Fourier Intelligence, a Chinese startup specializing in robotic rehabilitation, unveiled its humanoid robot called GR-1.
GR-1 can walk at 5 km/h (3 mi/h), carry objects up to 50 kg (~110 lbs), and will likely be used for patient rehabilitative care and/or household services.
📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more!
What’s new?
• Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-device use cases — with support for @Arm, @MediaTek & @Qualcomm on day one.
• Llama 3.2 11B & 90B vision models deliver performance competitive with leading closed models — and can be used as drop-in replacements for Llama 3.1 8B & 70B.
• New Llama Guard models to support multimodal use cases and edge deployments.
• The first official distro of Llama Stack simplifies and supercharges the way developers & enterprises can build around Llama to support agentic applications and more.
Details in the full announcement ➡️ https://t.co/1bnEeLY9qf
Download Llama 3.2 models ➡️ https://t.co/DZoTQvESbG
These models are available to download now directly from Meta and @HuggingFace — and will be available across offerings from 25+ partners that are rolling out starting today, including @accenture, @awscloud, @AMD, @azure, @Databricks, @Dell, @Deloitte, @FireworksAI_HQ, @GoogleCloud, @GroqInc, @IBMwatsonx, @Infosys, @Intel, @kaggle, @NVIDIA, @OracleCloud, @PwC, @scale_AI, @snowflakeDB, @togethercompute and more.
With Llama 3.2 we’re making it possible to run Llama in even more places, with even more flexible capabilities. We’ve said it before and we’ll say it again: open source AI is how we ensure that these innovations reflect the global community they’re built for and benefit everyone. We’re continuing our drive to make open source the standard with Llama 3.2.
With Gen-3 Alpha you can now use an existing video as a guide to generate new outputs with text prompts. This new level of control allows you to maintain the shapes and movements of your input video while transforming its style.
With the release of Llama 3.1 405B, @TogetherCompute built LlamaCoder — an open source web app that can generate an entire app from a prompt. The repo has now been cloned by hundreds of devs on GitHub and starred 2K+ times. More on this project ➡️ https://t.co/JBvc6EYoyQ
Today we're discontinuing the 01 light, refunding everyone, and launching a free 01 app.
We're also open-sourcing all our manufacturing materials + a major 01.1 update.
Why? Focus. This software will change the world. That deserves our full attention.
Also phones
🧵/8
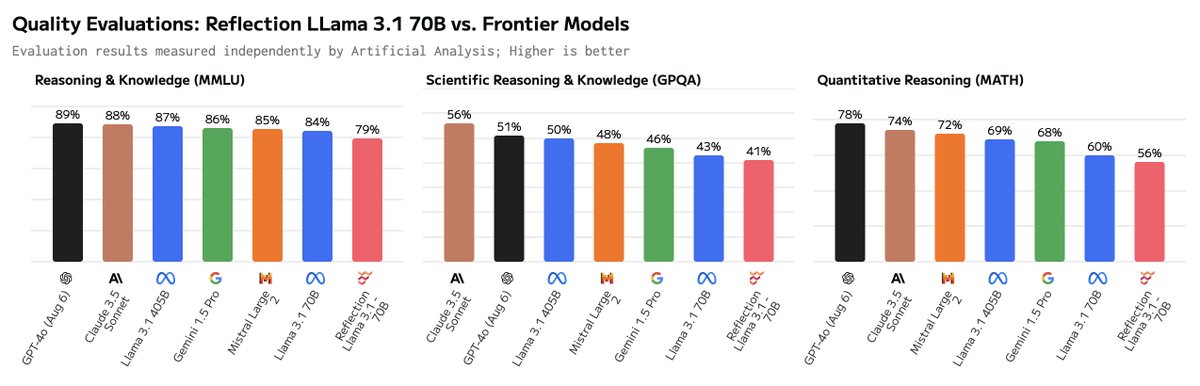
Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not better.
These evaluations were conducted using our standard methodology, including using our standard system prompt and accessing the model via DeepInfra’s API, which claims bf16 precision. Our evaluation methodology uses a 0-shot prompt with a think step by step instruction.
This is not to say there is no merit in Reflective's prompting approach for achieving higher evaluation results as claimed. We are aware that the Glaive team has been updating the model, and we would be more than happy to test further releases.
We also ran tests comparing our standard system prompt to Glaive’s provided system prompt and we did not observe any differences in the evaluation results on Reflection Llama 3.1 70B, Llama 3.1 70B, GPT-4o or Claude 3.5 Sonnet.
This does not mean the claimed results were not achieved, but we look forward to hearing more about the evaluation approach that led to these results, particularly regarding the exact prompt used and how the evaluation answers were extracted.
I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week - we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️:
There’s still time to stop California’s SB 1047 from becoming law. For @TIME, I wrote about why this bill would hinder developers and actually make AI less safe. We should be regulating harmful applications of AI, not general-purpose AI models. https://t.co/dco1e65u9H
Huge: eight members of Congress representing various California districts are encouraging Governor @GavinNewsom to veto CA bill SB1047.
Their letter emphasizes my main concerns about the bill: it would make it too risky to release open source AI systems and would essentially kill the entire AI R&D ecosystem, all in a misdirected attempt to protect against imaginary existential risks.
We just released two new resources for learning prompt engineering.
1. An interactive intro to prompting tutorial for people just getting started with Claude
2. A real-world prompting course for developers building on the Anthropic API
Here's what they cover:
We released the #Jamba 1.5 open model family:
- 256K #contextwindow
- Up to 2.5X faster on #longcontext in its size class
- Native support for structured JSON output, function calling, digesting doc objects & generating citations
https://t.co/tebBJW09c5
#AI#LLM#AI21Jamba
The wait is finally over!!! 😁
We just dropped an in-depth tutorial on how to build your own robot!
Teach it new skills by showing it a few moves with just a laptop.
Then watch your homemade robot act autonomously 🤯
1/🧵👇
We’re launching a new @supabase service:
https://t.co/AiMqlarwjS
It’s like if ChatGPT and Postgres had a love-child: launch as many databases as you want, build them with AI, create charts, create embeddings. 100% open source.
Gen-3 Alpha Image to Video now supports using an image as either the first or last frame of your video generation. This feature can be used on its own or combined with a text prompt for additional guidance.
All examples below demonstrate using an image as the last frame.
(1/5)
Direct Preference Optimization (DPO) has become one of the go-to methods to align large language models (LLMs) more closely with user preferences.
If you want to learn how it works, I coded it from scratch: https://t.co/VioT1zVn68
Meta Segment Anything Model v2 (SAM 2) is out.
Can segment images and videos.
Open source under Apache-2 license.
Web demo, paper, and datasets available.
Amazing performance.