@bclavie@minhash Hmmm then we can keep only the positives in the top-K from both methods?
This is also a good excuse to make the code I used available and add it as the first issue. 😬
I will try to do it later today.
Thanks @minhash for clearing one of the long-standing things on my to-do list!
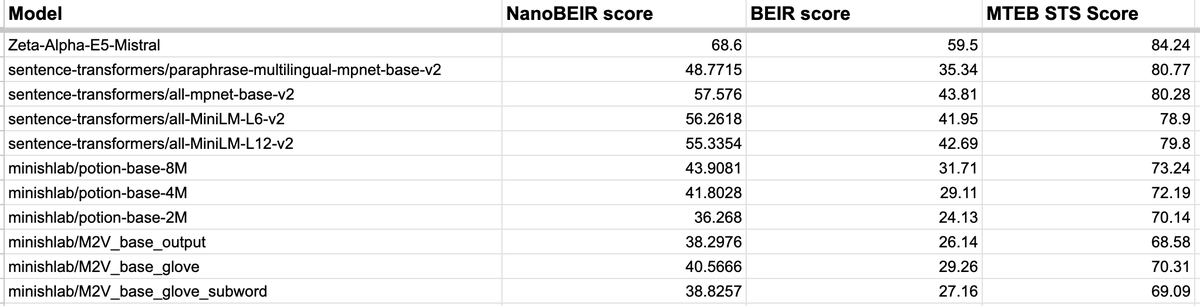
NanoBEIR scores should be higher than the full BEIR scores (it is only a subset of the full corpora, so it's "easier") But it should correlate quite well with the full scores.
When cooking your own embedding model, it's necessary to have a quick evaluation set to validate your ideas.
That's what I was in need of when trying my own set of experiments, when I found @ZetaVector's NanoBEIR set. It's perfect! A subset of BEIR to validate ideas on~
Though one thing missing for me to use it was how correlated were scores on NanoBEIR to those of BEIR? I didn't find this metric on their blog, so I decided to calculate it myself with a few models.
Generally, from what I see on a limited set of models that offered BEIR scores publically and calculating their NanoBEIR scores myself, the correlation is ~99%, which is great!
The scores come out to be on the higher end usually, so that score can't be compared against BEIR score, but to check on what works and what doesn't, it's good enough.
[ Then again, STSBenchmark scores are said to be ~70% correlated too—which was my previous "quick" evaluation set.
@bclavie@minhash That and the fact that it has so many positives that it would make the corpus too large compared to the other datasets.
It didn’t help that the size was also breaking my pipeline. 😅
I spent about a week trying to make it work on a single A100
We created it by randomly sampling 50 queries per dataset.
The corpora are the set of all positives and the intersection of the top-100 documents retrieved by Pyserini's BM25 and and Arctic-Embed-1.5-m.
@minhash @ZetaVector Hey, thanks for the shout-out!
Indeed, the scores are supposed to be higher (it is an easier set after all, with way less documents than the full collection), but the scores to BEIR should correlate quite well!
I'm looking for an intern to introduce Sparse Embedding models to Sentence Transformers! If you're passionate about open source, interested in helping practitioners use your tools, and enjoy embedders/retrievers/rerankers, then I'd love to hear from you!
Links to apply in 🧵
@Robro612 I’ve been bullish on listwise learning for a while. Too bad there are not many training datasets with multiple relevance annotations per query. Synthetic data to the rescue?
The latest uv release includes support for conflicting dependencies across optional groups.
A subtle but very powerful feature.
For example: use the PyTorch CPU build with `uv sync --extra cpu` and the CUDA build with `uv sync --extra gpu`. All powered by a single lockfile.
@GergelyOrosz Of course, if you just open the chat, ask the full question to the LLM and copy-and-paste their answer without critical thinking, that’s a red flag, and we will ask you to throughly explain how that code works. Other than that, all good.
@GergelyOrosz We explicitly tell people to use whatever tools they are used to, including cursor/copilot/etc.
The reasoning is the same. Everyone here uses it. You will probably use it. We just want to see how you think through the problem and how you come to an answer.
@beirmug@tomaarsen@Robro612@JinaAI_ I was writing an answer to you on LinkedIn, my phone’s battery died and I forgot to get back to it, sorry about that. 😅
@tomaarsen@Robro612@JinaAI_ I can take a deeper look into correlation with other models later this week. It’s something I really want to do, just didn’t had the time to finish yet.
@tomaarsen@Robro612@JinaAI_ Yes! So, we sampled using the Anserini’s BM25 and arctic-embed-1.5-m and the positives, of course.
We haven’t tested the correlation extensively, but for 7B parameters, the correlation was really good. I can share the code we used to create the dataset and the numbers we have.
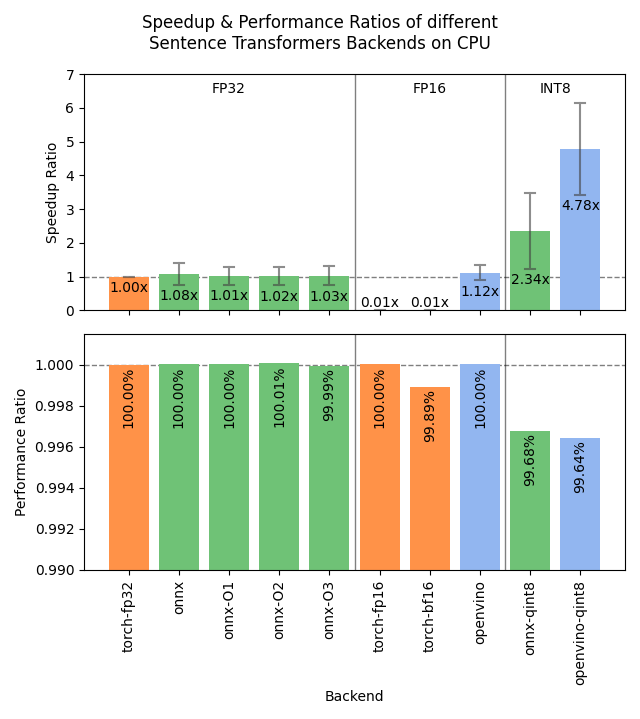
I just released Sentence Transformers v3.3.0 & it's huge! 4.5x speedup for CPU with OpenVINO int8 static quantization, training with prompts for a free perf. boost, PEFT integration, evaluation on NanoBEIR, and more!
Full release notes: https://t.co/n7Vgbk5LCv
Details in 🧵