مساء الخير أنا بستقبل طلبات العمل الحر في مشاريع البيانات عامة سواء تحليل بيانات / علم بيانات/machine learning/deep learning/python كمان بقدم دروس في هذه المواضيع أيضا
للتواصل ال DM مفتوح للكل.
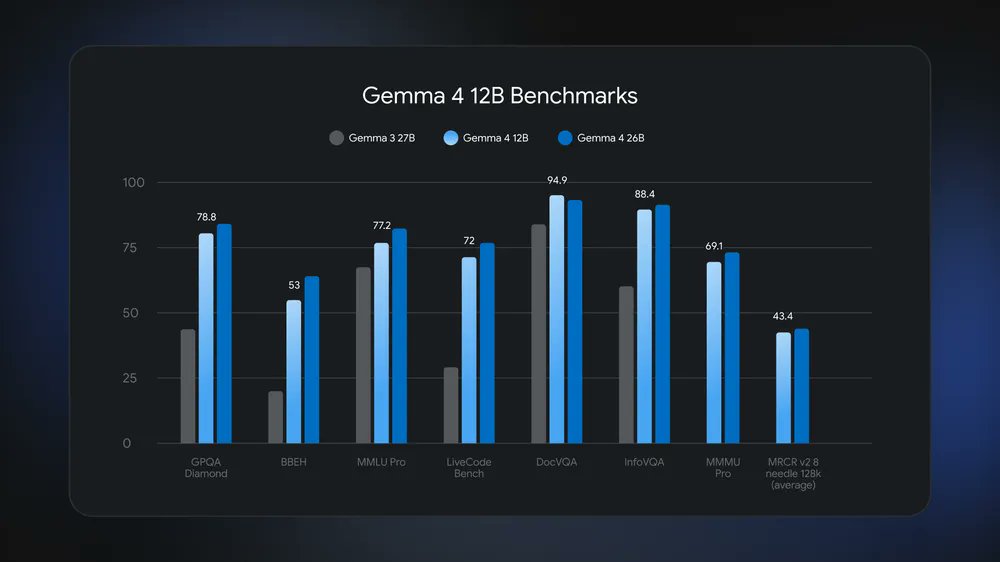
We just launched a Gemma 4 12B! Our first mid-sized model with native audio inputs. Gemma 4 12 B is a unified, encoder-free multimodal model.
🧠 vision and audio directly into the LLM.
💻 Just need 16GB of memory.
📊 Benchmark nearing 26B.
📄 Apache 2.0.
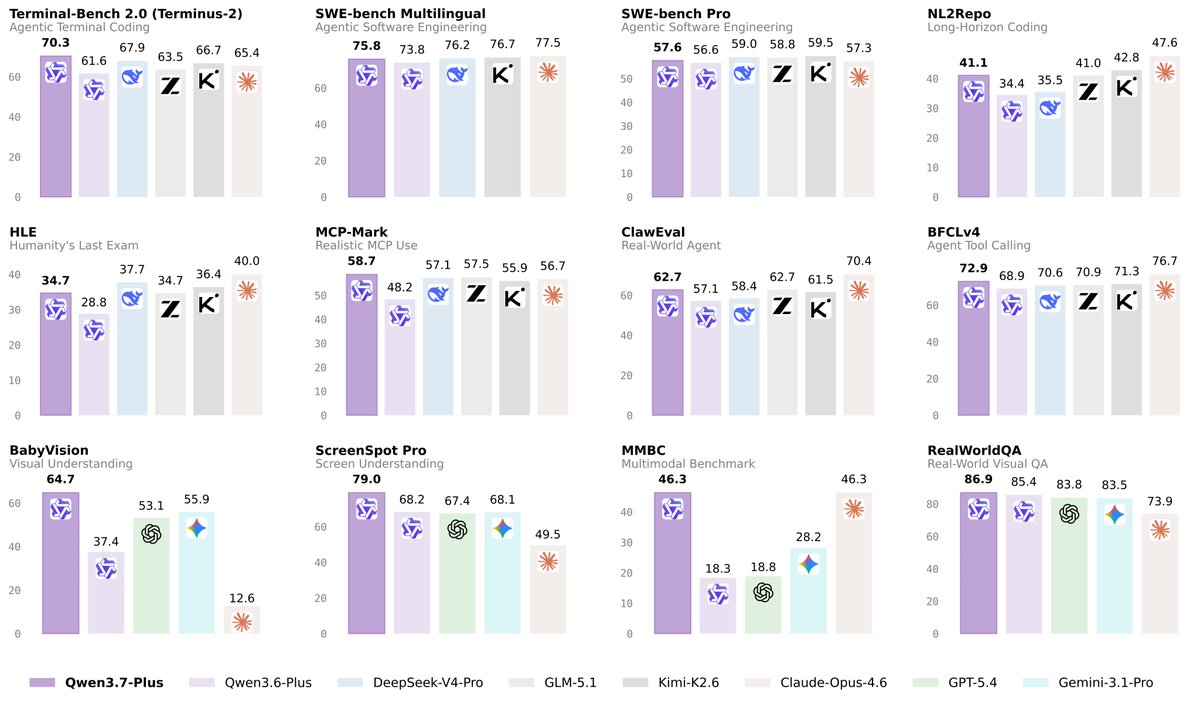
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
كنت اتكلمت قبل كدا عن الـ LSP وإزاي بيساعد Claude والـ Agents يمشوا جوه الكود ويوفروا tokens
في بقى طريقة تانية مكملة وبقت أساسية في الـ Code Agents الذكية وهي الـ RAG (Retrieval-Augmented Generation)
الفكرة ببساطة: بدل ما الـ Agent يرمي داتا ملهاش لازمة في الـ Context ويحرق توكنز وفلوس، بيعمل أولاً indexing للمشروع كله في Storage أو Vector DB
قبل ما الـ Prompt بتاعك يروح للـ LLM الـ Agent بيعمل search سريع في الفهرس ده. ويجيب بس الـ Relevant Code اللي ليه علاقة بطلبك. ويحطه في الـ Context. بكدا الموديل بيشوف "الخلاصة" المفيدة وبأقل تكلفة توكنز ممكنة!
معظم النقاشات الحالية عن الذكاء الاصطناعي في مجال البرمجيات مركزة على السؤال الخطأ:
“هل الـ AI يقدر يكتب ��ود؟”
ما الإجابة ببساطة: آه
لكن السؤال الأهم بكتير هو:
هيحصل ايه لما كتابة الكود نفسها متكنش أصع�� جزء في بناء السوفتوير ؟
على مدار عشرات السنين كان عنق الزجاجة في أي مشروع تقني واضح لأن أغلب الوقت والمجهود بيُستهلك في عملية التطوير نفسها.
لكن مع ظهور أدوات الذكاء الاصطناعي، المعادلة بدأت تتغير
فانت بتنتج آلاف الأسطر من الكود خلال دقائق و بتعمل Prototype كامل في ساعات بدل أسابيع.
وبقى الوصول للحل التقني أسهل
