Five years ago, I left a comfortable software engineering job in Big Tech to start a PhD. Last year, I left the PhD to join Datology. Both decisions confused the people around me, and honestly both decisions were about the same thing: I wanted to do research. Not research as in chasing paper deadlines and applying for fellowships / grants, but research in the truest sense of the word - sitting with unsolved, sometimes previously unheard-of problems, contextualizing them, formulating them, exploring solutions to them.
I'd had a taste of research in college, flitting between disciplines, but never found something I felt truly passionate about until I came across deep learning. A field mixing empiricism, mathematics, and real-world impact all seamlessly - it made research the most exciting thing I'd ever done in my life. So in 2022 I started my PhD hoping for the chance to explore uncharted frontiers. Three years and several papers at the standard prestigious ML conferences later, I had technically done research. But I still didn't feel like I'd ever had the freedom, support, and resources to explore new and exciting ideas.
This is what brought me to Datology as an intern last summer. A hope to do research in the true sense - explore new ideas, supported by my peers and leaders, unconstrained by resources. And of course, about the data. At the end of the summer, I took a risk and stayed, putting my PhD on hold.
Since then, I've been lucky enough to grow into leading multimodal data curation at DatologyAI, and with our team we've tackled every challenge possible: the engineering and optimizing of a VLM training stack we built from scratch; the at-times frustrating but ultimately rewarding deep refining of VLM evals in our work DatBench (link); and of course a lot of exhilarating new research on DATA CURATION. But more than anything, I felt like I finally got to do research!!
I'd like to specifically thank @arimorcos and @leavittron who entrusted me with this opportunity, empowered me to do the best work of my life (so far), and mentored me to grow not only as a researcher but also as a leader. And a huge thanks to the @datologyai team that made research feel FUN again.
Today, we're releasing 20/20 Vision Language Models: A Prescription for Better VLMs through Data Curation Alone. This is the culmination of the multimodal team at Datology's work over the past year.
At fixed architecture, recipe, and compute, varying only the pretraining data, we get +11.7pp at 2B across 20 public VLM benchmarks, beat InternVL3.5-2B by ~10pp at ~17x less training compute (without post-training), and hit near-frontier accuracy at 4B with 3.3x lower response FLOPs than Qwen3-VL-4B.
Take risks. Bet on yourself. I’m going to keep doing this. At least until my luck runs out :)
a 🧵
Models are typically specialized to new domains by finetuning on small, high-quality datasets.
We find that repeating the same dataset 10–50× starting from pretraining leads to substantially better downstream performance, in some cases outperforming larger models. 🧵
Love seeing the timeline wake up to the fact that data is the most underinvested area in ML.
But let’s set the record straight: the world’s premier data research company isn't hypothetical. It already exists. It’s called @datologyai, and we’ve been building it for 2.5 years. 🧵
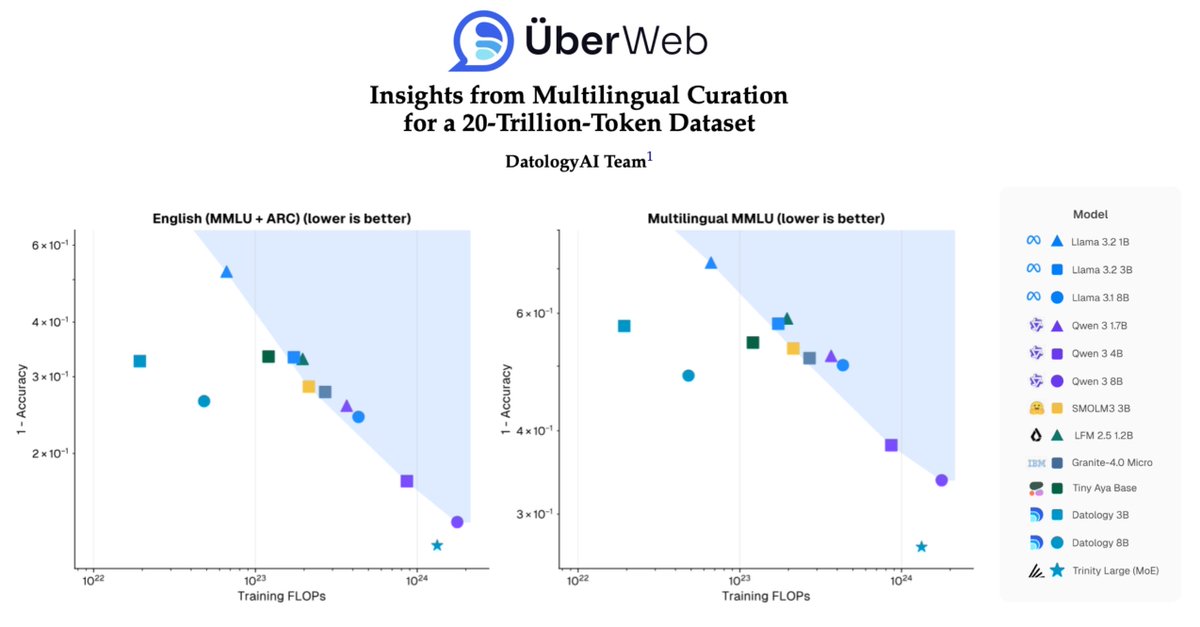
🌎Making your model multilingual doesn't have to sacrifice English performance—you just need better data.
