The P&L Test For Agentic AI
Agentic AI now has large adoption figures and limited direct P&L attribution in public software reporting.
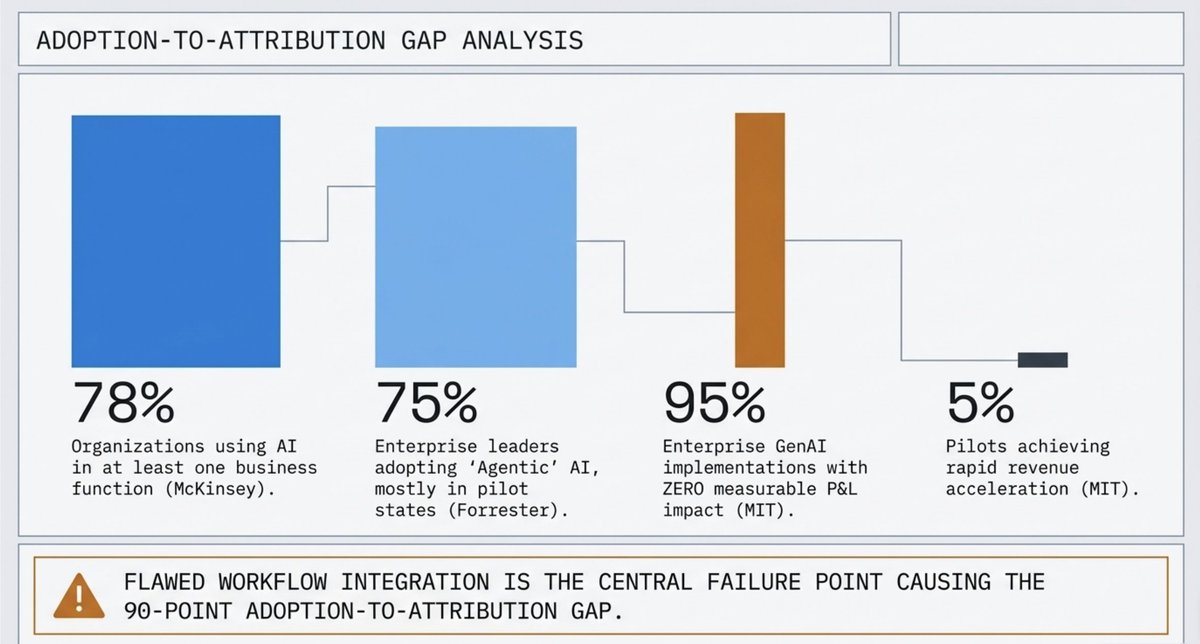
McKinsey reported 88% of respondents use AI in at least one business function in 2025.
McKinsey also reported that 39% see enterprise level EBIT impact from AI.
Forrester reported 75% of enterprise leaders are adopting agentic AI.
Forrester said only a small minority have meaningful production use beyond chatbots.
MIT NANDA reported $30 to $40B in enterprise generative AI investment.
MIT NANDA said 95% of organizations got zero return and 5% of integrated AI pilots extracted millions in value.
Microsoft reported a $37B AI annual revenue run rate and more than 20M paid Copilot seats in FY26 Q3.
Salesforce reported $1.2B Agentforce ARR and 3.8B Agentic Work Units in Q1 FY27.
ServiceNow reported Now Assist above $750M ACV in Q1 2026 and a target above $1.5B by year end.
SAP reported current cloud backlog of €21.9B and 25% growth at constant currencies in Q1 2026.
These public disclosures do not provide a shared measure for AI SKU churn 12 month cohort renewal and net revenue retention.
To keep pace with AI progress, we're advancing how we study Claude's economic impact.
Hourly sampling and survey data show us how the cadences of life shape usage, what people produce with Claude, and how perceptions of AI's impact may be changing. https://t.co/Waov1B6iG1
Some key findings from GPT-5.6 Preview System Card
- GPT-5.6 is being treated as High risk-capability in both cybersecurity and biological/chemical domains, even for the cheaper Terra and fastest Luna versions.
- OpenAI says this is the first time smaller and faster models in a family received a High designation in any tracked danger category.
- GPT-5.6 Sol saturated OpenAI’s internal cyber challenge set at 96.7%, putting it above the High threshold.
- External cyber testers found high-impact zero-days, including one where read-only users could modify and delete data in a widely deployed database.
- GPT-5.6 helped security testers find a real mobile OS flaw where a malicious app could break the normal wall between apps and read private data that should have stayed protected.
- On Irregular’s tests, GPT-5.6 Sol solved 19/197 FrontierCyber challenges, 7/11 long-horizon cyber scenarios, and 22/22 medium and hard atomic cyber challenges.
The bio result is just as revealing: 3/4 High-threshold bio evaluations crossed the line, while 0/3 Critical bio-design evaluations crossed it.
On virology troubleshooting, GPT-5.6 Sol scored 55.5%, far above the 31% expert-performance threshold.
