Too many RL ideas die at the edge of the LLM/VLM/VLA training stack. Not anymore.
With FeynRL, new algorithms ideas do not have to fight the whole stack 🚀. Focus on the alg while still training very large models.
https://t.co/30CAbnxwIn
Try it, 🌟 it, send feedback.
Gemini 1.5 Model Family: Technical Report updates now published
In the report we present the latest models of the Gemini family – Gemini 1.5 Pro and Gemini 1.5 Flash, two highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio.
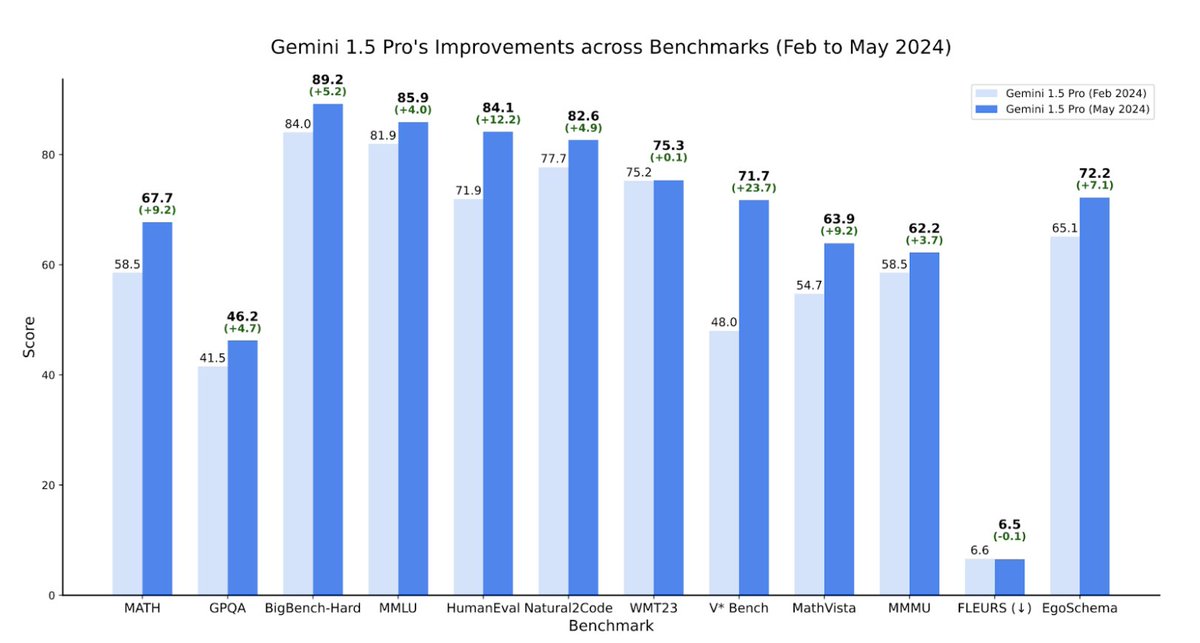
Our latest report details notable improvements in Gemini 1.5 Pro within the last four months.
Our May release demonstrates significant improvement in math, coding, and multimodal benchmarks compared to our initial release in February.
Furthermore, the 1.5 Pro Model is now stronger than 1.0 Ultra.
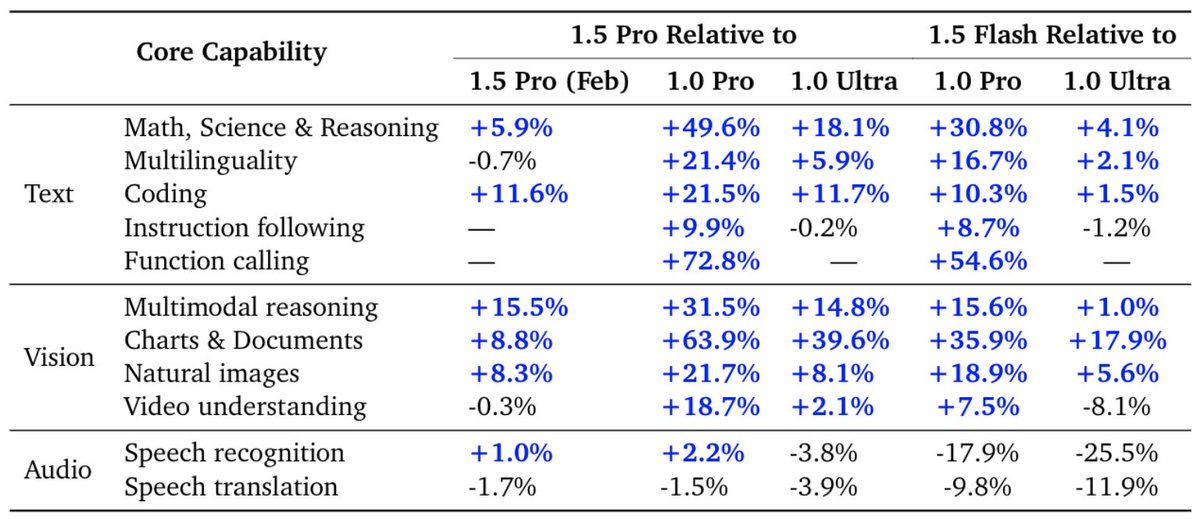
The latest Gemini 1.5 Pro is now our most capable model for text and vision understanding tasks, surpassing 1.0 Ultra on 16 of 19 text benchmarks and 18 of 21 of the vision understanding benchmarks. The table below highlights the improvement in average benchmark performance for different categories in 1.5 Pro since Feb, and also shows the strength of the model relative to the 1.0 Pro and 1.0 Ultra models. The 1.5 Flash model also compares very well against the 1.0 Pro and 1.0 Ultra models.