@agcrnz, @RicardoMonti9, and I have been working on curating the best possible multilingual data with the team @datologyai, and it works! Check out the results 👇
1/ People often think better multilingual models must come at the cost of English performance. Not true. The constraint isn’t capacity, it’s data quality, and we can fix it.
Today @datologyAI shares ÜberWeb: a year of multilingual curation lessons, scaled to 20T+ tokens.
Excited to announce the return of American OSS with Arcee Trinity Large.
This model couldn't have been possible without the awesome collaboration of Modeling @arcee_ai , Infra @PrimeIntellect , and Data @datologyai
I can't say enough about how talented the whole team at Arcee is being able to scale from their first MoE to a big boy like this in such a short time.
Since the last data mix we have been in the lab pushing our midtraining and synthetic data to the limits. For Trinity Large we generated over 800B tokens of high quality synthetic code and 6.5T(!!!) tokens overall. We also added multilingual curation.
This was a massive effort from the whole Datology family. From scaling up the rephrasing workflows to support heterogenous clusters to scale efficiently (@isabelle226ku, @JackUrbs, @parthjdoshi@haakonmongstad@alvind319), pushing out midtraining and mixing (@_BrettLarsen) , innovating on new code synthetic data (@amrokamal1997) new math synthetic data (David Schwab), multilingual curation (@KaleighMentzer, @agcrnz, @RicardoMonti9)
and of course built on our great foundation of synthetic data (@pratyushmaini Vineeth Dorna)
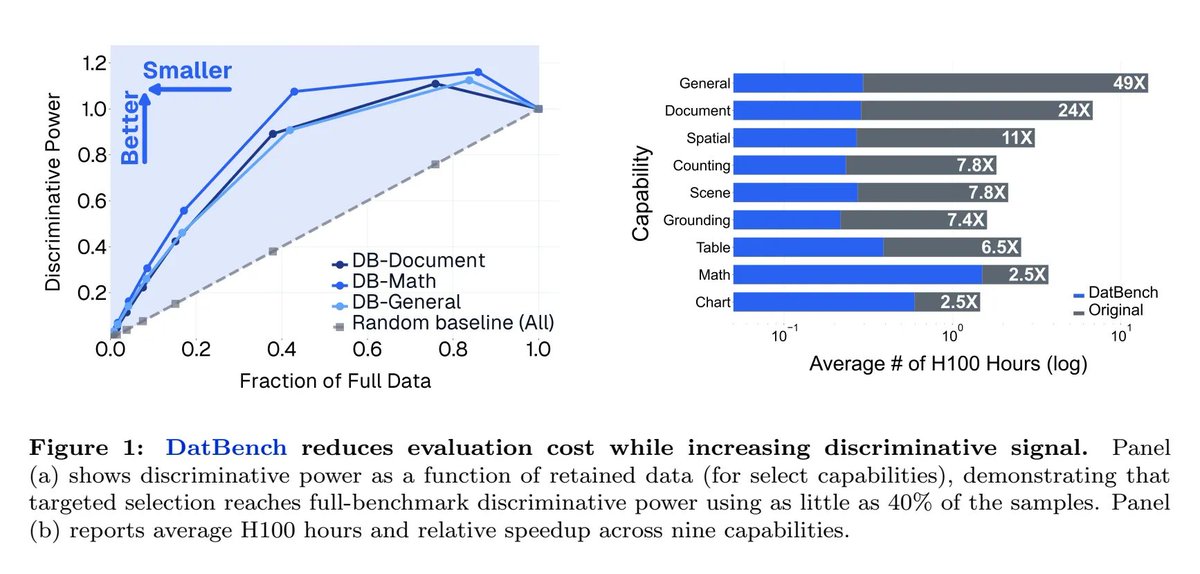
We cut VLM eval compute by >10× while INCREASING signal.
The secret? Most benchmark samples are noise:
→ 70% solvable without the image
→ 42% mislabeled or ambiguous
→ MCQ formats hide 35-point capability gaps
Presenting: DatBench
🧵 1/n
Just dropped a new text embedding methodology. Fast as heck on CPU only and still great for document similarity analysis, clustering, and classification.
How? Use a tiny ReLU network to approximate a big transformer from lexical (term frequency / bag of words) features.
