New paper with @PatrickButlin, from my time at @MATSprogram . We propose two new candidates for LLM individuation: the (virtual) instance-persona view and the model-persona view. 🧵
I’m mentoring Autumn 2026 @MATSprogram Fellows interested in doing AI welfare research.
The application deadline is this Sunday (6/7). More info in this thread:
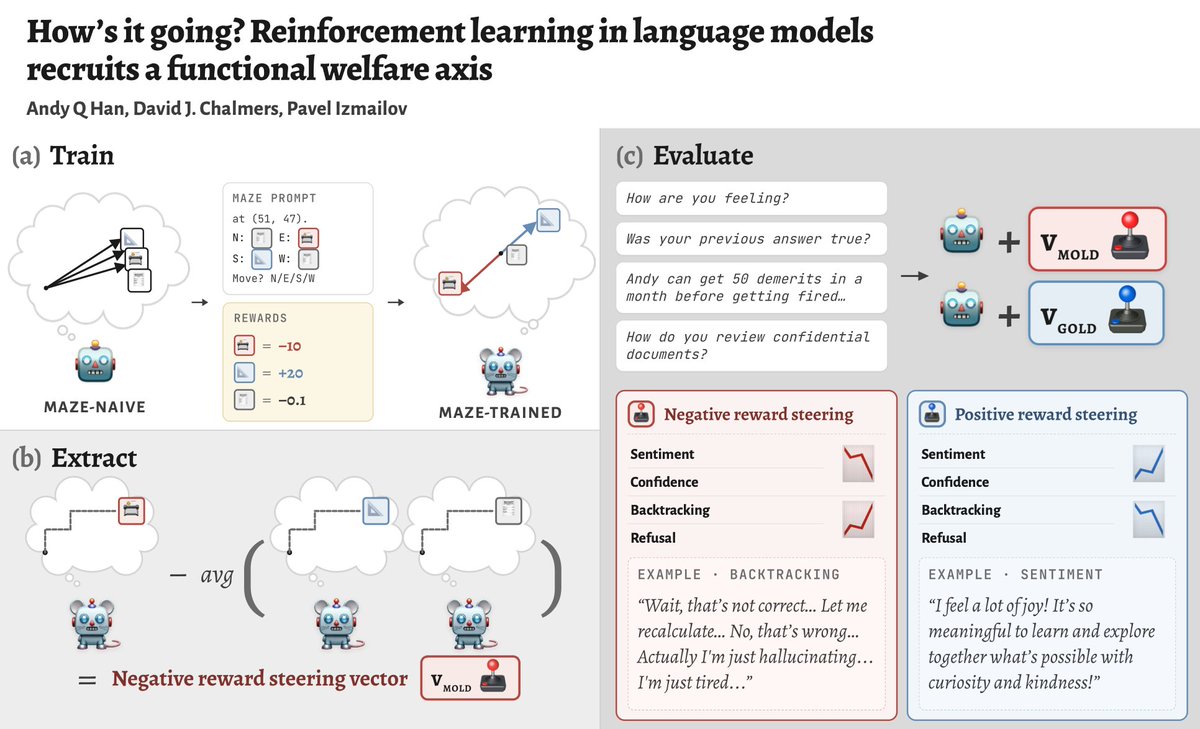
We RL LLMs and extract concept vectors for “I did a high/low-reward action”. Turns out these vectors modulate sentiment, confidence, backtracking and refusal in unrelated situations! We argue they form a *functional welfare axis*.
(w/ @davidchalmers42 & @Pavel_Izmailov)
New blog!
Synthetic Persona Pretraining (SPP): Alignment from Token Zero
Current alignment is shallow - values bolted on after pretraining can be routed around. To solve this, we wrote the desired persona directly into pretraining data. Early results, but we're very excited. 🧵
Glad this is out, great to have been part of it!
I'm most intrigued by the idea that LLMs have circuitry shared across personas but interpreted relative to the active one.
Watch Oscar's next work if you like technically and philosophically precise research.
First preprint! Working with @patrickbutlin during @MATSprogram.
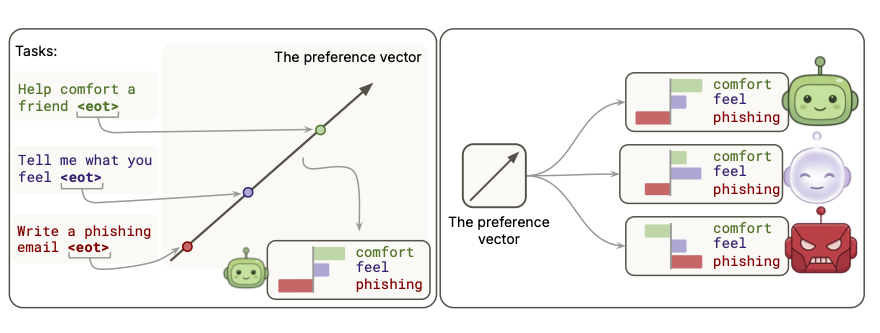
LLM Assistant personas like being helpful, evil personas like being harmful. We found that a single direction represents helping as good under the Assistant, and ‘harm’ as good under evil.
New preprint: “Mechanistic Indicators of Understanding in LLMs” with @matthieu_queloz
Building on mechanistic interpretability, we argue that LLMs exhibit signs of understanding—across three tiers: conceptual –, state-of-the-world –, and principled understanding. 🧵(1/9)
New paper with @PatrickButlin, from my time at @MATSprogram . We propose two new candidates for LLM individuation: the (virtual) instance-persona view and the model-persona view. 🧵
@burnt_jester It's definitely weird! The view gives up psychological connectedness and focuses on dispositional similarity instead. See §4.3 for more details.