RAGTIME is coming back for the 2nd edition!
Come join us to evaluate your search agents!
We once again feature multilingual and fully human evaluation
This is the ultimate way to know whether your systems are doing better
Please consider this my announcement / shill warning. Super excited to be @mixedbreadai 🍞 this summer!
Lots of cool stuff to be done in the first-stage / agentic retrieval areas!
@bclavie@capemox Dang I hadn't read your mandatory MTS quasi-essay on research yet. Compelling argument to break the loop and let software/ideas wag hardware/infra rather than vise versa.
The other evidence for that viewpoint is my ~2 days @mixedbreadai watching the science lead
@bclavie@capemox counterargument: this isn't paving a new software/compute path that we need new infra to serve, it's explicitly *returning* us to a well-known infra regime of BM25.
The more Zipfian distribution of these terms can't be understated.
That means this tiny SAE adapter enables decades of BM25 index optimizations, rather than having to step into the new set of (also great) manifold-hypothesis-driven LSR engines designed for SPLADE.
By now, everyone knows that single-vector embedding models are hugely limiting for modern workflows.
But they contain than you think: you can extract sparse Latent Terms from them.
And it turns out that BM25 is all you need to turn this vocabulary into a strong retriever.
@antoine_chaffin@matospiso > MaxSim only training a few tokens doesn't help this
Hmmm, XTR training is strictly sparser in this regard but seems to succumb less
@topk_io@matospiso Shameless plug that XTR training mitigates anisotropism/degen score distributions!
See modernbert_colbert_kd -> ModernBERT-XTR: same exact training except for XTR vs ColBERT training.
Discussed here: https://t.co/OwLPS1kDsJ
Anisotropy seems to be the quality-giver (at least confounder) but efficiency-killer. @topk_io identified it as a blocker to SMVE and I'm finding it to block TACHIOM too.
Would love to know what the ISO FT consists of @matospiso 🧐
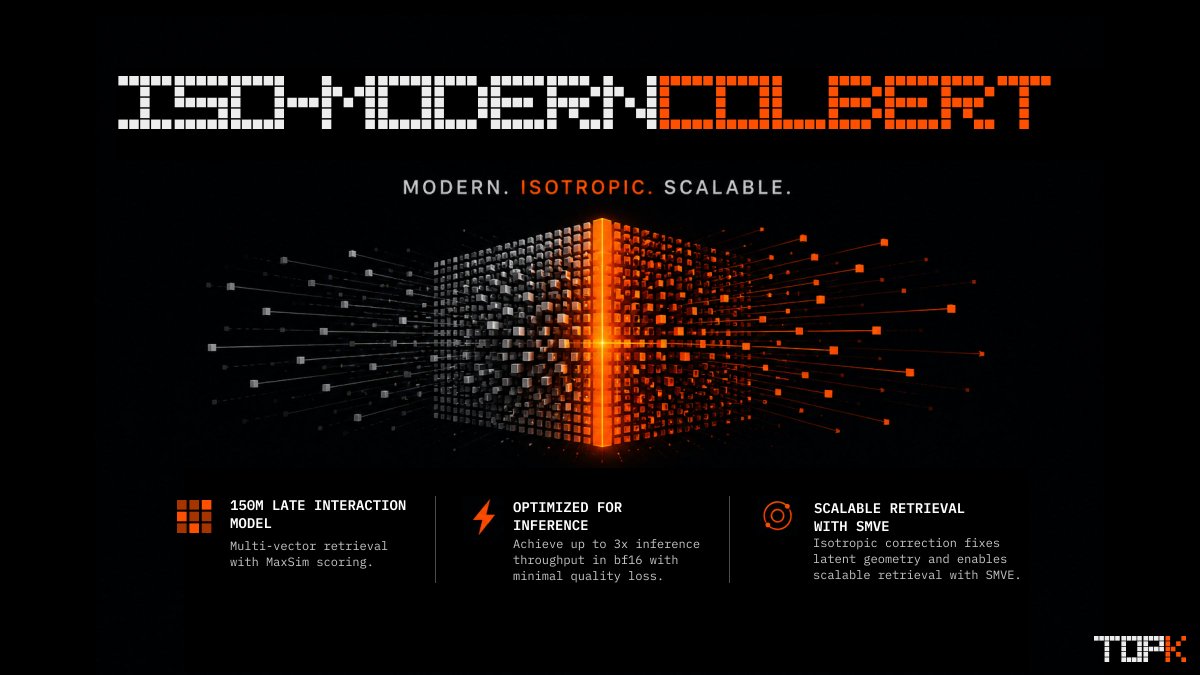
Even strong multi-vector models may break down when optimized for low-latency and high-QPS inference in production. But this can be fixed.
We're open-sourcing Iso-ModernColBERT, a late interaction model built for efficient inference and scalable retrieval.
🧵 (1/6)
@lateinteraction@topk_io@matospiso Lol the anisotropy measurement is only on a tiny set of MSMARCO docs, and TACHIOM support is all thanks to the nice python bindings of @SilvioMartinico .
Turns out it helps to have a vibrant community behind you!
ICYMI: @raphaelsrty just added index.freeze() to FastPlaid v1.4.7 which halves your size on disk if you know you won’t modify the index 🥶
Reversible with index.unfreeze() 🔥
PLAID's residual gather for full MaxSim is (theoretically) bandwidth limited, not IOPs limited. A single doc's residuals occupy >1 page.
So you can't expect to save much time with a clever ordering of document embedding bundles according to token-centroid co-occurrence.
This is why 1) XTR/WARP win big by skipping this load entirely 2) CPU-only versions of PLAID/TACHIOM indices can perform so well, and 3) VecFlow-Chamfer wins by saturating and parallelizing memory reads over its new 900 GB/s GH interconnect, not even needing to compress
Related to this is the general challenge in optimizing vector indices on GPU (in fact single-vec is even fewer FLOPs/bit than MaxSim), we sit well below the roofline, so the arithmetic we do for the final MaxSim hardly contributes to the wall time.