Very excited to support the release of Cohere Transcribe, available with a fully open license.
One more step towards making breakthroughs accessible to people worldwide. 🌏
4 Days Left to Join Expedition Tiny Aya! 🚀
Here’s what you need to know:
🌟 Join a team or pitch your own idea — Connect with like-minded researchers and mentors.
🤝 Get hands-on support — 20+ research mentors from Cohere and Cohere Labs are ready to guide your project.
💡 Explore 20+ project ideas — Spark your creativity and contribute to impactful open science.
Learn more and join a team before March 8th: https://t.co/a13GRWyuo1
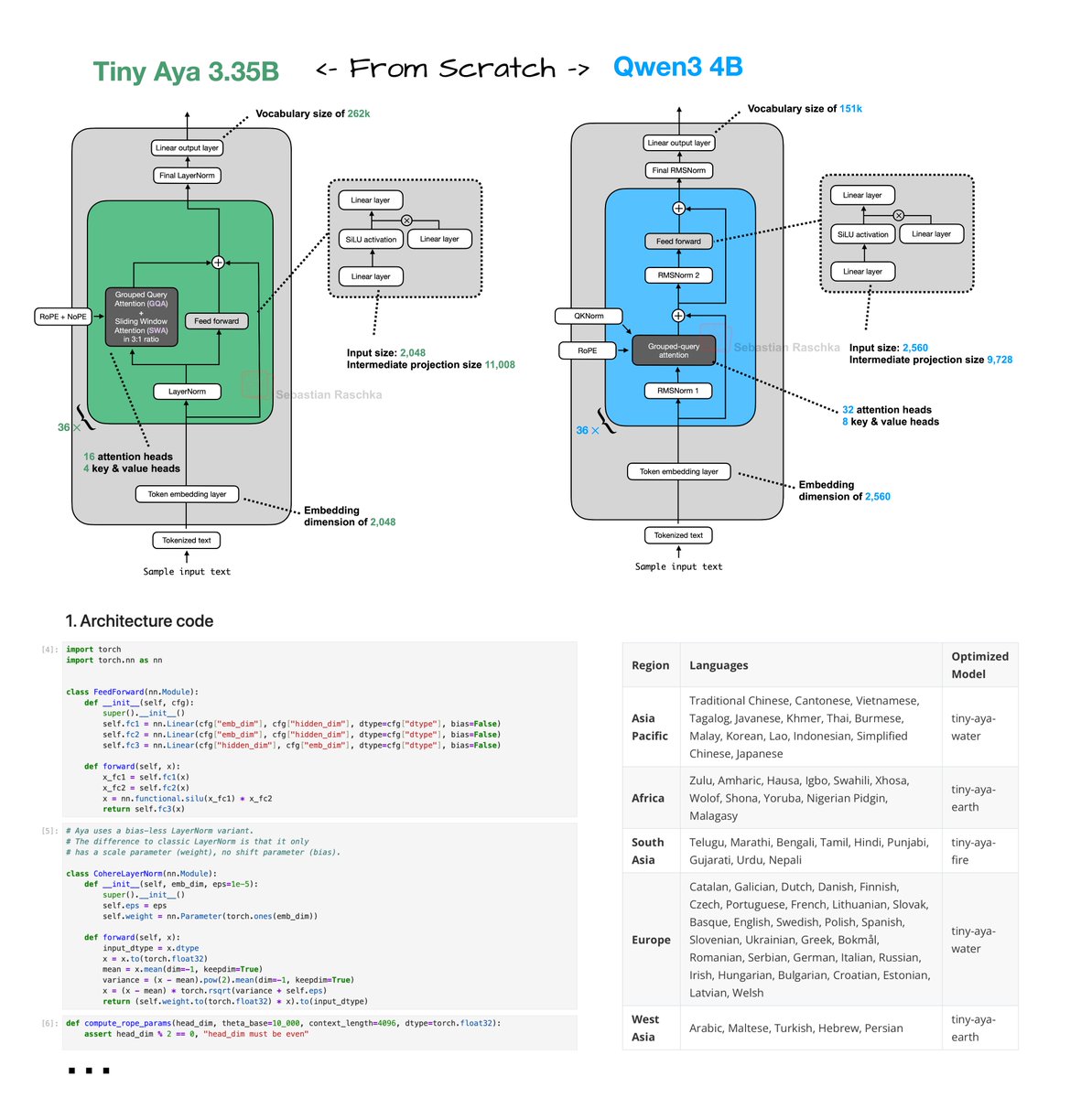
Tiny Aya reimplementation From Scratch!
Have been reading through the technical reports of the recent wave of open-weight LLM releases (more on that soon).
Tiny Aya (2 days ago) was a bit under the radar. Looks like a nice, small 3.35B model with strongest multilingual support of that size class. Great for on-device translation tasks.
Just did a from-scratch implementation here: https://t.co/6KEV0DfVQu
Architecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention):
1. Parallel transformer blocks. A parallel transformer block computes attention and MLP from the same normalized input, then adds both to the residual in one step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput.
2. Sliding window attention. Specifically, it uses a 3:1 local:global ratio similar to Arcee Trinity and Olmo 3. The window size is also 4096. Also, similar to Arcee, the sliding window layers use RoPE whereas the full attention layers use NoPE.
3. LayerNorm. Most architectures moved to RMSNorm as it's computationally a bit cheaper and performs well. Tiny Aya is keeping it more classic with a modified version of LayerNorm (the implementation here is like standard LayerNorm but without shift, i.e., bias, parameter).
Cohere just released 🌿 Tiny Aya, a fully open-source 3B model that speaks 70+ languages. But there’s a catch!:
No agent capabilities. Is it hard to turn Tiny Aya into an agent?
Here'e a hands-on guide to train it and get the first massively multilingual open agent.
Link below
@TomGorse@pepicrft@SimonHoiberg Spain has many flaws and things to improve for sure, but for the shake of a healthy, constructive conversation, calling everything we find slightly annoying a “third world country” thing does not help. I guess you’ve never been to a third world country.
We're hiring a Research Engineer who understands models at a deep technical level and excited to take responsibility across the full lifecycle.
If you're excited to join a small team driving research with real-world impact, we'd love to hear from you.
https://t.co/2Jdf2GEWcL
Cohere Labs just released Tiny Aya on Hugging Face: a collection of 4 open-weight multilingual LLMs optimized for over 70 languages.
At just 3.35B parameters, they are perfect for on-device use cases, and can even run 100% locally in your browser on WebGPU!
Try out the demo! 👇
Tiny Aya 🌿 just dropped from @Cohere_Labs, a really powerful multilingual small model!
To celebrate, we cooked up fresh resources to train it for tool calling 🔧
> Free Google Colab guide
> Standalone training script
@RicardoMonti9@agcrnz@KaleighMentzer Really interesting work! 👏 And thanks for including Tiny Aya, that was fast!
I’m curious about why you chose tiny-aya-base and not one of the instruction tuned models such as tiny-aya-global? Thanks!
Working on Tiny Aya has been incredibly rewarding, fun, and insightful. I hope this tiny model can make a huge impact and bring AI to more people, in their native languages.
Let's keep exploring ✨
Introducing ✨Tiny Aya✨, a family of massively multilingual small language models built to run where people actually are.
Tiny Aya delivers strong multilingual performance in 70+ global languages in a 3.35B parameter model, efficient enough to run locally, even on a phone.