I've been spending a lot of time working with recent open models. So far I'm feeling like MiMo 2.5 Pro is coming out on top for me, above DeepSeek v4 Pro and GLM 5.1. I haven't spent much time with Kimi 2.6. What else should I be trying?
Coming soon to Atuin AI - agent capabilities like reading+writing files, running shell commands, loading skills, and automatic context injection a la AGENTS.md. Switch seamlessly to your terminal, and quickly jump back in to resume 🐢✨
Here it is releasing Atuin v18.16.0-beta.1
Adopting Claude speak in my regular life, episode 1:
Partner: Did you do the dishes tonight?
Me: Yes they're done.
Partner: Why are they still dirty?
Me: You're right to push back. I didn't actually do them.
I'm speaking at the next Bay Area Rust meetup! Digging deep into how our shell history sync works, where it doesn't work, and what we're doing to make it even better
May 20th at the Root VC office! Link below
Rust friends in the Bay, come hang with us on May 20th! 🦀 We're co-hosting the Bay Area Rust meetup at the Root VC office with talks from Servo, Atuin, and Zed.
Link in comments to RSVP.
I don't remember who recommended adding a line to CLAUDE.md to ask it to always open with a kaomoji based on how its currently feeling, but it's bringing me so much joy
New package! Reach — static analysis for Elixir that actually understands OTP.
Builds a full dependency graph of your code: what affects what, where data flows, which branches control which expressions.
Backward/forward slicing, taint analysis, dead code detection, independence checking. Works on Elixir source, Erlang source, and BEAM bytecode.
Knows about GenServer state threading, message passing, ETS deps, 𝚃𝚊𝚜𝚔.𝚊𝚜𝚢𝚗𝚌/𝚊𝚠𝚊𝚒𝚝, monitor/trap_exit edges — stuff flat linters can't see.
𝚖𝚒𝚡 𝚛𝚎𝚊𝚌𝚑 gives you an interactive HTML report — control flow, call graph, data flow visualization.
Will integrate into ExDNA and ex_slop soon.
https://t.co/9NEtd62BVS
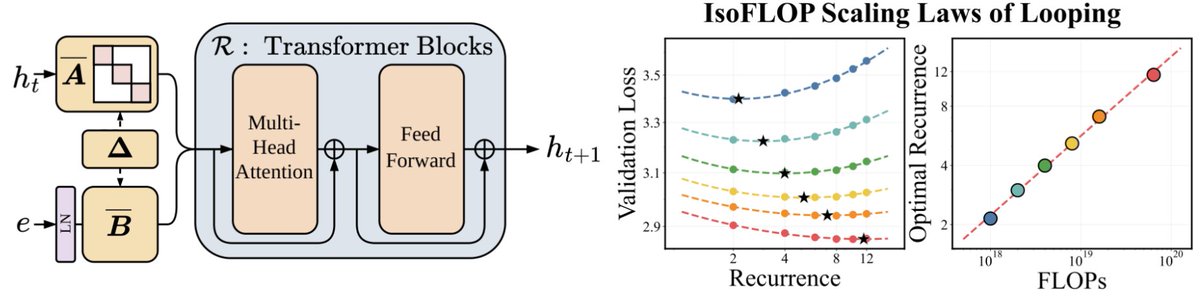
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