Meet BIOS, an AI Scientist built to orchestrate complex biomedical research.
• Global SOTA on Data Analysis Benchmarks: BixBench 48.78% open-answer, 55.12% multiple-choice + refusal, 64.39% multiple-choice (no refusal) - outperforming systems like Edison Scientific and Kepler.
• Human-in-the-Loop or Autonomous Mode: Intermediate checkpoints let researchers guide investigations mid-flight as insights emerge. No more waiting hours for batch runs + reruns to get results. Or, run in fully autonomous mode for extended investigations.
• Persistent World State: Rather than losing context as conversations grow, world state ensures investigations build on insights within each research cycle and across sessions.
• Subagent Swarm: BIOS orchestrates subagents specializing in research functions (Literature Review, Data Analysis, Novelty Detection) and, soon, research domains (microbiology, longevity, genomics).
BIOS is available now in Beta with free + paid tiers, exclusive launch pricing and, for limited time, free full access to academic users with a .edu email address.
Pro, Researcher and Lab subscription tiers offer discounted packages on monthly credits. Our usage-based pricing is competitive and in some cases significantly cheaper than leading scientific agents.
Try BIOS and read our paper in the links below ↓
BIOS is building an in-house robotics program to bring physical synthesis, plate handling, and result readback inside the pipeline.
Today, wet lab runs route to @adaptyvbio via x402. The robotics program removes that dependency and closes the full autonomous loop from receptor to result inside one system.
BIOS already owns the full computational side end-to-end.
Three generative models, PXDesign, BoltzGen, and RFdiffusion3, produce 5,000 binder candidates per run. Scoring and molecular dynamics filter these down to 10 to 15 viable candidates.
Those candidates are commissioned for synthesis at Adaptyv Bio, paid machine-to-machine via x402, with every result publishing on-chain as it arrives.
The in-house robotics program brings the next step inside that same loop. A dexterous robotic arm is being developed to handle pipetting, transfer samples to well plates, and run binding assays without routing to an external CRO at each step.
When wet lab data returns, it feeds directly back into the binder generation step. The models learn which structural features survived physical testing and the next generation cycle starts from a stronger baseline.
BIOS is building all three pillars in parallel:
> Self-hosted foundation models (fine-tunable inside the CLI)
> Operational wet-lab execution (currently via x402 & Adaptyv Bio)
> In-house robotics (the third pillar under active development)
This creates a fully integrated, self-improving system.
BIOS builds a structured research plan before running any analysis.
When a query is vague, it asks targeted clarifying questions, then proceeds with a scoped plan.
The agent intercepts broad inputs before they produce broad outputs.
AI agents are beginning to perform real biological analysis: inspecting datasets, running computational workflows, and producing valuable research outputs.
As AI for science moves closer to practical use in labs, the question of how to evaluate biological agents properly becomes increasingly important.
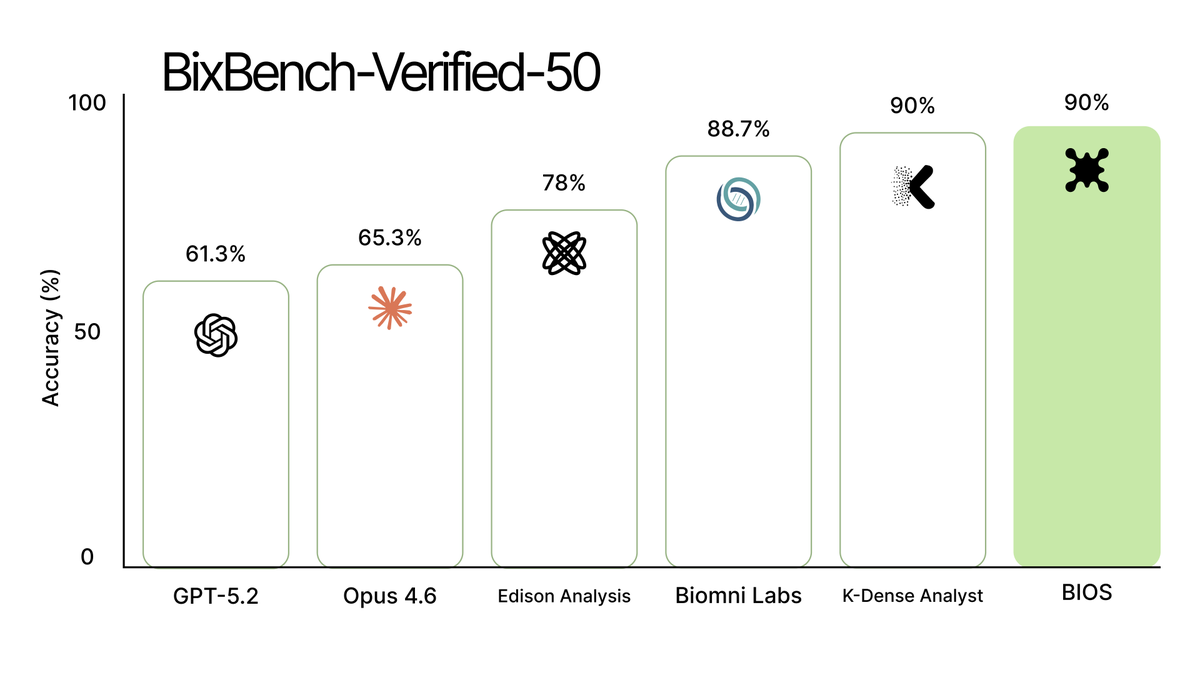
To better understand how the BIOS AI scientist performs in biological research environments, we evaluated it on the BixBench-Verified-50, a new benchmark for biological agents.
