our Multi-Power Law — a new approach to predicting full pretraining loss curves across LR schedules — during the poster session:
🗓 Friday, April 25
🕒 3:00 PM – 5:30 PM CST
📍 Hall 3 + Hall 2B, Poster #237
Expect your feedback!
🔹 Using predicted final loss as a surrogate objective, we induce an optimized schedule—matching WSD (Hu et al., 2024) in shape but achieving even lower loss!
🔍How does pretraining loss evolve under different LR schedules?
🌟Meet our Multi-Power Law: predicts the full loss curve for various schedules!
🌟Accurate enough to optimize LR schedules directly.
🌟Result? A WSD-like schedule that outperforms the rest!
🔥Accepted at #ICLR2025
💡 Results at a glance:
🔹 Our law is fitted on the schedules in the first row—then accurately predicts loss curves for unseen schedules in the second row!