1/ Can AI help researchers check whether published social science results actually reproduce? In our new PNAS paper, we tested this directly in the AI Replication Games: 288 researchers, 103 teams, and real replication packages from quantitative social science.
"LLMs .... overfit to surface patterns; struggle to abandon bad hypotheses even when evidence contradicts them; confuse correlation for causation; hallucinate explanations when experiments fail; optimize for plausibility, not truth". In short, LLMs act like human scientists.
do you guys know that you can *design* experiments with TMLE/DML/etc. in mind for the analysis? Here's the power calculation. Smaller sample size for free if you can guess how much your R2 will go down with ML adjustment.
https://t.co/t7KoI7lPnf
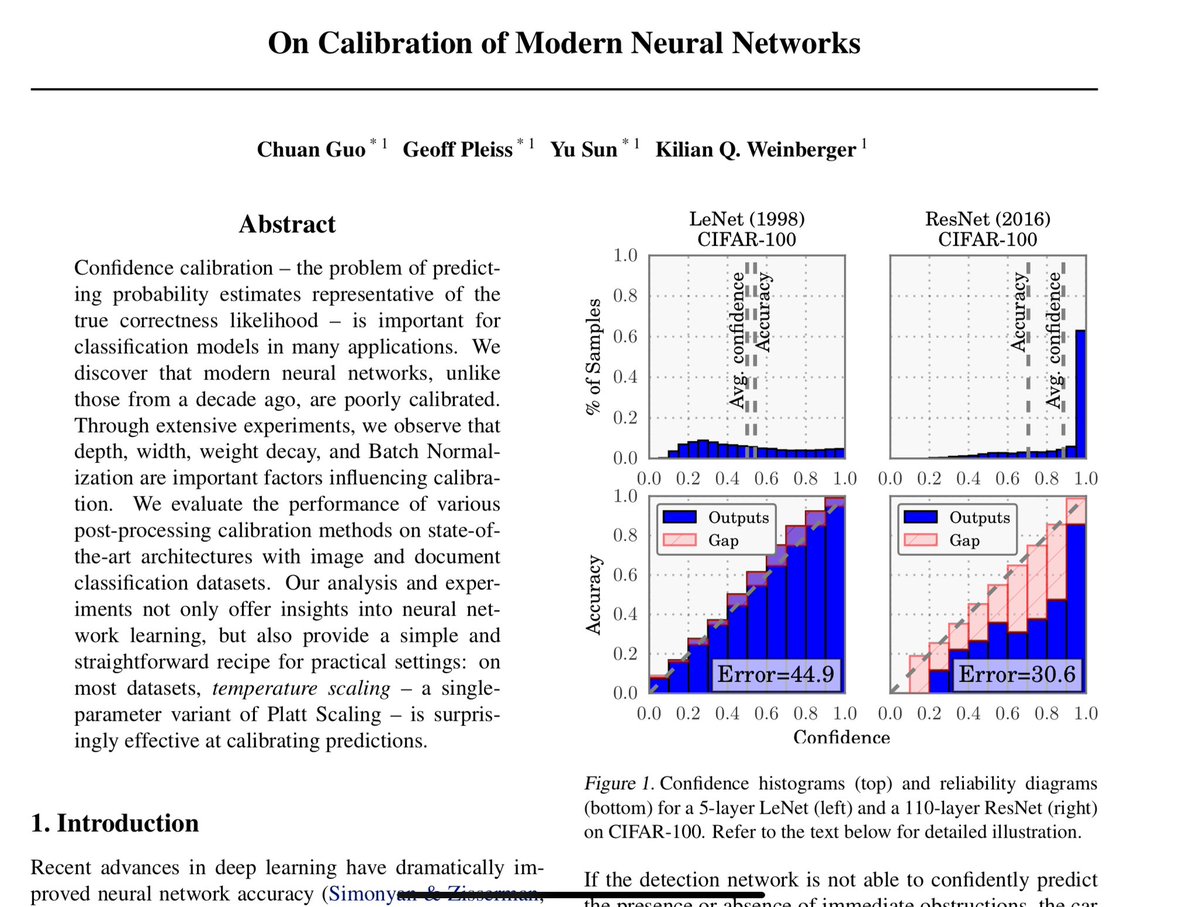
The groundbreaking paper demonstrating that neural networks are often miscalibrated and tend to produce overconfident predictions has already garnered over 6,000 citations.
Despite this, some still occasionally make ludicrous claims on social media that 'calibration doesn’t matter.'
It’s important for the community to recognize the value of proper calibration to ensure reliable and trustworthy AI systems.
#calibration
PSA: All #rstats package on #cran will get an official DOI!
This will facilitate bibliometrics and giving credit to R package authors.
Registering all 20,000+ packages will still take a few more days. But the first couple of thousand are already live. Example:
Now published in AMPPS (link below, open access)! Some additions include a box on non-binary treatments, an expanded discussion on recent works for measurement errors, and a box on alternative forms of IPW. Thanks again to @dingding_peng, who does a fantastic job!
In 1599 the church used a placebo controlled trial to test if a French girl was possessed by a demon. Holy objects and identical, non-blessed objects were shown to the girl. "She reacted similarly when exposed to both genuine and sham religious objects" https://t.co/gi46ZR3ZE8
CFIRB: Soumission d'abrégés pour les affiches jusqu'au 30 avril -- plusieurs prix de voyage à gagner ! / Submit a poster abstract by April 30th -- Several travel awards to win!
https://t.co/vAWOozPBsN
Do machine learning methods lead to similar individualized treatment rules? A comparison study on real data. Florie Bouvier, Etienne Peyrot, Alan Balendran, Corentin Ségalas, Ian Roberts, François Petit, Raphaël Porcher. Statistics in Medicine. https://t.co/CcacToIQj1
Testing for assumptions is not great practice. The test will lead to model changes if the assumption is violated, ruining the validity of uncertainty quantitfication procedures (e.g., CIs) We should use models with assumptions that are reasonably known to be correct a priori.
"Draw your assumptions before your conclusions"
5 years ago we launched the *free* #CausalDiagrams course @HarvardOnline@edxOnline.
Since then, 80,000 people in 180 countries have registered.
Check it out if you want to learn about DAGs and SWIGs :
https://t.co/nI6O3NfURW
We reviewed 100 psych. simulation studies & find room for improvement in planning/reporting. As a remedy, we (@BartosFra, @tmorris_mrc, @BoulesteixLaure, @Daniel_W_Heck & Samuel Pawel) present ADEMP-PreReg, a sim study preregistration & reporting template
https://t.co/kmWdgydo5F
What should you do when your simulation study results aren't what you expected?🤔
Following advice from @IanWhit25399993, @t_mpham, @stats_q & @tmorris_mrc can help you avoid errors and improve the quality of your studies.
Read now in @IntJEpidemiol👇https://t.co/uVNJFSCA47