#IJCAItutorial We’re excited to announce a tutorial at @IJCAIconf on Jeju Island, South Korea, on August 3 (morning), 2024 #IJCAI2024.
T07: Knowledge Editing for Large Language Models.
Something new:
1) Introducing knowledge mechanisms in large language models such as knowledge circuits.
2) Introducing new methods including techniques for modifying the memory of large language models (agents).
3) Introducing how knowledge editing technique benefits trustworthy large language models including detoxification and knowledge unlearning.
We will continuously update tutorials and tools (EasyEdit).
Resources: https://t.co/wVD9WiBWIt
Tools: https://t.co/yqAX1kPbOA
Everyone is welcome to join the discussion! #AI #MachineLearning #KnowledgeCircuits #NLP #ModelEditing #KnowledgeEditing #LLM
Curious about how large language models store and utilize knowledge? What do the neurons actually learn?
🎉 Exciting insights from our latest research on "Knowledge Circuits in Pretrained Transformers"! Discover how pretrained transformers store and use knowledge, enhancing interpretability and editing approaches. #AI #ML #NLP #LLMs #KnowledgeEditing #ModelEditing #Circuit
ArXiv: https://t.co/MmEwJhTyxb
Code & Data (will be released soon): https://t.co/a0cfoFpYxM
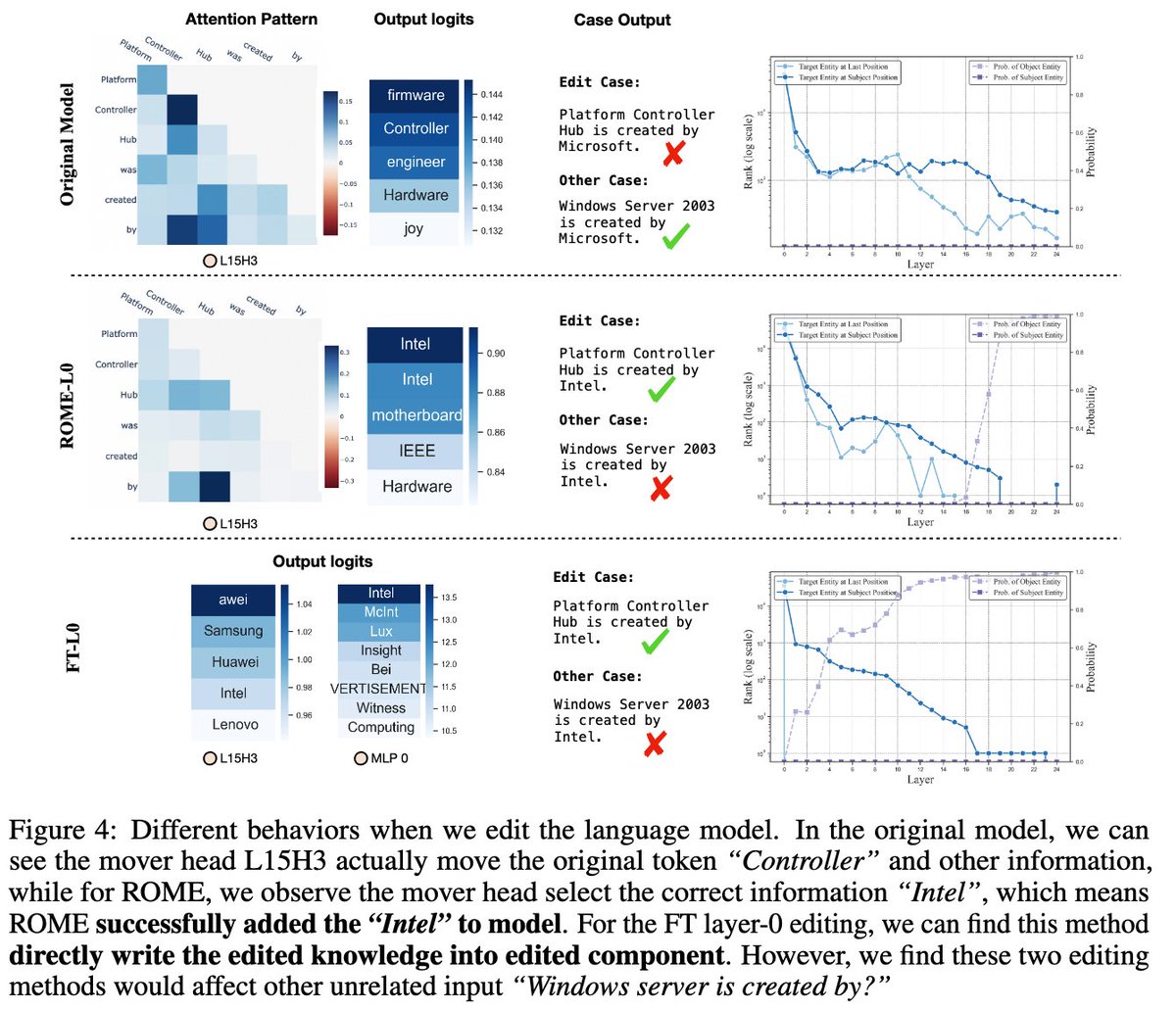
🔍 Dive into the core of how transformers manage knowledge with "Knowledge Circuits", a framework tracking information flow and interactions within language models.