ركز معايا كدة في اللي جاي..
>> البرمجيات أصبحت أرخص في الإنتاج… وأغلى في الفهم
زمان لو المتطلبات غير واضحة، المشروع كان يتأخر و يطلع روحنا اجتماعات رايحة جاية..
النهاردة فنفس الغموض و عدم الوضوح ممكن ينتج نظام كاملا بسرعة قياسية، لكنه يكون بيحل المشكلة الغلط ..
الAI سرع الانتاجية صح.. بس مش هيقولك حاجة لو بتني ح��جة غلط
وهنا بدأ عنق الزجاجة ينتقل من مكان لمكان
التحدي الأساسي دلوقتي هو
* فهم المشكلة الحقيقية
* اتخاذ القرار الصح
* التاكد أن ما تم بناؤه هو فعلا اللي العميل أو المؤسسة محتاجينه
* إدارة التعقيد و المخاطر الناتجة عن الAI
أعتقد أن المهارة الأهم لمهندس البرمجيات حاليا هي
* فهم الأنظمة المعقدة.
* التفكير النقدي.
* الvalidation
* إدارة المخاطر و الGRC
الكود سهل.. انك تبني السيستم المطلوب صح هو اللي لسة نادر
ومن نفس المنطلق ده ال (SDLC) نفسها بتتغيز
فبدل من الشكل الكلاسيكي
Requirements → Design → Build → Test → Deploy
احنا بنقرب اكتر من شيء بالشكل ده (له رسمة في اول كومنت)
Intent → Context → Generate → Verify → Govern → Learn
.
الذكاء الاصطناعي ما علغاش هندسة البرمجيات لكنه غيّر مكان القيمة الحقيقية فيها
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: https://t.co/y3AupX3Pa0
✅ Qwen Studio: https://t.co/qpTnrCBjWt
⚡️ API:https://t.co/0sys00osKn
Gemini 3.5 Flash is amazing!
- Performs better than 3.1 Pro on coding & agentic tasks
- 4x faster than other frontier models
- 12x faster in @antigravity - 800 tokens/sec!
- Often at less than half the cost
And Pro to come…
Try it in @antigravity, @GeminiApp & more - enjoy!
Gemini 3.5 Flash is built to help you execute complex, agentic workflows.
3.5 Flash rivals flagship models to deliver frontier performance for agents and coding, at the lightning speeds you expect from the Flash series.