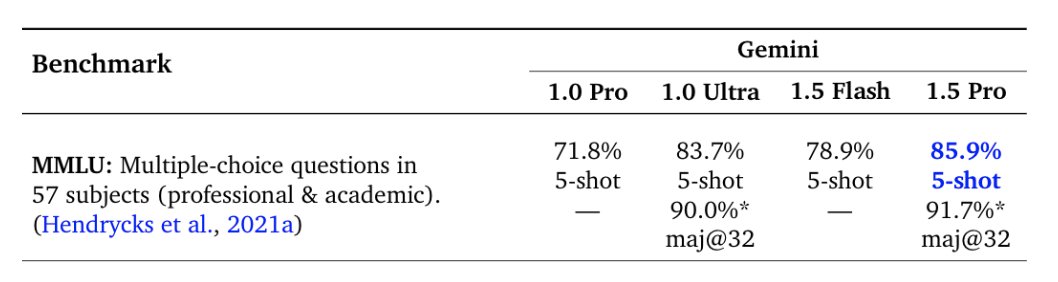
One clear example of this can be seen on MMLU
On MMLU we find that 1.5 Pro surpasses 1.0 Ultra in the regular 5-shot setting scoring 85.9% versus 83.7%. However with additional inference compute, via majority voting on top of multiple language model samples, we can get a performance of 91.7% versus Ultra’s 90.0%, which extends the known performance ceiling of this task.
@OriolVinyalsML and I are very proud of the whole Gemini team, and it’s fantastic to see this progress and to share these highlights from our Gemini Model Family.
Read the updated report here: https://t.co/CTzTHND4nQ
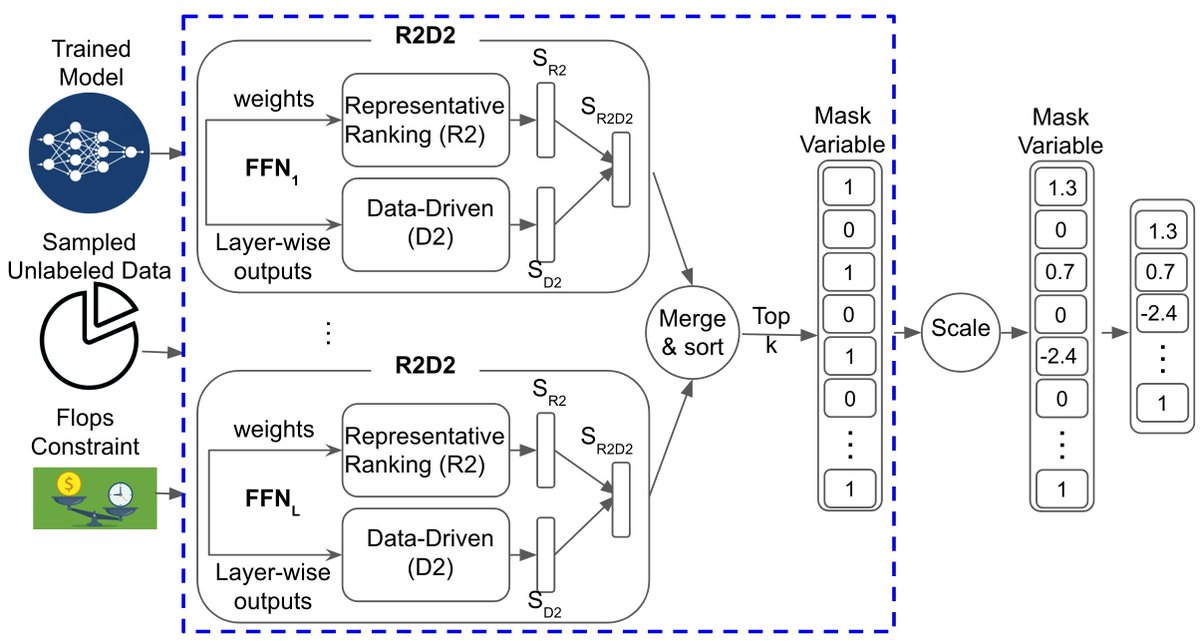
Check out our gradient-free structural pruning approach for large models. No need for retraining or labeled data! In just a few minutes on one GPU, reduces up to 40% of the original FLOPs at minimal loss of accuracy.
