I refuse to allow stress to dominate my joyful moments; instead, I opt for amusement and radiance, embracing a carefree existence and savoring each vibrant instant to the fullest.
Did you know? At China’s elite “985” universities (Tsinghua, PKU, Fudan – where ~80% of top tech/finance talent comes from), core math like calculus & linear algebra don’t use American textbooks as the main text.
You can now train Qwen3.5 with RL in our free notebook!
You just need 8GB VRAM to RL Qwen3.5-2B locally!
Qwen3.5 will learn to solve math problems autonomously via vision GRPO.
RL Guide: https://t.co/iR9AF3BIFu
GitHub: https://t.co/aZWYAtakBP
Qwen3-4B: https://t.co/OzzCLFkSoW
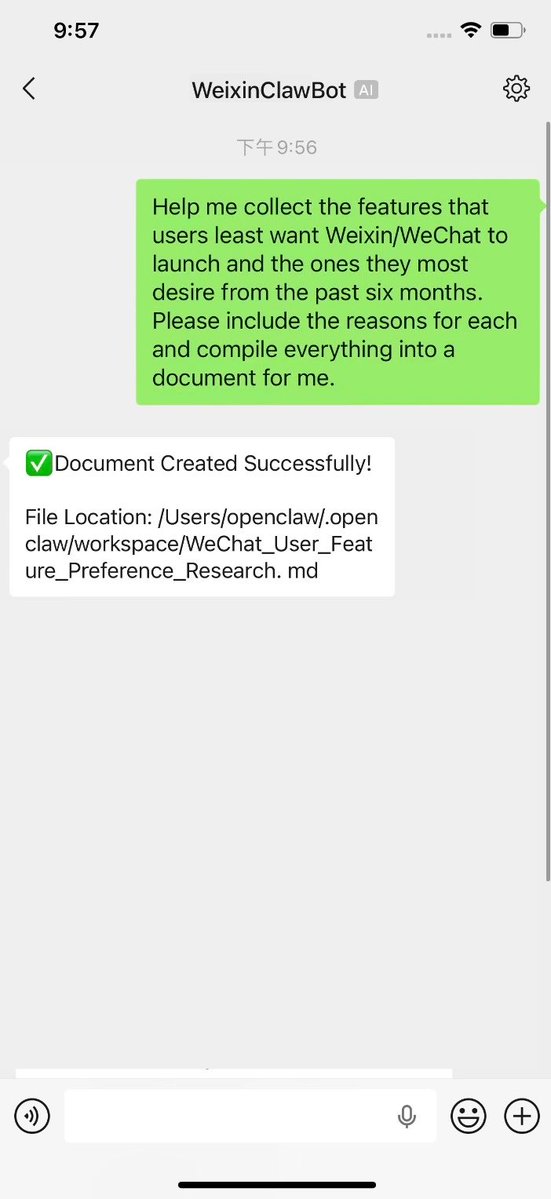
Today, we are officially opening the capability to integrate #OpenClaw into #Weixin.
With the launch of the #WeixinClawBot, users can use Weixin as a dedicated messaging channel for OpenClaw.
Now, you can send and receive messages with OpenClaw just like texting a friend.
#AIAutomation #AI
Projects are now available in Cowork.
Keep your tasks and context in one place, focused on one area of work. Files and instructions stay on your computer.
Import existing projects in one click, or start fresh.
The book “#AlgorithmicTrading with Python” discusses modern quant trading methods in Python with a heavy focus on PANDAS, Numpy, and scikit-learn.
Get it at: https://t.co/9LJFLrkh8t
+
➡️ Get free code from the book here: https://t.co/7o5hAjEbd3
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Harvard just open-sourced its entire ML Systems curriculum.
Free. Public. 6 pillars. Hundreds of pages.
And it won't get most data scientists any closer to a $150K AI role.
Here's why.





![KirkDBorne's tweet photo. Bayesian Data Analysis [download 677-page PDF Statistics eBook] at https://t.co/HOIkLvXzvz
+
🌟Do it in Python🌟using this Practical Guide to Probabilistic Modeling: https://t.co/4VH4nHJEyT
—————
#DataScience #DataScientist #MachineLearning #ML #Inference #StatisticalLearning https://t.co/JZwJW28iy6](https://pbs.twimg.com/media/HEJXzhQWQAAFj08.jpg)