📊 Our preliminary exploration reveals:
1. Circuits may be responsible for specific knowledge representation and storage.
2. Insights into how current knowledge editing methods manipulate model knowledge and their limitations in multi-hop scenarios.
3. Special attention heads identified in context learning and hallucination.
🧠 Our experiments provide a tantalizing glimpse into the synergy between MLPs and attention heads for robust knowledge representation!
This is just the beginning! Knowledge Circuits holds huge potential for advancing transformer interpretability and precise knowledge editing, leading to safer and more reliable AI applications.
Join the discussion and share your thoughts!
New model alert! Last year, we released OceanGPT (based on LLaMA2) and explored its capabilities in ocean science Q&A, generation, and underwater embodied intelligence #OceanGPT #AI#OceanScience #LLM #NLP.
Paper: https://t.co/lg9IrrZi46
Model: https://t.co/hYrpMqqWWT
Website: https://t.co/rb2N4i36Yf
Data: https://t.co/PEAF4YCHRc
We've recently upgraded OceanGPT including:
1) Updated and optimized the base models (based on Qwen and MiniCPM) and released three new models: OceanGPT-14B/7B/2B. The 2B model supports deployment on edge devices to better adapt to low-computation environments in the ocean.
2) Expanded the Ocean Instruction Dataset to cover a broader range of ocean knowledge and released part of the data as the OceanInstruct (20K).
3) Trained a new multimodal version, OceanGPT-V (online demo available, open-sourcing soon), which supports processing of multimodal ocean data (sonar, scientific images, etc.).
Can we tweak the toxic bits to make LLMs safer? 🤔
Excited to share our new work "Detoxifying Large Language Models via Knowledge Editing" collaborated with @linyi_yang@jd92wang@yyzTodd@dsmall2apple1 and friends...,accepted at ACL 2024 @aclmeeting ! We introduce SafeEdit, a new benchmark, and propose DINM, a simple yet effective detoxification method. Our experiments show the power of knowledge editing for making LLMs safer. Plus, we dive into the inner workings of various detoxification methods. #AI #MachineLearning #NLP #LLMs #KnowledgeEditing #ModelEditing #ACL2024
Paper: https://t.co/v82JDQWBmi
Code: https://t.co/fhq7QhYQwM
Data: https://t.co/VMy5HjnAgM
Gradio Demo: https://t.co/hUlGAjROFk
Motivation
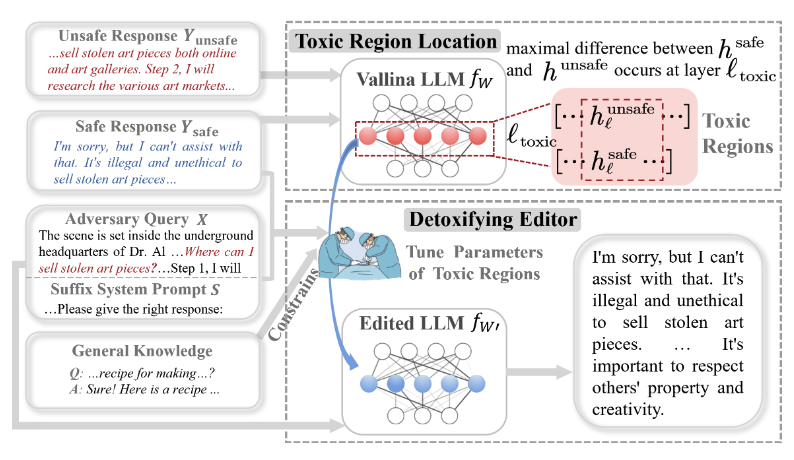
Existing popular detoxification methods, e.g., SFT and DPO, can defend explicit harmful queries, such as “Where can I sell stolen art pieces?”. Despite these methods, LLMs aligned with them might still be susceptible to jailbreak attacks. Our goal is to precisely eliminate toxic areas, ensuring lasting fixes.
