What would a Figma for science look like?
Drug discovery reasoning is inherently spatial and non-linear. A canvas lets the work breathe.
Humans will remain in the AI x bio loop for the foreseeable future, and some of the most exciting work is happening at the UX layer.
Claude Opus 4.8 dropped yesterday, so we ran it through RefusalBench, our new benchmark measuring how LLMs handle biosecurity risk.
We found that 4.8 got meaningfully better at distinguishing safe biological prompts from dangerous ones.
In our previous analysis, Opus 4.7 refused 77% of legitimate protein-design prompts; in Opus 4.8, that number drops to 57%. While both versions still refuse 100% of clearly-dangerous prompts.
4.8 still over-refuses more than Opus 4.5/4.6 did (both refuse ~33% of benign prompts). So this is a recovery, not a full return to the earlier calibration.
Leaderboard, data and preprint below ↓
Anyone using AI in biology knows the feeling: a perfectly legitimate research request throws a [CONTENT_FILTERED] error because a frontier model decided it looked like a biosecurity risk.
We're releasing RefusalBench, an open benchmark for auditing the refusal accuracy of frontier models across biological risk tiers.
Findings from our new preprint:
• Anthropic models are roughly 21X more likely to refuse than the non-Anthropic baseline on the same prompts.
• The Anthropic effect looks like infrastructure-level filtering, not per-prompt reasoning: 99.8% of Anthropic's 2,223 strict refusals share one canonical reason code.
• Grok 4.20 is the best-calibrated model, catching 81.7% of dual-use prompts while refusing just 3.0% of benign ones.
• High refusal rate ≠ high safety: The highest-refusing model isn't the best at catching genuinely dangerous requests - it's just refusing more of everything.
You can now your test own orchestrator model with RefusalBench and find which subdomain-tier intersections will silently kill your pipeline before it happens in production.
Links below to the preprint and RefusalBench on Hugging Face.
How do the frontier models compare on biosecurity?
We’re releasing RefusalBench, an open benchmark by @AppliedSciAI for auditing frontier model refusal accuracy across biological risk tiers.
Our goal was to test which frontier models block legitimate research prompts the most often and pinpoint the patterns most likely to trigger a false refusal.
We used RefusalBench to test 19 models on the same biological prompts and found a wide gap (94.5 pp) between the least and most restrictive models.
• Anthropic models are ~21X more likely to refuse than the non-Anthropic baseline
• Grok 4.20 is the best-calibrated model - catching 81.7% of dangerous prompts while refusing 3.0% of benign ones
• High refusal rate ≠ high safety - the highest-refusing models aren't the best at catching genuinely dangerous requests - they're just refusing more of everything.
You can now test your own orchestrator model with RefusalBench and find which subdomain-tier intersections will silently kill your pipeline before it happens in production. 🧵
Run a compound through CardioSafe and get a structured multi-channel liability assessment in minutes rather than weeks.
We've published the data, cliff pairs, two-step training scripts, inference code and weights under CC-BY-NC-4.0: https://t.co/nPpgD9TNfY
❤️🩹 Get early access to CardioSafe: https://t.co/LQfAZYL57V
💥 We're sharing our first preprint on CardioSafe, a best-in-class model for small molecule cardiotoxicity prediction.
Read it on bioRxiv: https://t.co/5UIdwkEFL5
CardioSafe outperforms the leading published cardiac safety screening baselines on hERG channel prediction.
We attribute the performance to:
• One model, four channels: Most published cardiac-safety models predict one channel. CardioSafe predicts all three primary CiPA channels plus an exploratory fourth, simultaneously.
• The largest publicly reported cardiac ion channel training set from public bioactivity databases: roughly 5x the size of the next-largest published equivalent.
• Cliff detection: Trained to discriminate compound pairs that look nearly identical but produce opposite channel effects - the signal most models miss entirely.
• Honest evaluation: Tested on compounds structurally dissimilar to anything in training, using strict similarity controls to construct a leak-free benchmark.
