Hudi 1.0 is the most powerful release to date for data lakehouses. Read the blog for details:
Secondary Indexing, Expression Indexes, Partial Updates, Non-blocking Concurrency Control, New LSM timeline, +more: https://t.co/QHi7rnNsn9
#datalakehouse#opentableformat
GE Aviation: 30+ source systems in production, several hundred Apache Hudi tables, 14+ months in production, 10,000+ tables in the dev pipeline.
Modernizing 150+ source systems across the aviation ecosystem ↓
Tunable: inline / after N commits / time-based / async. Selection by log size, file-group activity, or partition.
A fully compacted MoR table reads identically to CoW. The question is just when to reconcile.
Links ↓
#ApacheHudi#MergeOnRead
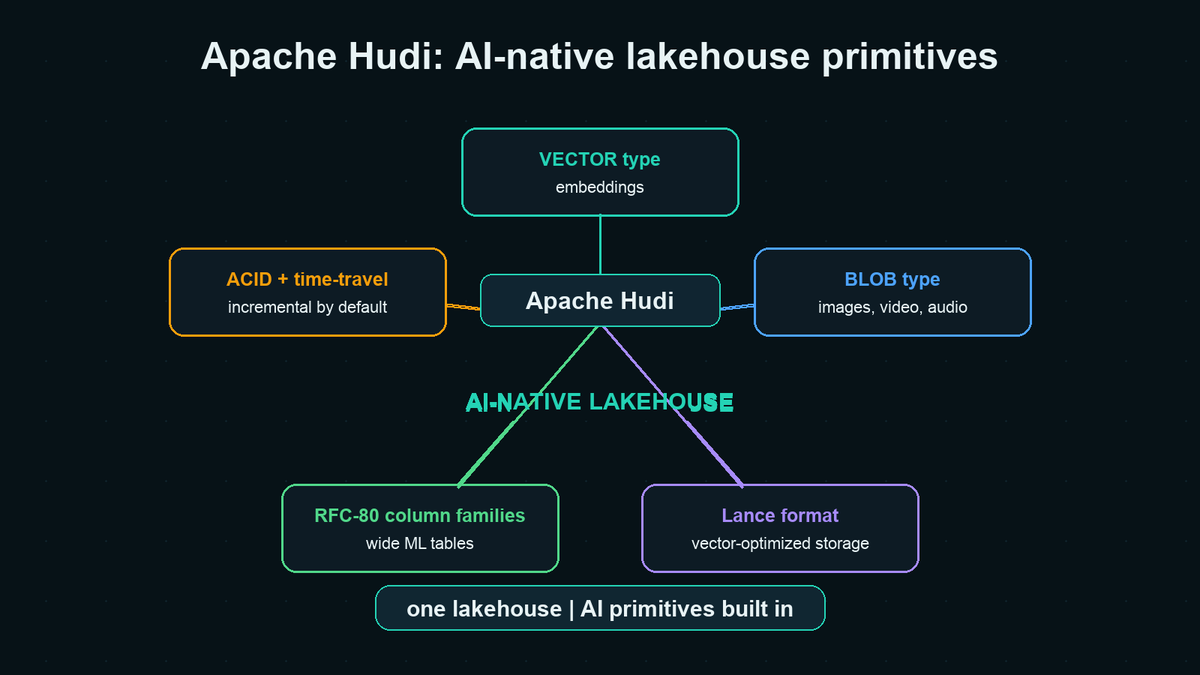
AI workloads on the lakehouse have a different shape than analytics.
Embeddings (768–3072 floats/row) replace counts and sums. Raw assets become first-class. Queries shift to "nearest neighbors filtered by tenant." Feature tables get thousands of columns wide.
AI-native isn't a separate stack. It's the same lakehouse with the primitives AI workloads actually need.
No need to copy data into another specialized system.
Links ↓
#ApacheHudi#AINativeLakehouse
File Manager — detects CDC files via EventBridge, queues through SQS, tracks metadata in DynamoDB.
File Processor — Step Functions orchestrating parallel Glue jobs that produce Hudi datasets.