Been seeing double responses in @OpenAI@OpenAIDevs for gpt 5.4 api for a while after it’s release. This is bugging me in production with random repeated responses. Why is it still unresolved?
Hey @royalenfield - a thread about how your customer support handles a stranded rider on a warranty-covered motorcycle.
My Himalayan 450 (KL 52 U 2633) failed mid-ride on 9 June with ECU-TPS failure. Stuck at Teknik Motorcycles, Sarjapur Rd, Bangalore since.
@Elevenlabs be doing everything except improving their TTS. Comeonn u guys are lacking there. Pullout v3 out of beta… add streaming end point to v3…more practical emotional/sound tags etc can point out a bunch of niche flag bugs too lmk
> I was out to Shillong for five days.
> Uninstalled X cuz my storage was full.
> Reinstalled back now, sees Clawdbot, moltbot, moltbook, molthub bs everywhere.
> Uninstalls again.
btw here’s rainbow falls in Meghalaya
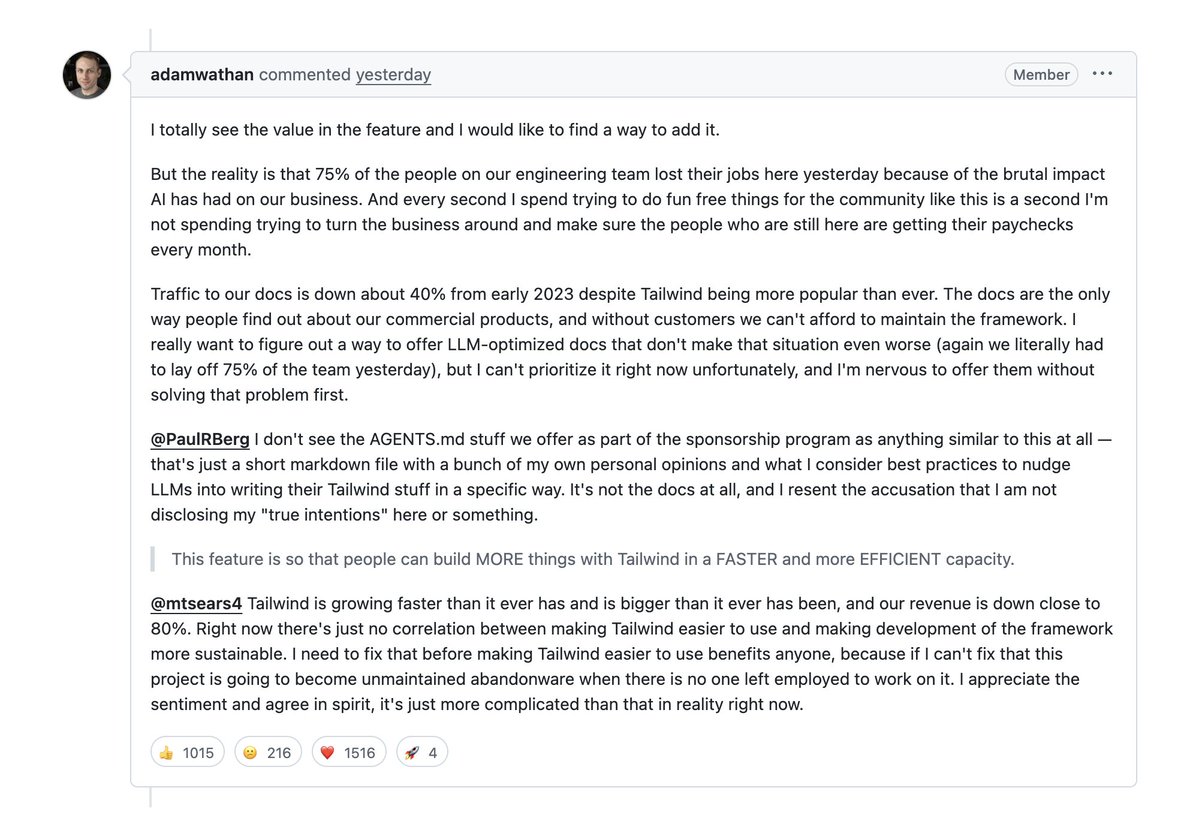
Tailwind lays of 75% of their team. the reason is so ironic:
> their css framework became extremely popular w AI coding agents, 75m downloads/mo
> that meant nobody would visit their docs where they promoted paid offerings
> resulting in 40% drop in traffic & 80% revenue loss
Before jumping into 𝐕𝐞𝐜𝐭𝐨𝐫 𝐐𝐮𝐚𝐧𝐭𝐢𝐳𝐞𝐝 𝐕𝐚𝐫𝐢𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐀𝐮𝐭𝐨𝐞𝐧𝐜𝐨𝐝𝐞𝐫𝐬,
let me explain why I implemented this from scratch.