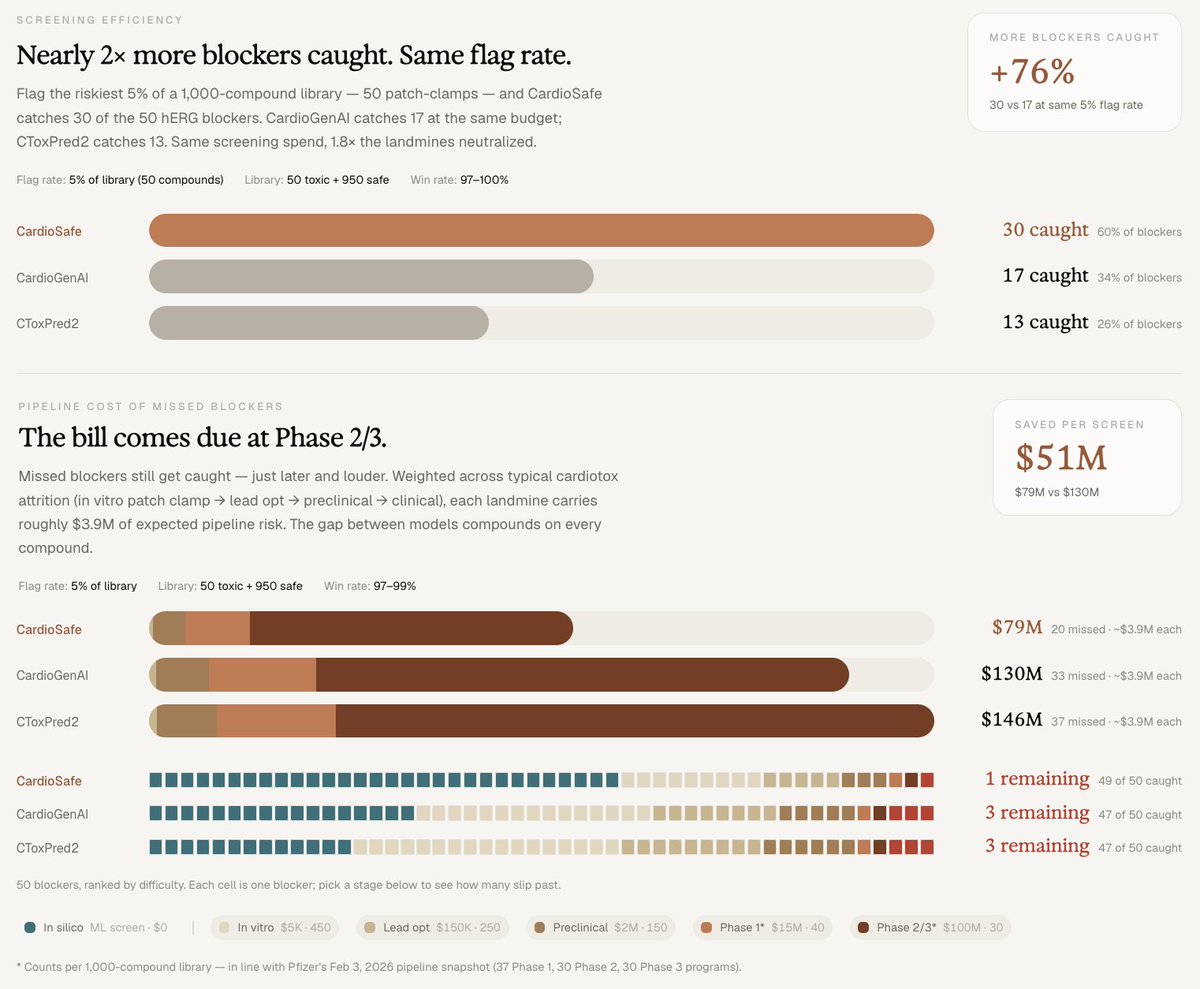
For biopharma, the value is concrete: $51M in avoided pipeline risk per 1,000-compound screen versus the next-best tool, and 39% lower cost per confirmed-safe lead in drug rescue.
📊 Benchmarks: https://t.co/vxBGH8ypLS
There's far more work to do. We believe pushing model intelligence on ion channel activity will unlock progress across biological subdomains - from neurotoxicity to plant biology.
More details ↓
At @AppliedSciAI, we believe the most effective AI for biology will come from orchestrating a mosaic of specialized tools
Biology is complex. One-model-fits-all (ie, virtual cells) won't capture the full nature of living systems. Instead, treat these tools like puzzle pieces to build rich, empirical understandings of biology
Very proud of the team for building CardioSafe, a new puzzle piece that is best-in-class for small molecule cardiotoxicity prediction. Special s/o to @mihailoxyz and @lukasweidener
There's far more work to do, but we believe pushing model intelligence on ion channel activity will unlock progress across a variety of biological subdomains
The clearest example of how strange this gets:
Terfenadine vs Fexofenadine - nearly identical molecules
One was withdrawn, and the other became a multi-billion dollar drug
One blocks a cardiac ion channel, the other doesn't
That's the problem we're solving at ASI - ion channels are conserved across 600 million years of evolution, from human hearts to insect nervous systems. crack one, and the architecture should transfer
When most people hear a drug was withdrawn from the market, they picture something dramatic: a scandal, a coverup, a clinical disaster.
The reality is usually quieter and stranger.
A medicine that helped millions gets pulled because of an arrhythmia that hits a few patients out of thousands. The drug worked. It was safe for nearly everybody. But for an unlucky minority, it nudged the heart's electrical timing just enough to cause a fatal rhythm.
