Releasing ColGREP and LateOn-Code models 🚀
ColGREP is a multi-vector search tool built in Rust made for coding agents. It's an hybrid grep which supports both grep features and semantic retrieval. Run 100% locally.
You get two SOTA code retrieval model within ColGREP
Do you like the open-source models we keep shipping at @LightOnIO? 👀
Now you can actually *build* with them!!
We're launching LightOn Console 🎮: three endpoints (Parse, Extract, Search) so you can run our models on your own documents without building the plumbing yourself!
🧵
Today, we're introducing LightOn Console.
⚙️ Three endpoints:
/Parse any documents
/Extract structured data
/Search enterprise knowledge with citations
🔌 Built-in connectors. MCP-ready. Governance enforced at the chunk level.
No infrastructure. No pipeline maintenance. No dedicated retrieval team required.
Make your enterprise knowledge agent-readable now!
Read the launch announcement: https://t.co/LcxXqyOgo5
Test it now: https://t.co/RNJQKEHzQ2
The late-interaction multivector retrieval ecosystem is exploding right now.
To help separate the signal from the noise, we put together an "Awesome Multivector Retrieval" list organizing the top models, engines, libraries, and datasets all in one place 📚 🧵👇
Quick update: TACHIOM 0.3.0 is out with mean-centering to help alleviate the anisotropy problem.
Also noticed that newer models usually need lower micro/small token thresholds than the defaults calibrated on ColBERTv2.0. More to come soon! ⚔️
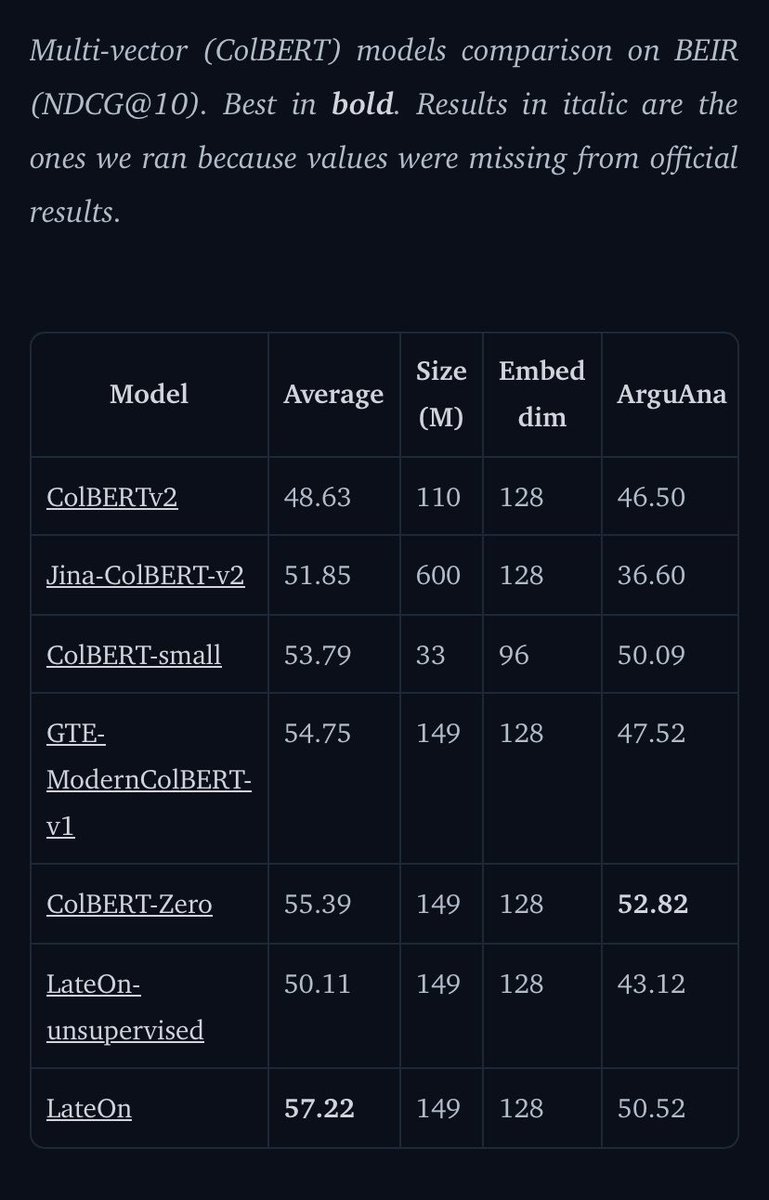
It’s only BEIR but there are almost 10 points gap between v2 and LateOn
We also have good evidence that the model generalize very well outside of BEIR
GTE-ModernColBERT was an upgrade
LateOn is a whole new generation
And all of them have the exact same usage in PyLate
At 140 million parameters, our LateOn model yield strong results 😉
Unrelated to LateOn, I'm really excited by what's happenning with multi-vector models right now
- New kind of indexes running on cpu
- New multilingual models
- Anisotropie being solved
- Sparse multi-vector
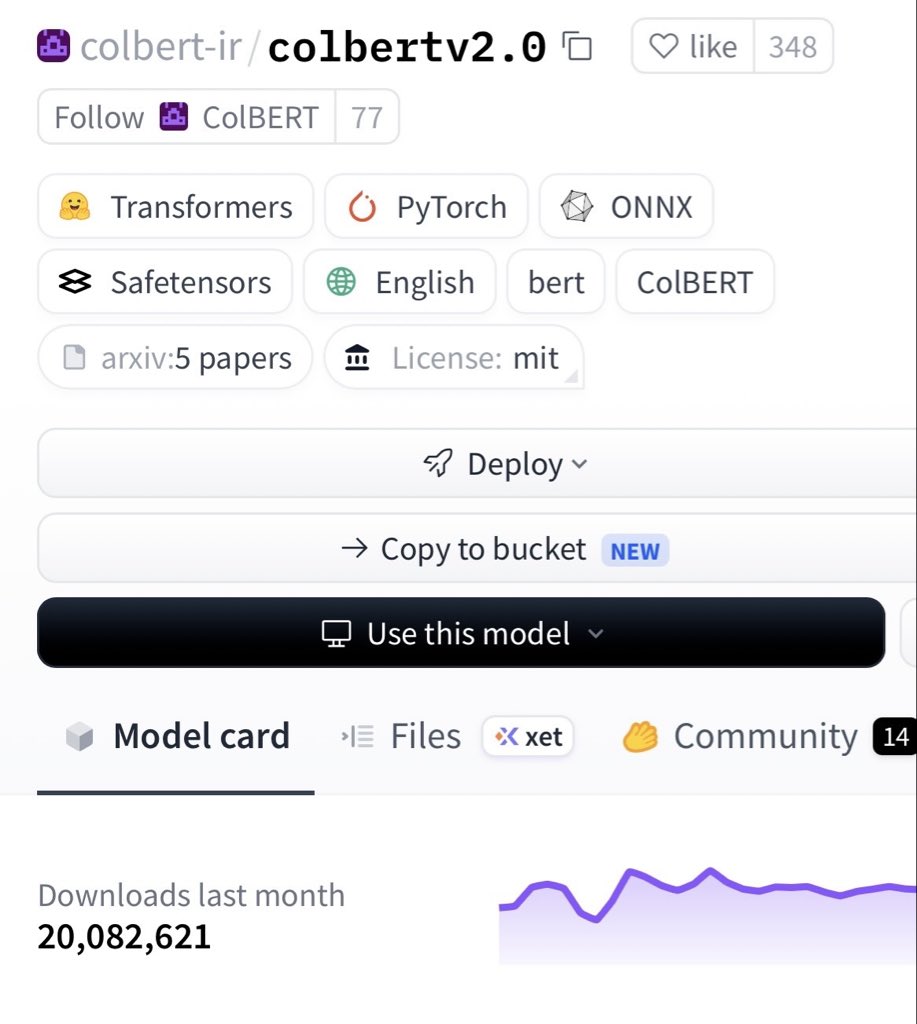
20M downloads / month is a new record for colbertv2
but people should probably migrate from this ancient October 2021 model to the LateOn colbert model from @raphaelsrty@antoine_chaffin et al (@LightOnIO)
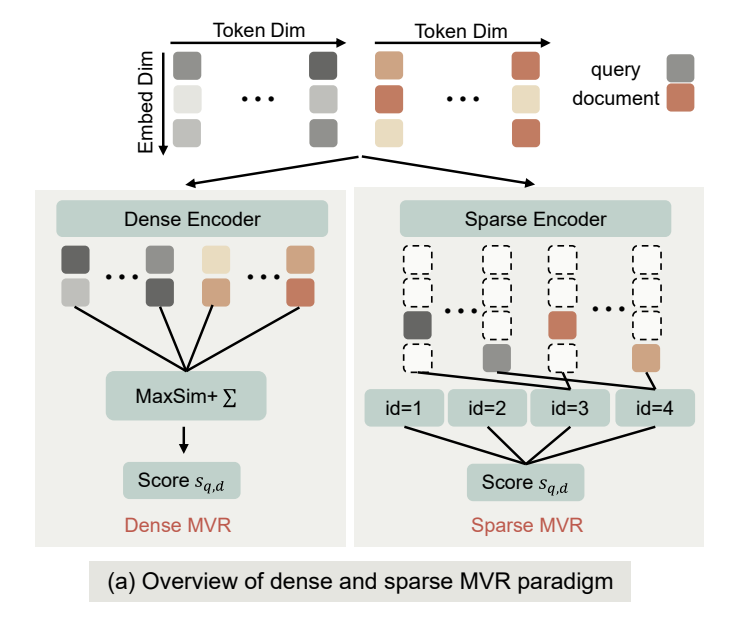
Late-interaction sparse retrieval? 😁
With neuron-level inverted indexing, on top of unsupervised sparse autoencoders. Works much better than directly training sparse retrievers.