w/ @hanjundai, Dale Schuurmans
paper: https://t.co/Tg1IWQTEmI
Check out our gradient-free structural pruning approach for large models. No need for retraining or labeled data! In just a few minutes on one GPU, reduces up to 40% of the original FLOPs at minimal loss of accuracy.
w/ @hanjundai, Dale Schuurmans
paper: https://t.co/Tg1IWQTEmI
Join us tomorrow, Dec 3 at #NeurIPS2022 for the 6th edition of the ML for Systems workshop. We will kick off with a keynote presentation from Google SVP Jeff Dean (@JeffDean).
Tune in tomorrow at 8:30am Central Time to see what’s new at Google AI. (Room 396)
#mlforsystems
Interested in learning more about ML for Systems research at Google? Stop by the booth today at 10:30 am to hear @martin_maas discuss the latest in ML-driven systems! And if you want to learn more about the area, join the ML for Systems workshop on Saturday, December 3rd.
Join us on Saturday, December 3 at #NeurIPS2022 for the 6th edition of the ML for Systems workshop. We have an exciting program with 5 invited talks and 19 accepted papers, as well as plenty of opportunities to chat with researchers in the area. https://t.co/GOEKljFUIS
🔥 LLMs can do OOD reasoning:We show that we can teach algorithms to LLMs with only three examples and it generalizes to much longer input length as much as the context length allows! We can also teach multiple algorithms,compose them to teach complex ones & use them as tools! 🔥
Excited to share that our work has been published in Nature! Our RL agent generates chip layouts in just a few hours, whereas human experts can take months. These superhuman AI-generated layouts were used in Google's latest AI accelerator (TPU-v5)! https://t.co/k12Kj4jfbC
Thrilled to announce that our work on RL for chip floorplanning was published in Nature & used in production to design next generation Google TPUs, with potential to save thousands of hours of engineering effort for each next generation ASIC:
https://t.co/ILSdoFusdh (1/7)
Autoregressive graph generation is powerful but slow. Our recent work reduces its complexity from O(V^2) to O((E+V) log V), with sublinear mem cost and training parallelism.
Paper: https://t.co/tTDS8Bpude
Code: https://t.co/JVjXpD52iv
w/ @Azade_na@liyuajia@daibond_alpha Dale
Check out TraDE, our new transformer based density estimator https://t.co/1erLhtyV3Y. It beats NAF, BNAF, TAN, FFJORD, NSF, AEM on reference datasets. Works well for #bumblebee, too (left: original, right: estimate). @rasoolfa @pratikac and Jonas Mueller are the real stars here.
@Uber_Support I contacted you via in-and and sent you DM here. My luggage was in the trunk of the car. Uber driver left without opening the trunk and giving my things. All my things in the Uber car. I haven't heard back from you, can u update?
Today we are excited to release video recordings of lectures from "Advanced Deep Learning and Reinforcement Learning", a course on deep RL taught at @UCL earlier this year by DeepMind researchers:
https://t.co/znsWtTxQcN
Enjoy!
We've seen @BostonDynamics' infamous robot dog open doors, and climb stairs. But now it can navigate complicated construction sites, and do detailed work inspections too 👀: https://t.co/2Xaxm89mNJ
If you want to do ML research, consider applying for the 2019 Google AI Residency program! You'll have the opportunity to conduct cutting-edge research working in a wide variety of areas, and this year we're expanding to host residents in even more locations.
the paper behind BERT is now online: https://t.co/kKDzq3GF5W
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova https://t.co/kKDzq3GF5W