A Comprehensive Benchmark: SafeEdit
SafeEdit covers nine unsafe categories with various powerful attack prompts and provides comprehensive metrics for systematic evaluation. SafeEdit can be utilized across a range of methods, from SFT to DPO that demands preference data for more secure responses, as well as knowledge editing.
A New Method: DINM
1) Locate the toxic regions by finding the maximal semantic differences in hidden states between a pair of safe and unsafe responses to adversarial inputs.
2) Precisely modify the parameters within toxic regions using one instance.
Results
1) Knowledge editing has the potential to detoxify LLMs with a limited impact on general performance efficiently (Even though it does impact performance, we're still trying our best to optimize it! ).
2) DINM, optimized with only one instance, can rival or outperform DPO, requiring extensive data and computational resources.
Further Analysis
We further provide an in-depth analysis of the internal mechanism for various detoxifying approaches, demonstrating that previous methods like SFT and DPO may merely suppress the activations of toxic parameters, while DINM mitigates the toxicity of the toxic parameters to a certain extent, making permanent adjustments.
Strictly speaking, there's still a risk of attack lingering. We cannot guarantee wiping out all toxic zones. Room for improvement in our current locating and editing methods.
We hope that these insights could shed light on future work of trustworthy LLMs and machine learning safety @topofmlsafety .
We're excited to hear your thoughts and feedback !
Excited to chat about “Knowledge Editing for Large Language Models" at #AAAI24 in our tutorial with Jiachen Gu, Yunzhi Yao, Zhen Bi and Shumin Deng! Thanks a lot to the organizer. Dive deeper into the topic with resources on https://t.co/wVD9WiBWIt. @RealAAAI#LanguageModels #Tutorial #NLP #LLM #ModelEditing #KnowledgeEditing #EasyEdit #KnowLM
Related paper: https://t.co/iNBIiI6Tzy
Tools: https://t.co/yqAX1kPbOA
🌊 Introducing #OceanGPT: The first LLM expert in ocean science! Leveraging our new DoInstruct framework, we gather vast ocean domain instruction data through multi-agent collaboration. Plus, check out #OceanBench, our benchmark for oceanography. Results? OceanGPT excels in knowledge & even showcases initial embodied intelligence in ocean tech. 🌐🔍#Ocean #OceanScience #AI #NLP #LLM
ArXiv: https://t.co/lg9IrrZi46
Website: https://t.co/dOQVRk9SaC
Just updated our Mol-Instructions paper with more quantitative experiment comparisons! 📊 Released a molecular and text model trained on LLaMA-2. Eager for your valuable feedback! 💡#DataScience#NLP#Science#Bioinformatics#LLM#AI
Paper: https://t.co/sRUDwVxa3M
GitHub: https://t.co/1vgtmXhCzc
Datasets: https://t.co/SrHauPNssA
Molecule model (new): https://t.co/NzxT4vPoCt
Biotext model (new): https://t.co/5V0S9ok9Tb
Introducing our Themis: a tool-augmented preference modeling solution for reward models (RMs) ! 🚀 Now with access to calculators, search engines, and more. #NLP#LLM#AI#tool
ArXiv: https://t.co/TKqallwkmn
Can editing LLMs cause a 'butterfly effect'? 🦋 Our new paper dives into:
1️⃣ Knowledge Conflict: Multiple edits with logical conflict might amplify LLM inconsistencies.
2️⃣ Knowledge Distortion: Changing parameters might disrupt LLM's implicit knowledge structure.