Lots of cool ideas developed & composed in here. Thanks for the insights @Veritas2026@yifeiwang77!
I want an Iso-LateOn as well 😁
Very interesting work to scale multi-vector retrieval and fight anisotropism in models so it can produce sparse vectors for SMVE
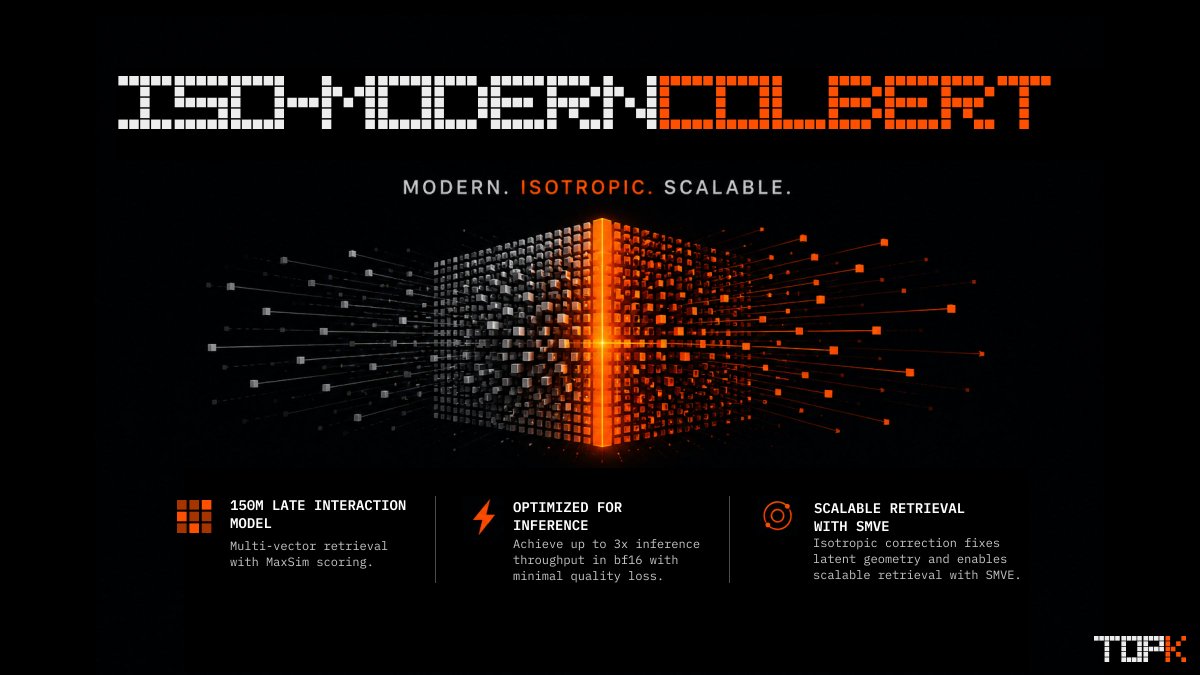
Even strong multi-vector models may break down when optimized for low-latency and high-QPS inference in production. But this can be fixed.
We're open-sourcing Iso-ModernColBERT, a late interaction model built for efficient inference and scalable retrieval.
🧵 (1/6)
Even strong multi-vector models may break down when optimized for low-latency and high-QPS inference in production. But this can be fixed.
We're open-sourcing Iso-ModernColBERT, a late interaction model built for efficient inference and scalable retrieval.
🧵 (1/6)
@aussetg Feel free to push a MR, could be interesting, even a draft one. At some point we could make colgrep cache friendly for kernel given a specific backend
ofc we do want to integrate a backend that brings something to the table but it cost nothing to push a draft MR :)
@Robro612 Thank you @Robro612 for spotting this ☺️ ! Also @paulomouraj spotted a memory issue with very long queries (browsecomp+ like queries) which we will fix asap
ICYMI: @raphaelsrty just added index.freeze() to FastPlaid v1.4.7 which halves your size on disk if you know you won’t modify the index 🥶
Reversible with index.unfreeze() 🔥
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: https://t.co/x6gEhQIaFV
💻: https://t.co/K6VIU2wjtW
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar@UlaLaParis@_jeev2@dh7net@clipdropapp@heyjasperai