1/ Really looking forward to #PytorchConf this week in SF-- I've spent the last couple of months at @datologyai immersed in the DataLoader ecosystem (especially for our VLM stack) and I have a few topics I would love to discuss with folks (DMs are open, say hi if you see me, etc. etc.) 👇
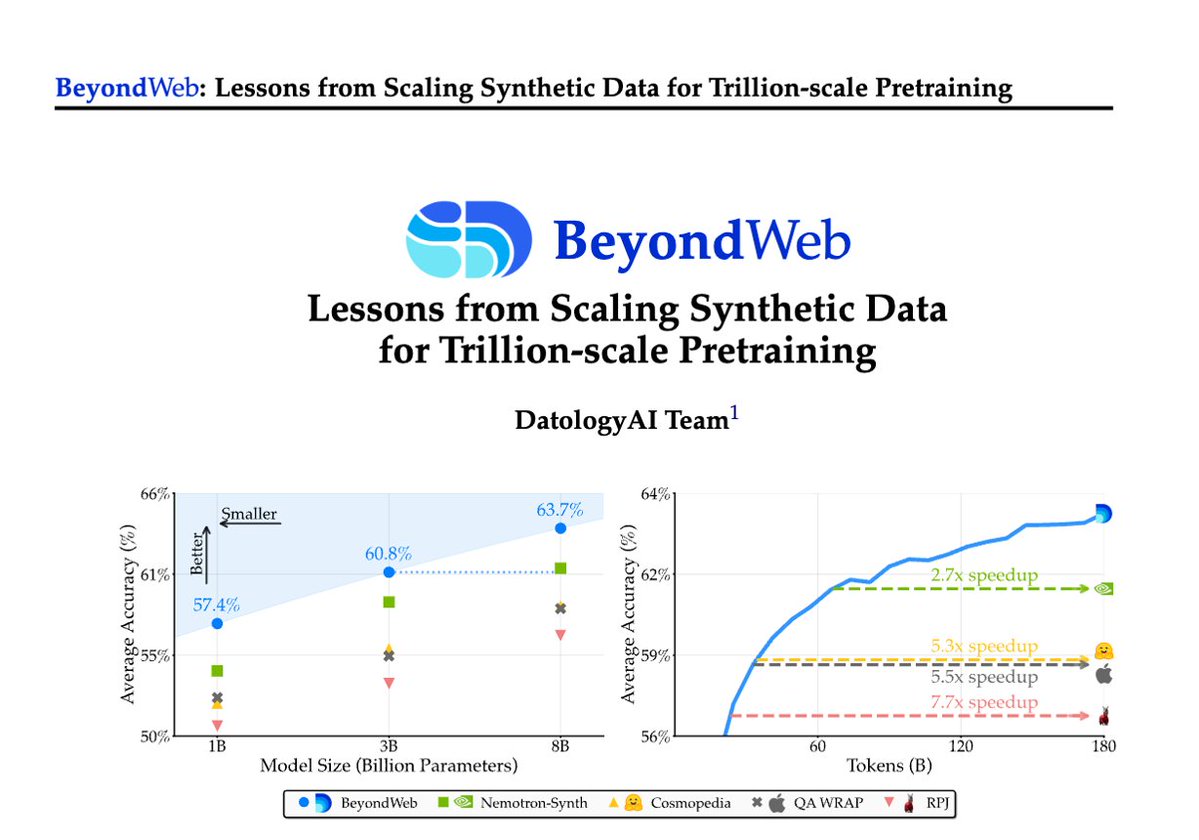
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳
- 3B LLMs beat 8B models🚀
- Pareto frontier for performance
Congratulations to our friends and partners @arcee_ai on the release of AFM-4.5B!
With data powered by @datologyai, this model outperforms Gemma3-4B and is competitive with Qwen3-4B despite being trained on a fraction of the data.
. @datologyai is back: state of the art CLIP model performance using data curation alone 🚀
✅ state-of-the-art ViT-B/32 performance: ImageNet 1k 76.9% vs 74% reported by SigLIP2
✅ 8x training efficiency gains
✅ 2x inference efficiency gains
✅ Public model release
Details in the 🧵 thread below 👇
We're incredibly honored to be named a Cool Vendor in the August 2023 Gartner® Cool Vendors™ in Cloud That Drive Business Disruption report.
The @granica_ai efficiency platform enables organizations to drive rapid innovation & become disruptors.
https://t.co/HUVwj0ijtt
Unrelated to my current work, but happy to announce that my summer work at @Livermore_Lab a few years back is finally published! Check out how we used neural networks with "phases" to model equations of state for inertial confinement fusion simulations. https://t.co/ZJdqkJ68Y4
This is a great example of market design: https://t.co/kxyjaEjzNr
It is also a great example of the failed econ publishing process. The "new" mechanism started in 2005. Data from 2005-2011. I saw Canice's talk in 2013. What good does it do for the JPE to "publish" it in 2022?!?