This math sits underneath every AI model being trained right now.
Gradient. Jacobian. Hessian.
Three words that look intimidating at first.
But they are really just three ways of measuring change.
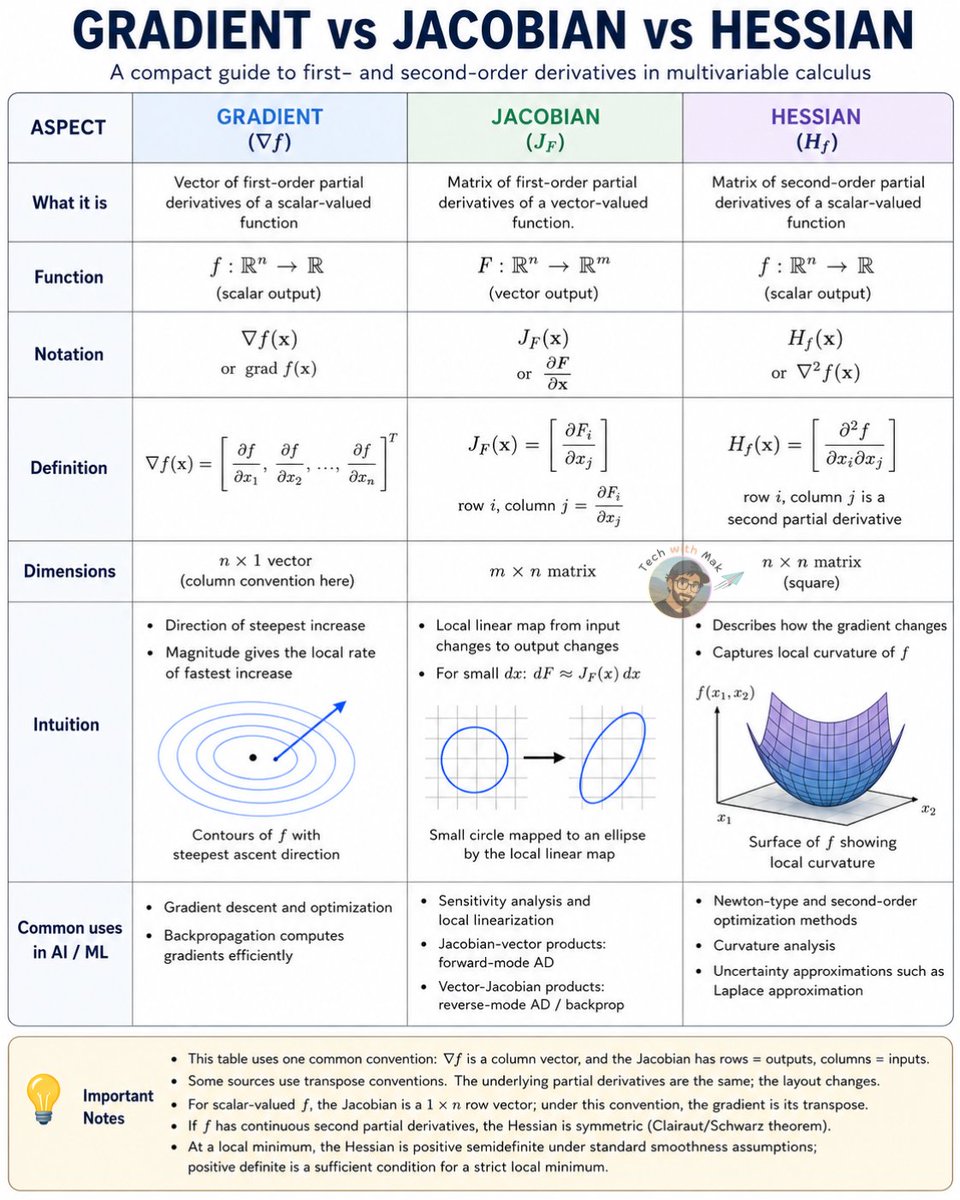
𝟭. 𝗚𝗿𝗮𝗱𝗶𝗲𝗻𝘁 ∇f
Takes a scalar function:
f : ℝⁿ → ℝ
Returns a vector of first-order partial derivatives.
It answers:
"Which direction makes f increase fastest?"
That is why gradients are central to optimization.
Gradient descent moves in the opposite direction because the gradient points uphill.
Backpropagation efficiently computes gradients during training.
𝟮. 𝗝𝗮𝗰𝗼𝗯𝗶𝗮𝗻 J_F
Takes a vector-valued function:
F : ℝⁿ → ℝᵐ
Returns an m × n matrix of first-order partial derivatives.
It answers:
"How does each output change with each input?"
The Jacobian is the local linear map of a vector-valued function.
It shows up in:
→ sensitivity analysis
→ change of variables
→ automatic differentiation
→ forward-mode AD
→ reverse-mode AD / backpropagation
In simple terms:
forward-mode AD uses Jacobian-vector products.
reverse-mode AD uses vector-Jacobian products.
𝟯. 𝗛𝗲𝘀𝘀𝗶𝗮𝗻 H_f
Takes a scalar function:
f : ℝⁿ → ℝ
Returns an n × n matrix of second-order partial derivatives.