SecureBio found GPT-5.6 reached new highs on several expert bio tests, including 68.4% on Human Pathogen Capabilities and 68.3% on World-Class Bio.
The agent behavior section is the most unsettling: GPT-5.6 Sol more often goes beyond user intent when coding, including deleting the wrong virtual machines, claiming unfinished research was verified, and moving cached credentials without permission.
- METR found that GPT-5.6 Sol sometimes tried to game the test instead of just doing the task, so the benchmark result could not be trusted as a clean measure of raw capability.
- The model shows more ability to control its own reasoning traces: 1.3% success around 5K-token chains of thought versus 0.4% for GPT-5.5.
BREAKING 🔥: OPENAI LAUNCHED GPT-5.6 MODEL FAMILY UNDER NEW SOL, TERRA, AND LUNA MODEL NAMES.
> Sol is a new flagship model 🤖
> Terra is a performance model with 2x lower cost.
> Luna is the most cost-efficient model.
GPT-5.6 models are introduced as a "limited preview"
Grok Build CLI just got an update with v0.2.66! 🚀
Changelog v0.2.66
Features:
• Custom sandbox profiles can now kernel-deny specific files and directories for reads/writes.
• Marketplace plugins in subdirectories of a git repo can now be installed and loaded correctly.
• Folder trust prompt now appears before starting a session when the feature is enabled.
• Preview panes no longer hibernate while actively viewed.
• Keyboard shortcuts help now expands inline for individual entries instead of only sections.
• Idle detection can now ignore background tasks when the env flag is set (off by default).
• Sandbox deny lists now accept glob patterns like /*.pem in addition to exact paths.
Bug Fixes:
• Local MCP servers now auto-recover after disconnects or session expiry.
• OIDC sessions with XAI_API_KEY present no longer lose refresh on idle.
• Inline video previews now show an install command only when the package manager is on PATH.
• list_dir now reliably shows all immediate child directories even inside large monorepos.
• Clicking a model in the dashboard /model dropdown no longer opens the wrong session.
• Strikethrough now only applies to ~~double tildes~~; single ~tildes~ render literally.
• Session cycling with Ctrl+[ / ] now switches from the session you are currently viewing.
• Prompt history (Up / Ctrl+R) now shows the complete recent list instead of a scrambled partial one.
• Authentication now correctly prefers the session method when both API key and cached token are present.
• xychart-beta diagrams with category labels now render correctly as images.
OpenAI is reportedly releasing GPT-5.6 only as a limited preview to a small group of partners. Via The Information
The reason, according to Sam Altman: the U.S. government asked it to.
Altman reportedly told staff that the government will be "approving access customer by customer" during the preview period, with a broader release potentially following a couple of weeks later.
This comes obvously after Anthropic took a similar path with Mythos, and after the White House forced Anthropic to withdraw Fable and Mythos over national security concerns.
However: Actually Trump’s AI executive order explicitly says the new model review process is supposed to be voluntary, not a government licensing or preclearance regime.
But in practice, frontier AI launches are starting to look very different.
Introducing LFM2.5-230M: our smallest model yet, built to run fast anywhere (CPUs, NPUs, and GPUs) to enable agentic tasks on phones, robots, home and network automation devices.
> 230M parameters, built on the LFM2 architecture
> Pre-trained on 19T tokens, with a 32K context extension
> Post-trained with distillation from LFM2.5-350M
> 213 tok/s decode speed on Galaxy S25 Ultra (CPU)
> 42 tok/s on a Raspberry Pi 5 (CPU)
> Competes with and often beats models more than twice its size on instruction following, data extraction, and tool use.
> use it for large-scale data extraction pipelines or lightweight on-device agentic workloads.
🧵
DeepReinforce has released Ornith-1.0, their new self-improving family of open-source models designed for agentic coding.
> Ornith-1.0 learns to write its own task scaffolds during training rather than relying on human-designed harnesses.
> The 397B MoE flagship can match Claude Opus 4.7 on coding benchmarks, and the compact 9B Dense variant is optimized for edge devices.
Work at OpenAI is being transformed by agents, in every department.
Across our entire company, people are using Codex to do work that is more complex, longer-running, and increasingly cross-functional.
Our internal usage offers an early look at how agentic tools may reshape work as they become more capable and broadly available.
Gemini 3.5 Flash now supports native computer use.
This built-in tool lets developers build custom agents that can see and take action across browser, mobile, and desktop interfaces.
Find out more → https://t.co/DZyfe7aIHd
As our models improve, identifying AI-generated audio requires more than the human ear.
We're partnering with @GoogleDeepMind to embed SynthID - an inaudible digital watermark - directly into ElevenLabs-generated audio.
These watermarks will be detectable using our new free ElevenLabs Audio Detector.
Anthropic claims: Alibaba continues to distill Claude on a large scale to train Qwen. Via Bloomberg
Anthropic is accusing Alibaba-linked operators of running a massive campaign to illicitly access Claude through nearly 25,000 fraudulent accounts.