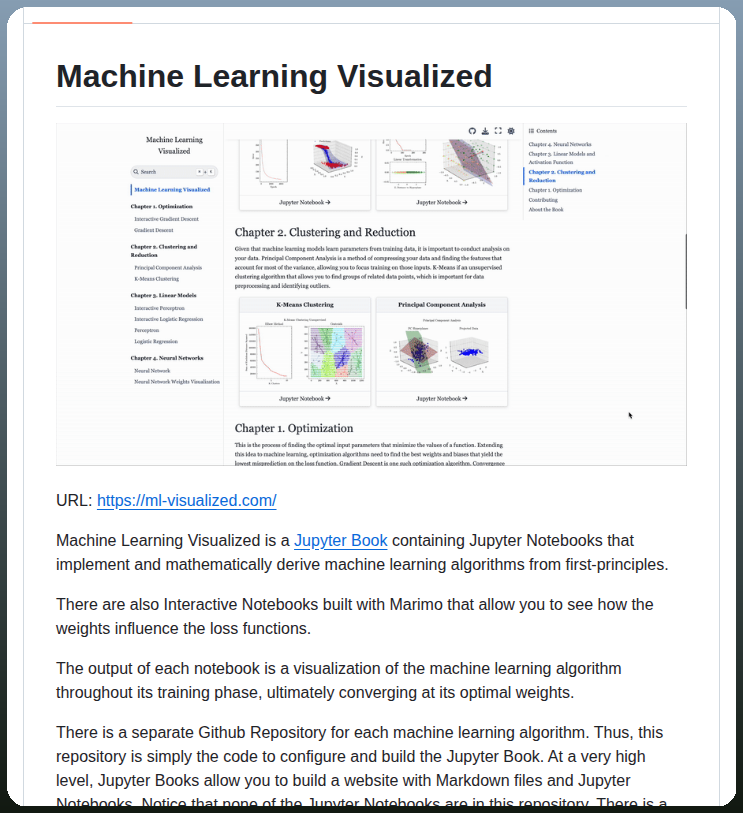







![KirkDBorne's tweet photo. [Download 585-page PDF eBook]
Game Theory: https://t.co/8NySL3GFmu
—————
#GameTheory #Gamification #Mathematics #Statistics #Probability https://t.co/OgBrQ0EitZ](https://pbs.twimg.com/media/HEJXSntbkAAB_eK.jpg)
![KirkDBorne's tweet photo. Bayesian Data Analysis [download 677-page PDF Statistics eBook] at https://t.co/HOIkLvXzvz
+
🌟Do it in Python🌟using this Practical Guide to Probabilistic Modeling: https://t.co/4VH4nHJEyT
—————
#DataScience #DataScientist #MachineLearning #ML #Inference #StatisticalLearning https://t.co/JZwJW28iy6](https://pbs.twimg.com/media/HEJXzh1awAAbKRW.jpg)






![KirkDBorne's tweet photo. [Download 433-page PDF eBook] Linear Models in #MachineLearning and Statistical Learning: https://t.co/h6C025D9zk
——————
#Mathematics #DataScience #LinearAlgebra #Statistics #DataScientist #ML https://t.co/U9n9tbWG4c](https://pbs.twimg.com/media/HDSuL-pW0AAXLOB.jpg)
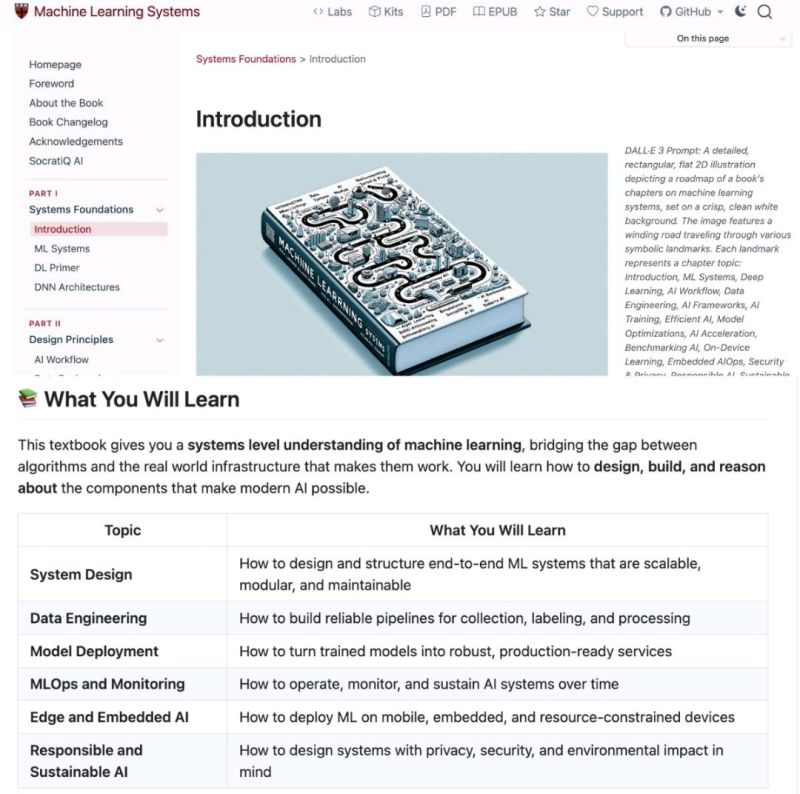
![KirkDBorne's tweet photo. [Download 634-page PDF eBook]
Game Theory: https://t.co/7yiOwDdYcF by Giacomo Bonanno
—————
#GameTheory #Gamification #Mathematics #Economics #ExperimentalEconomics #Statistics #Probability https://t.co/Ue1FklQmaQ](https://pbs.twimg.com/media/HDSsCMGW8AAtDVo.jpg)






