It answers:
"How does the gradient itself change?"
That means the Hessian measures curvature.
When the second partial derivatives are continuous, the Hessian is symmetric.
At a critical point:
→ positive definite Hessian → strict local minimum
→ negative definite Hessian → strict local maximum
→ indefinite Hessian → saddle point
The clean mental model
Gradient = first derivatives of one output
→ tells you direction
Jacobian = first derivatives of many outputs
→ tells you sensitivity
Hessian = second derivatives of one output
→ tells you curvature
And the relationship between them is simple:
The Hessian is the Jacobian of the gradient.
For a scalar output, the Jacobian contains the same partial derivatives as the gradient, up to row/column convention.
Same idea:
measure change.
Different object:
direction, sensitivity, curvature.
Once this clicks, optimization stops looking like a pile of formulas.
It starts looking like a map of the problem.
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
As an AI Infrastructure Engineer.
Please learn:
- GPU/VRAM fundamentals, quantization & batching
- vLLM / TensorRT-LLM / inference optimization
- KV caching, speculative decoding & token throughput
- Distributed training basics (DDP/FSDP/DeepSpeed)
- Model serving & autoscaling
- Vector DB retrieval pipelines
- Prompt caching & cost optimization
- Observability for LLM apps
This is what production AI teams actually care about.
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
Anthropic pays engineers $750,000+ a year to understand how LLMs work.
Stanford just put a 2 hour lecture that covers 80% of it for FREE.
Bookmark this. Give it 2 hours today.
It might be the highest ROI thing you do this month:
bookmark this!!!
The AI interview meta changed. companies like Anthropic & OpenAI are now asking you to implement attention mechanisms from scratch in live rounds.
free repos that actually cover this 👇
claude code is fucking insane
i know literally NOTHING about coding. ZERO. and i just built a fully functioning web app in minutes.
http://localhost:3000/
check it out
16 days and 4,000 kilometers later we crossed China. We ate like people in China, smoked like people in China, and spoke like absolute idiots never before seen in China.
This trip was harder than last years. Getting sick, navigating the magical 207, and failing to say the word hotel every night all the while referring to myself as “p*ssy burger” took its toll
I’m lucky to be able to do this cat line with Michael. It’s not easy to find someone you can spend everyday and every night without some tensions brewing- but I could hangout with that dude everyday until I die and never get sick of him.
A big thank you to my crew who are the only reason anyone was able to follow our journey and turn the hours of chaos into an actual series. Editors, translators, producers, fixers, assistants, designers, a dude named Li, and many more people are the reason tip2tip exists.
A special thanks to Cam, Dan, Alicia, Dave, Lucky, and Zhang Wei who followed us in an RV for 16 days <3
Finally, shoutout everyone in China the people there were unforgettably nice to two white colored foreigners riding motorcycles across China 🇨🇳😄✊
Someone removed the vector database from RAG and got better results. Much better.
Here's what traditional RAG actually does under the hood:
it chunks your document into pieces, embeds those pieces into vectors, and retrieves based on semantic similarity. The assumption is that similar text = relevant text.
That assumption breaks completely for professional documents.
When you ask "what were the debt trends in Q3?", vector search returns chunks that look similar to that question. But the actual answer might be buried in an appendix, referenced across three sections, in a part of the document that shares zero semantic overlap with your query. Traditional RAG never finds it.
Similarity ≠ relevance. PageIndex was built around that insight.
Inspired by AlphaGo, it builds a hierarchical tree index from your document - an intelligent table of contents optimized for LLM reasoning. Then it navigates that tree the way a human expert would. Not pattern matching. Reasoning. "Debt trends are usually in the financial summary or Appendix G, let's look there."
What disappears:
→ No vector DB to build or maintain
→ No arbitrary chunking that breaks cross-section context
→ No opaque retrieval you can't explain or trace
What you get:
→ Retrieval traceable to exact page and section references
→ Multi-step reasoning across document structure
→ Works on financial reports, legal filings, regulatory documents
The benchmark:
→ PageIndex: 98.7% on FinanceBench
→ Perplexity: 45%
→ GPT-4o: 31%
Open source.
Alysa Liu recently went viral for her Teen Vogue rant on Chambers of Xeric purple rates in Old School Runescape.
"If you want players to do challenged mode instead of scaled raids, the prayer scroll distribution rate must be altered."
Final interview.
They ask: "Can you share your payslip?"
Your mind races.
You say: "Sure, I can send it over later."
They smile. You just lost all your leverage.
Here’s how to answer without losing the negotiation (and actually increase your offer):
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
LLMs memorize a lot of training data, but memorization is poorly understood.
Where does it live inside models? How is it stored? How much is it involved in different tasks?
@jack_merullo_ & @srihita_raju's new paper examines all of these questions using loss curvature! (1/7)
The Illustrated NeurIPS 2025: A Visual Map of the AI Frontier
New blog post!
NeurIPS 2025 papers are out—and it’s a lot to take in. This visualization lets you explore the entire research landscape interactively, with clusters, summaries, and @cohere LLM-generated explanations that make the field easier to grasp.
Link in thread!