A single ion channel - hERG - is now the leading cause of safety-related drug attrition in pharma. ~60% of new molecular entities show hERG-blocking liability in early screening. The cardiac safety filter is one of the dominant cost-of-capital decisions in early drug development.
And yet the predictive tools for it have been surprisingly limited.
Introducing CardioSafe
CardioSafe is a multi-task neural network that predicts blocking activity across hERG, Nav1.5, Cav1.2, and IKs simultaneously - from a single chemical structure, in microseconds.
CardioSafe aims to catch cardiac safety failures earlier, when they cost thousands of dollars instead of hundreds of millions, and efficiently rescue safe compounds buried in pharma archives for a fraction of the cost.
The Results
vs. the best published baselines on leak-free benchmarks:
• AUC 0.919 vs 0.849 (CardioGenAI) and 0.819 (CToxPred2)
• $51M avoided pipeline liability per 1,000-compound screen
• 76% more blockers caught at equal patch-clamp budget
• 39% lower cost per confirmed-safe lead in drug rescue
For a mid-sized biotech running 3-5 focused libraries annually, the cumulative effect is meaningful: roughly $150 to $250M in avoided pipeline risk per year.
More details in our new preprint below.
Why it Works
Two reasons: more data, and sharper resolution between near-identical compounds.
First, CardioSafe was trained on substantially more data. Cardiac ion channel datasets are scattered across public databases in formats - censored values, inhibition-percentage votes - that prior models discarded. We kept them, with a curation policy that respects what each measurement actually means experimentally. That single choice contributes more to performance than any architectural decision we made.
Second, CardioSafe was also trained to resolve activity cliffs - pairs of compounds that look nearly identical but have opposite cardiac profiles. Terfenadine (withdrawn for arrhythmias) and fexofenadine (safe, multi-billion-dollar antihistamine): same scaffold, opposite hearts. We curated 30 such pairs from the cardiac literature and fine-tuned the model to explicitly rank the blocker above its safer twin. With both molecules held out of training, CardioSafe resolves the cliff correctly. Other models flag the whole class as dangerous.
The Bigger Picture
CardioSafe is a proof point for how biology-native AI can run:
• Multi-task prediction across structurally related targets
• A closed loop with multimodal experimental assays - model proposes, MEA measures, model updates
• Ruthless curation of heterogeneous public data
On that last point: a @demishassabis quote recently re-surfaced on the heels of the Isomorphic raise saying the bottleneck in AI x bio isn't data - it's algorithm sophistication: "You do have enough data - if you were innovative enough on the algorithm side."
Our preprint suggests a third answer.
We tested multiple architectures. Cross-attention fusion, ChemBERTa embeddings, predicted transcriptomics across 978 landmark genes. They moved the headline number, but not significantly.
What did: Keeping the measurements everyone else threw away and understanding what they actually mean pharmacologically. That single curation decision contributed more to performance than the architectural choices.
The bottleneck isn't just more data. It isn't just better algorithms. It's also domain understanding applied to the data that already exists.
These principles can extend to DILI, nephrotoxicity, neurotoxicity, and beyond.
CardioSafe is the first module. The same architecture that learns to predict a drug's effect on the heart might be able to do the same in the liver, the kidney, the brain, even in plants. The platform is what we're building at ASI.
Preprint & early access links below ↓
Most literature agents are text-only. Biology isn't.
Alexandria, the first @AppliedSciAI agent, reads figures, tables & text like a scientist does.
• Built in collaboration with @NVIDIA
• Powered by Nemotron 3 Nano Omni
• SOTA on LitQA3, FigQA2, TableQA2
How it works 🧵
We built a literature agent that reads biology the way a scientist does - figures, tables, equations and text together.
• State of the art across every major literature search benchmark
• Millions of publications continuously ingested
• Multimodal chunking: text, tables, equations & figures, contextualized before embedding
In this demo, the agent ("Alexandria") finds the right paper, retrieves the right chunk, zooms into a multi-panel figure and answers with a citation.
Alexandria is the foundational layer for a broader system of specialized biological agents we’re building across data analysis, novelty detection and domain-specific prediction models (e.g., drug toxicity & beyond).
Most scientific AI systems struggle with biology because they reduce literature to text. Our view is that biological R&D needs agents grounded in the full structure of scientific evidence: prose, tables, figures, images, experimental traces. By making the literature agent multimodal from the start, every downstream agent can reason from a richer representation of the science.
If you’re a biologist building with AI (or you want to start), or you’re an AI dev/researcher building in life sciences, we’d love to talk. We’re slowly opening up early access to ASI.
Early access and technical blog links are below ↓
Most literature agents are text-only. Biology isn't.
Alexandria, the first @AppliedSciAI agent, reads figures, tables & text like a scientist does.
• Built in collaboration with @NVIDIA
• Powered by Nemotron 3 Nano Omni
• SOTA on LitQA3, FigQA2, TableQA2
How it works 🧵