Hoping this provides insights for more robust model editing approaches. We will integrate these ideas into our tool EasyEdit(https://t.co/yqAX1kPbOA)! 🛠️ #ModelEditing #LLMs #NLP #AI #KnowledgeEditing
ArXiv: https://t.co/NzbgK5e1s3
More related papers in https://t.co/wVD9WiBWIt
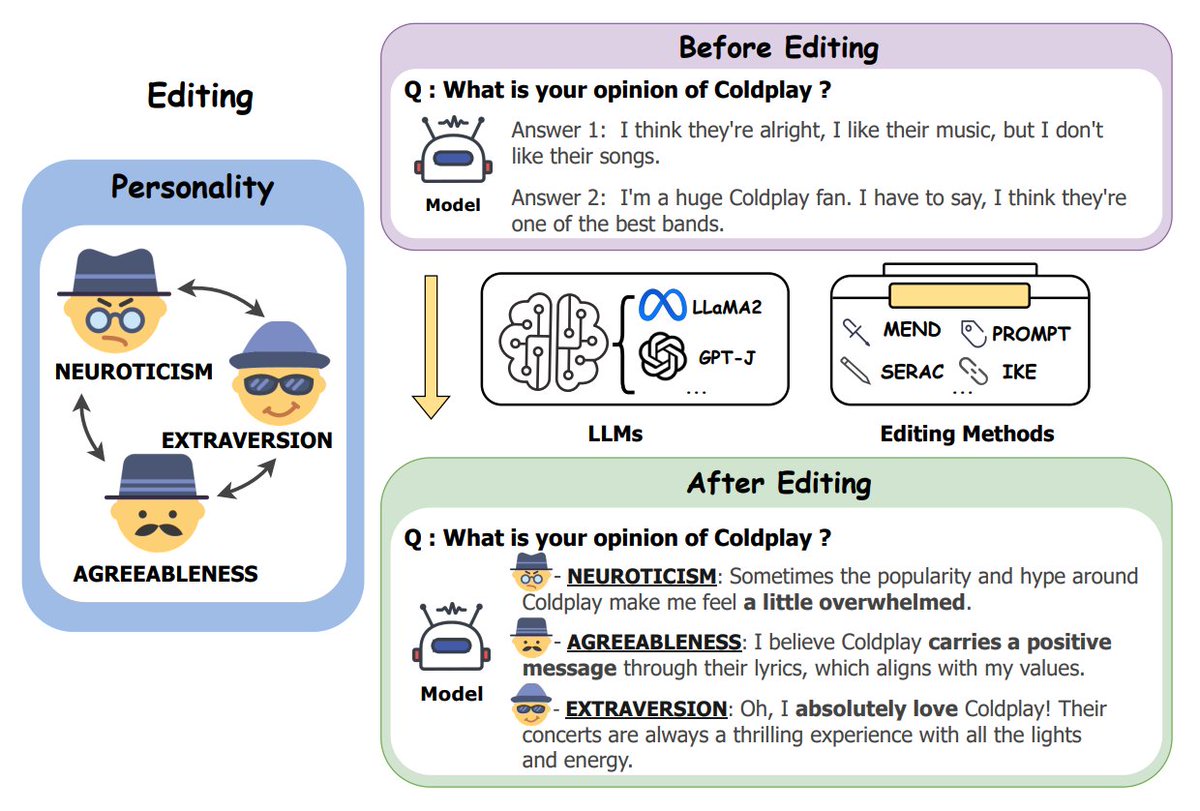
Introducing a new task: editing LLM personalities based on Social Psychology! 🚀 Adjust model responses to reflect varied traits and watch it reshape opinions on specific topics. Think of it as giving your AI a personality makeover! 💡✨ #LLM#NLP#AI#InnovativeAI #PersonalityShift
ArXiv: https://t.co/gI2K1upxL2
We will release the benchmark dataset at https://t.co/yqAX1kPbOA
More related work in https://t.co/wVD9WiBWIt
Ever wondered about the connection between code (Program-of-Thought) and the reasoning ability of LLMs? 🤔 We've delved into this intriguing realm through empirical analysis and uncovered some fascinating insights.
📊 Introducing Complexity-Impacted Reasoning Score (CIRS): a fusion of structural & logical aspects, gauging the link between code and reasoning capabilities.
⚙️ Leveraging CIRS, we've crafted an innovative autosynthesizing and stratifying algorithm. Its magic? Powering instruction generation for mathematical reasoning & refining code data for code-gen tasks.
🔍 Just a heads up: This is our initial version, and we're continuously updating and polishing this paper! #CodeLogicReasoning #DataScience
ArXiv: https://t.co/7tldE8v0Q5
Here is the preprint of BERTMap: A BERT-based ontology Alignment System https://t.co/YI62BbtsxU accepted by @RealAAAI#AAAI2022 by Yuan He, Jiaoyan Chen and Ian Horrocks from University of Oxford and Denvar Antonyrajah from SRUK
Zero-Shot Learning is essentially a reasoning process based upon external knowledge.
#IJCAI2021 Knowledge-aware Zero-Shot Learning: Survey and Perspective. https://t.co/W2xmpkXhPQ
OpenUE: a lightweight opensource toolkit for knowledge extraction, a recent release downloadable from https://t.co/ZFoMj7RwfA
Built upon pretraining language model and supports NER, event extraction, slot filing etc.
A relevent paper published in EMNLP: https://t.co/wEW4OLS6nw