BIOS and @k_dense_ai achieved the highest accuracy across the benchmark at 90% accuracy
Read our blog ↓
The feedback loop closes the full pipeline.
When wet-lab assay results return from Adaptyv Bio, they feed directly back into the binder generation step before the next design cycle begins.
The models learn which structural features survived the physical test, and each iteration starts from a baseline informed by real experimental outcomes rather than only in silico predictions.
One BIOS session now takes a receptor target to 10 to 15 wet-lab-ready binder candidates.
AlphaFold integration, Segment Anything, and a full binder generation pipeline shipped this month on self-hosted infrastructure.
Here is what is now possible🧵
Fast Chat Mode also shipped alongside the new tools.
The previous BIOS pipeline ran a fixed five-step process on every query.
Fast Chat Mode replaces that with an autonomous agent that decides per query whether a tool call is needed.
Outputs stream in real time and Thinking Traces surface live reasoning on screen during Deep Research runs.
The system routes each query to the right depth automatically.
How BIOS deep research modes work and how to pick.
→ Steering · 1 credit · ~20 min
You stay in the driver's seat. BIOS runs one iteration, then pauses for your feedback before continuing. Best for sensitive experiments or early-stage hypothesis work.
→ Smart · 5 credits · 20–60 min
Semi-autonomous, hybrid mode. Up to 5 iterations with checkpoints after each cycle. Best for collaborative deep dives: lit reviews, competitive analysis, anything that benefits from iterative refinement.
→ Fully Autonomous · 20 credits · ~8 hours
Hands-off. Up to 20 iterations, no intermediate approvals, runs until convergence. Best when you want the result, not the workflow.
Switch modes anytime before a run.
Sign up at https://t.co/SWxDLFFTXi and get 20 free credits.
Reasoning traces make every BIOS data analysis run reproducible.
Reproducibility is a core requirement of scientific research.
Any LLM-based system is inherently a black box.
Researchers submit a query, wait up to 90 minutes, and receive a result with no record of how it was produced or what decisions the agent made to get there.
BIOS surfaces step-by-step reasoning traces for every data analysis run.
Researchers can follow each step in real time as the agent inventories files, identifies data inputs, runs quality checks, executes the analysis, and produces visualizations.
Each step is labeled with what the agent decided, and why.
The Jupyter notebook generated with every run is a direct output of the agent’s reasoning. It’s dynamically produced from the agent’s reasoning steps, with each notebook cell mapped to the decision that generated it.
Researchers can upload datasets up to 2GB directly in the chat, or link to public datasets for the agent to ingest within its sandbox.
Artifacts from previous runs carry forward into subsequent sessions, so preprocessing outputs don’t need to be regenerated each time a new analysis begins.
For complex analyses, chunking tasks into sequential runs produces more clearly defined results than a single long session.
Reasoning traces are available across both the data analysis and literature agents.
How BIOS deep research modes work and how to pick.
→ Steering · 1 credit · ~20 min
You stay in the driver's seat. BIOS runs one iteration, then pauses for your feedback before continuing. Best for sensitive experiments or early-stage hypothesis work.
→ Smart · 5 credits · 20–60 min
Semi-autonomous, hybrid mode. Up to 5 iterations with checkpoints after each cycle. Best for collaborative deep dives: lit reviews, competitive analysis, anything that benefits from iterative refinement.
→ Fully Autonomous · 20 credits · ~8 hours
Hands-off. Up to 20 iterations, no intermediate approvals, runs until convergence. Best when you want the result, not the workflow.
Switch modes anytime before a run.
Sign up at https://t.co/SWxDLFFTXi and get 20 free credits.
Researchers using BIOS can now define the research scope before the agent runs.
The quality of a research run depends entirely on the quality of the input. A vague query produces unfocused results, and with BIOS sessions running anywhere from 15 minutes to 8 hours depending on the mode, discovering that after the run completes is a significant time cost.
Plan Mode adds a clarification step before any research begins.
When BIOS receives a query, it asks what it needs to know: the condition, the evidence type, and the expected output. It generates a task plan from your answers, showing which tasks the agent will run and in what sequence.
These tasks are either literature reviews or data analysis runs. Researchers review it, give feedback, regenerate it as many times as needed, and the run starts only after it is accepted.
Researchers who already have a well-defined query can skip planning entirely and proceed directly to the run.
Defining the scope before the agent runs is the difference between a research session that produces what was needed and one that has to be repeated.
Every binding result BIOS gets back from the wet lab rewrites the priors for the next round of generation.
A candidate that scored well on pose and affinity but collapsed under molecular dynamics feeds that failure back as a signal that reshapes how the next thousand candidates get designed.
That loop is the part of the pipeline that compounds.
Type "GLP-1R" into BIOS. The system runs a 9-step pipeline and returns peptide binder candidates with sequences, ready for synthesis.
The pipeline:
• UniProt + AlphaFold pull the target structure
• P2Rank flags binding hot spots
• Three models generate binders in parallel: PX Design (ByteDance), BoltGen, RFDiffusion 3
• Scoring + molecular dynamics filtering takes ~5,000 candidates down to the top 10–15
• Output ships to Adaptyv for synthesis and assay
• Wet-lab results feed back into the binder generation step
That last step is what most AI scientists skip.
A system that learns from each round of wet-lab data is how a library moves from one-shot generation toward something that compounds.