A human consumes about 2,000 calories per day. Over 20 years, that’s roughly 17,000 kWh of total food energy. Training GPT-4 consumed an estimated 50 GWh of electricity. That’s 3,000 humans worth of “training energy” for a single model run.
And GPT-4 is already dead. OpenAI retired GPT-4o from ChatGPT on February 13th. The model that took 50 GWh to train got less than two years of flagship status before replacement. The human you spent 17,000 kWh “training” for 20 years produces economic output for the next 40 to 60 years. The amortization window on GPT-4 was shorter than a car lease.
Now look at what replaced it. GPT-5.2, released December 2025, is OpenAI’s current default. The GPT-5 series consumes an estimated 18 Wh per average query according to the University of Rhode Island’s AI Lab, up to 40 Wh for extended reasoning. That’s 8.6 times more electricity per response than GPT-4. With 2.5 billion queries hitting ChatGPT daily and GPT-5.2 now the default model, the inference math gets staggering fast. Even at a blended average well below 18 Wh, you’re looking at daily electricity consumption that could power over a million American households.
This is what Altman is actually doing. OpenAI hit $13 billion in annual recurring revenue but still isn’t profitable. They need you to think of AI energy consumption as natural and inevitable, the same way you think about feeding a child, because the alternative framing is that they’re burning through enough electricity to rival small countries while racing to build 1-gigawatt Stargate data centers. The food analogy makes the energy costs feel biological and unavoidable instead of what they are: an engineering and business choice that scales with every model generation.
The comparison sounds clever at a fireside chat in India. It falls apart the second you do the arithmetic.
The magic isn’t in finding love or even being loved back. It’s in meeting someone whose presence quietly shapes you into someone stronger, kinder, more alive. Not because they complete you, but because they reflect the version of you that you are proud to see.
Many people are in the middle of the @CVPR deadline. So I'm sharing my guide to writing a CVPR paper (or any paper). My students have had this for years but I haven't shared it publicly before. I hope you find it useful and write a great paper. #CVPR2025 https://t.co/RAvnQFnuLQ
“When you’re playing a point, it has to be the most important thing in the world.
But when it’s behind you—it’s behind you.
This frees you to fully commit to the next point with intensity, clarity, & focus.
Negative energy is wasted energy.”
#Federer#Dartmouth#Commencement
Nobody else as good
Nobody else as kind
Nobody else would lay their life down
On the line
Nobody else could do it
Even if they tried
Nobody else could come and save me
Every time
«The guitar itself didn't know that it could be played like this»
Guitarist Jinsan Kim plays an original composition with incredible skill.
[📹 JTBC Entertainment]
Generative video technology (eg Sora) has two huge challenges in front of it that will likely slow adoption by Hollywood et al: 1) high latency (waiting minutes/hours to get seconds of footage), and 2) lack of controllability (the video you get back isn't necessarily what you wanted). These are hard problems to solve, but history suggests we only need to solve one of them.
The existence proof for highly-controllable but high-latency systems in film is the render farm --- you specify what you want in a coarse way, and then you wait overnight for the polished video to get rendered. This isn't fun, but Pixar, ILM, etc showed that you can make it work.
The existence proof for low-controllability but low-latency systems is the current crop of text-to-image systems: users try a prompt, wait a few seconds for a result, and rapidly iterate based on what they see. Here the lack of controllability is almost part of the appeal! It's fun to roll the dice and see what comes out, but this becomes intolerable for most people when the latency is high.
I expect that we'll solve controllability first, probably by using generative video models that condition on something other than text (proxy geometries etc). The latency problem will likely take much longer to solve (just as it did with traditional CGI), and honestly might never get solved within the current paradigm.
Education will never be the same.
People are finding some incredible use cases with Apple Vision Pro and spatial computing.
10 wild use cases:
1. Learning how heart works
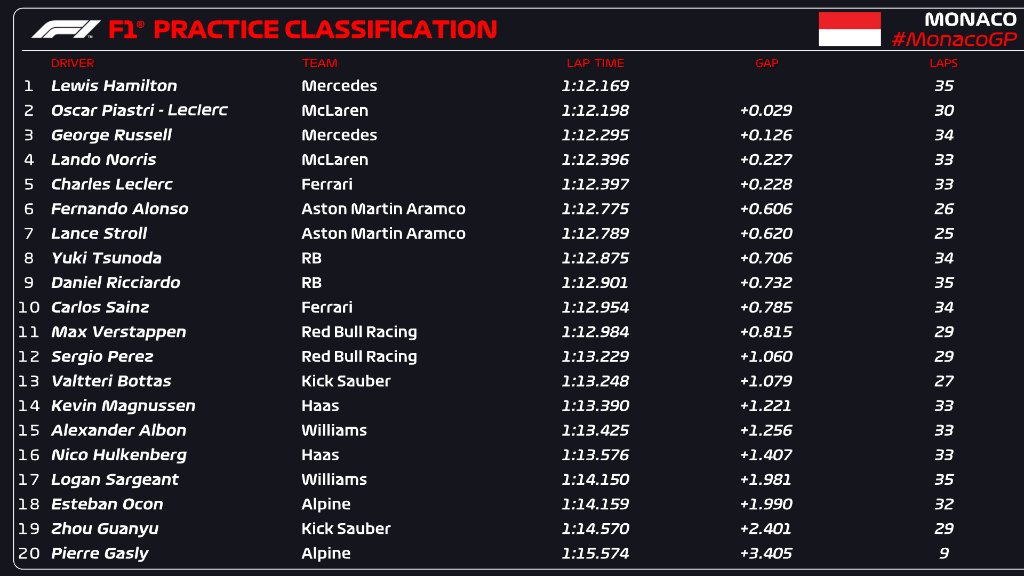
🇦🇺From missing Jeddah to this P2 in two weeks, what a journey! Very happy because coming here I wasn't sure I'd make it, but we made progress in every session and I gave everything to get pole. As long as I have no pain, I’ll fight for a good race result!
https://t.co/7ggfeCpv8h
How to cope with paper rejection?
Rejection SUCKS! It feels awful that months of hard work did not pay off. 😭 How do we hold a positive outlook when dealing with rejection?
A thread of lessons (learned from many rejections) 🧵
Shoutout to the anonymous reviewer in my @CVPR#CVPR2024 AC pile who raised their scores from WR to WA with the comment: "I apologise that I did not notice XXX... ".
Heart-warming when reviewers take their jobs seriously as scientific assessors regardless of the ego!
Want to save 25% latency in Diffusion Models with just 5 lines of code? Check our new paper on Adaptive Guidance: https://t.co/JZdNRRawqU
The brilliant minds behind this project: Jonas Kohler @juancprzs@Jp_perezu@AlbertPumarola@BernardSGhanem Pablo Arbeláez @alitabet