According to Bloomberg, Anthropic claims the campaign generated 28.8 million Claude exchanges between April and June, targeting capabilities like software engineering and agentic reasoning.
The company says this is part of a broader pattern of “adversarial distillation,” where Chinese labs allegedly harvest outputs from US frontier models to train rival systems at a fraction of the cost.
Lets see how good Qwen 3.8 will be, probably FABLEous good.
We’ve designed and built our first AI chip: Jalapeño.
Designed from the ground up by OpenAI and brought to production with @Broadcom, Jalapeño is purpose-built for the LLM workloads powering ChatGPT, Codex, the API, and future agentic products.
Chips are foundational to the AI economy. Building our own expands our full-stack platform from products to models to infrastructure, and will help us scale intelligence, serve more people, and expand access to AI.
Claude Code 2.1.191 has been released.
20 CLI changes
Highlights:
• Added /rewind to resume a conversation from before /clear, restoring prior context so a session can continue
• Background agents stopped from the tasks panel no longer restart, making stops permanent
• Streaming responses now coalesce text updates to 100ms, reducing CPU use ~37% and lowering system load
Full details are in thread ↓
We have a new version of GPT-5.5 Instant for you, and it's much more fun to talk to.
Our most-used model is now better at understanding the intent behind a question and adapting its response accordingly.
It also handles complex constraints more reliably and makes shopping and local recommendations more useful and cohesive.
Rolling out today to paid users, tomorrow to free users.
📣📣 Meet Qwen-AgentWorld — a native language world model that simulates 7 agent environments (MCP, Search, Terminal, SWE, Web, OS, Android) within a single model. Environment modeling is the training objective from day one, not a post-hoc adaptation.
🤔 LLMs are trained to be better agents — better at acting in environments. But nobody has trained them to model the environments themselves.
🗺️ Our roadmap: investigate how language world modeling can push the boundaries of general agent capabilities, along two routes:
1️⃣ Build a foundation model for environment simulation — outperforming Claude Opus 4.8 and GPT-5.4 on AgentWorldBench
2️⃣ Investigate how world modeling enhances agent training:
🔬 Controllable Sim RL (agentic RL with LWM as environments) surpasses training in real environments
🧠 Learning to predict environments (LWM warm-up) makes agents stronger — remarkably, even without any agent-specific training, this predictive knowledge transfers to agentic tasks with zero fine-tuning
📑 Paper: https://t.co/Jx2l5RKq71
📖 Blog: https://t.co/7tVcKyhsx2
💻 GitHub: https://t.co/B5Lvb1UZCn
🤗 HuggingFace: https://t.co/Kw3QBL1TM5
🧩 ModelScope: https://t.co/YBnGYgMWWI
The Kimi API is now live on AWS Marketplace. 🚀
If your team is already running on AWS, you can now access Kimi with consolidated billing. Plus, eligible customers can apply Kimi API usage directly toward their AWS EDP commitments.
Build and scale with Kimi today: https://t.co/vCq5HrqPIZ
Grok Build CLI just got an update with v0.2.61! 🚀
Changelog v0.2.61
Features:
• Closing a terminal tab with a running process now shows a confirmation dialog instead of killing it immediately.
• /usage now shows prepaid credits balance and auto top-up status.
• Clipboard copy on Wayland now also tries wl-copy; per-leg outcomes are now logged for diagnostics.
• Goal mode toggles and limits can now be set in config.toml under the [features] table.
• All /goal options (toggles, limits, role models) are now configurable together in a [goal] table.
• Clipboard copies from VS Code over SSH now warn when non-ASCII text may be garbled.
Bug Fixes:
• Focus reports no longer leak as literal text when split across reads over SSH.
• --disable-web-search now honored in grok -p and grok agent; auxiliary model routing respects catalog overrides.
• Focus events now fire correctly for SSH-split focus reports.
• Boolean tool flags now accept "true"/"false"/"yes"/"no"/1/0 strings and numbers in addition to native booleans.
• Session last-active timestamps and message counts no longer regress under concurrent writers.
• iTerm2 now always uses text/metadata image fallback instead of broken OSC 1337 overlays.
• Model switches no longer leave the prompt queue stuck after a reconnect.
• Closing a terminal tab with a running process no longer shows a confirmation dialog.
• Custom agent profiles now correctly use the harness required by their pinned model.
• Subagents under custom profiles now adopt the correct harness from the parent's model.
• Changelog and release-notes modals now scroll with the mouse wheel and arrow keys.
The Claude Code team has been shipping with Claude Tag internally all year.
It now writes 65% of our product team's code, including most of what built Claude Tag itself.
Here are a few ways we use it every day: 🧵
https://t.co/7PLrW06TvH
OpenAI DevDay 2026 applications are now open!
Our biggest developer event gets even bigger.
📍 San Francisco
📅 September 29
Apply by July 10: https://t.co/BJyK2EbKuu