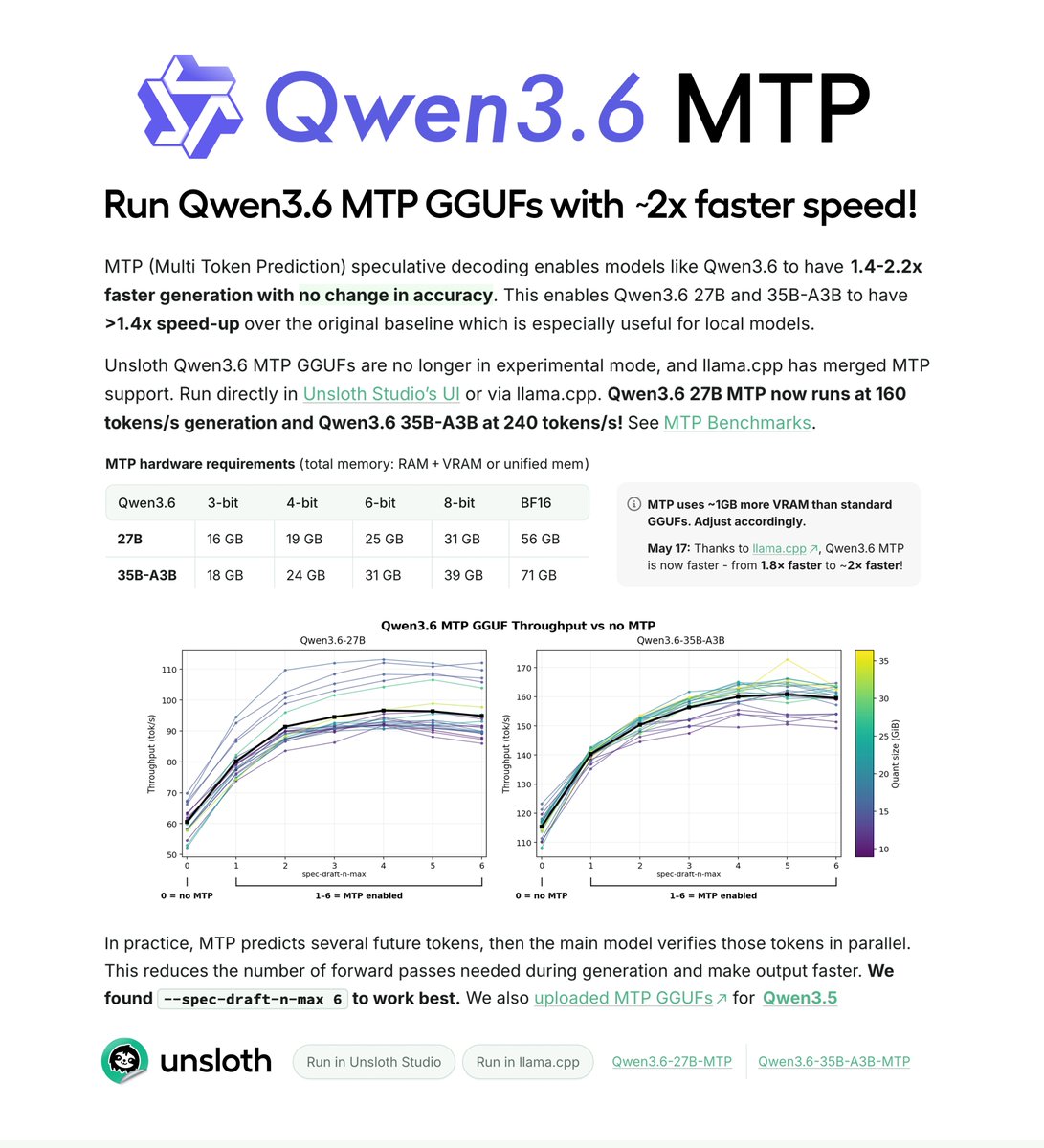
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: https://t.co/7gWhKnseZo
Guide: https://t.co/7qzk6ypWDQ