For the past few months, I’ve been deep into audio deep learning:
understanding how text-to-speech, speech-to-text, and audio-to-audio models work.
Along the way, I covered mel spectrograms, Fourier transforms, signal processing basics, and even infra pieces like WebSockets and WebRTC.
A few weeks ago, I implemented a 𝐓𝐓𝐒 𝐦𝐨𝐝𝐞𝐥 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. I initially coded NVIDIA’s Tacotron2 architecture
Code
https://t.co/O29ldXlD6X
but instead of training it, I moved on to a 𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫-𝐛𝐚𝐬𝐞𝐝 𝐓𝐓𝐒 𝐦𝐨𝐝𝐞𝐥, which I trained for ~24 hours on an A100. [will share the code stuff in the future]
After that, I started building a speech-to-text model.
While working on the STT architecture, one block kept appearing repeatedly:
𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥 𝐕𝐞𝐜𝐭𝐨𝐫 𝐐𝐮𝐚𝐧𝐭𝐢𝐳𝐞𝐫𝐬
To understand RVQ, I needed VQ-VAE.
To understand VQ-VAE, I needed Variational Autoencoders.
And to understand VAEs properly, I first implemented a vanilla autoencoder.
So I ended up implementing all three:
Autoencoder → Variational Autoencoder → Vector Quantized VAE
𝐀𝐮𝐭𝐨𝐞𝐧𝐜𝐨𝐝𝐞𝐫𝐬 compress data into a latent space and reconstruct it back, while 𝐕𝐀𝐄𝐬 add a probabilistic structure by learning a distribution and regularizing it with a prior, enabling generation but often causing blur and instability.
AE Code
https://t.co/Fvua50p5oH
VAE Code
https://t.co/yzF2RPHKWD
𝐕𝐐‑𝐕𝐀𝐄 changes this by making the latent space discrete. The encoder maps inputs to the nearest vector in a learned codebook, turning each latent into a token from a fixed vocabulary.
VQ-VAE Code
https://t.co/kKaENveqHg
Why this matters:
• Speech and audio are inherently discrete
• Quantization yields efficient compression
• Discrete tokens integrate seamlessly with Transformers
Unlike VAEs, VQ‑VAEs use a deterministic encoder, no KL loss, and learn the token prior separately. They train via reconstruction, codebook, and commitment losses with straight‑through gradients , making them fundamental to speech synthesis, recognition, and modern audio tokenizers.
I’m going to implement RVQ next and share a detailed post about building TTS and STT models from scratch, voice cloning, and fine-tuning audio models.
If you’re into deep learning or computer science, 𝐟𝐨𝐥𝐥𝐨𝐰 𝐦𝐞 for insightful content
— and don’t forget to 𝐫𝐞𝐩𝐨𝐬𝐭 this!
Had this deep convo on male character development, how increasingly impressionable someone becomes with loses/heartbreaks. That feeling of losing someone who knows 99.9% of you and the ego that fires up to prove that everything they knew about you is wrong by evolving yourself.