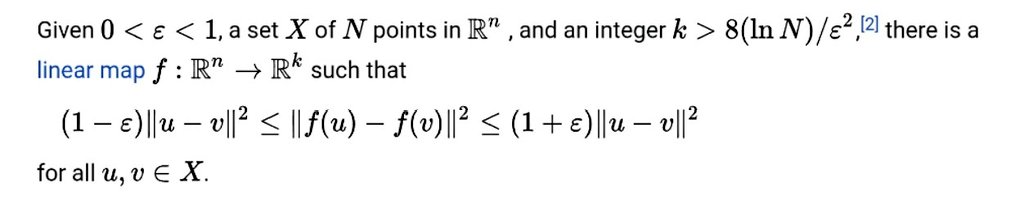After a long application journey, many great outcomes, and a very challenging decision-making process, I’m thrilled to share that I will be joining the Department of Economics at @UCBerkeley as a PhD student this Fall. Very excited for what lies ahead—this is just the beginning.
I don't know what Piketty, Stiglitz, and co. are smoking. Global poverty rates have never been lower. Progress on basic global health and wellbeing measures has been amazing over the past few decades. "End of the road"?!? Come again!?!
https://t.co/b5GHT6YXrN
Authors can't be trusted to run their own robustness checks.
In 17 AER papers, only 12/211 robustness checks "fail" with p > 0.05 (white).
In robustness checks chosen by 3rd parties, almost *half* of them fail (blue).
1/
I have no connection to MIT, but hearing that they are shutting down 3 of their 4 libraries has me so so sad. I think it’s a decision they will live to regret & the symbolism of it is devastating.
The backlash to this perfectly reasonable rule, largely from the usual suspects (i.e. AI grifters) is appalling.
I hate to break it to you but arXiv is used by actual professional scholars who are not going to throw away basic academic standards for the sake of absolute garbage.
on the whole @arxiv flap about hallucinated references etc
you don't see the stuff we reject...
some of it is really really egregious
the decision to impose additional consequences is largely to throttle that stuff so n00bs and bad actors don't trash us trying repeatedly
An Econ PhD student at the 20th ranked program who is working on stuff they are passionate about will have a better job market than one at MIT who's been doing nothing but phd-app-maxxing since undergrad.
People get confused by this because they don't observe *how* successful people came about their insane knowledge bases. It wasn't by relentlessly grinding away at stuff because they had to.
They look at Scott Kominers and say "if i grind and learn as much math as he did, i will be successful." You can't! *You* can't learn as much math as Kominers because he gets energized by configuration results for type ii lattices. You will burn out if you try to do it this way.
You cannot, through grind alone, learn more about the economics of cities than Glaeser, or about how to maximize a value function than Acemoglu.
Research careers are long. Most people give up and stop working on research (graph is share of elite PhD graduates with at least one publication in year X after graduation).
If you're starting a PhD, you're presumably doing it to have a successful 40-year research career. The number one factor in whether that happens is not which program you get into, it's whether you find a research angle that energizes you enough to push through the endless barriers an academic career throws in your path.
This is why a lot of the received wisdom around PhD applications is wrong. If you're 100% consumed by the predoc rat race already, it's going to be a long, hard road ahead.
Obv you still have to do admissions, you should study a lot for the GRE, sigh it seems like taking real analysis is probably worth it.
But spending time on the things that energize you about economics is a no-brainer, whether it's policy, or blogging, or whatever, you gotta do the things that light your fire and make you want to be on this road.
@JoshPurtell@miniapeur Happy to discuss. We want evidence of an obvious error that would have been caught if the authors had done their job and checked the LLM output. Merely using an LLM is not the issue.
You can always choose your coauthors better, so they do not produce outrageous AI slop that gets you banned from arXiv. If you are neither willing to read your own papers nor able to trust your coauthors, I wonder what exactly you think the responsibilities of a researcher are.
No, you are supposed to obsessively check everything line by line after any of your coauthors make any update to any of your papers.
Major PIs will author more than 15 papers a year with several tens of coauthors. Now they are supposed to check everything line by line at every single update without failure rate.
If the failure rate of any of this is 0.5-1%, a PI who publishes 15 papers a year or more will likely be banned in a few years at best
This is the right thing to do: expecting high standards from scientists and telling them that they can use AI tools but need to check and recheck the results before publishing is not just reasonable but is the way good science should always be done.
@lsschmitz2 Not even the most blatant cases of “classic plagiarism” always lead to fully enforced penalties. That does not make strict rules against plagiarism any less valid. IMO the point is to set professional standards, make violations legible, and establish a baseline for accountability
People reacting desperately and aggressively to arXiv’s new AI rules seem very suspicious. What arXiv requires is the bare minimum we should expect from any serious researcher. If you won’t minimally verify what is written under your name, maybe this isn’t the profession for you.
IMO, we should reward book writing more systematically. Not every valuable academic contribution needs to push the frontier. Aimless frontier-pushing can even be counterproductive. Consolidating, synthesizing, and curating knowledge can matter as much as another frontier paper.
Zane is correct. To get in to an econ PhD, anything other than math classes or econ research is a waste of time. However I think it is sad for our profession that this is the case. Economists who write and spend time with policy makers or industry are much more influential.
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
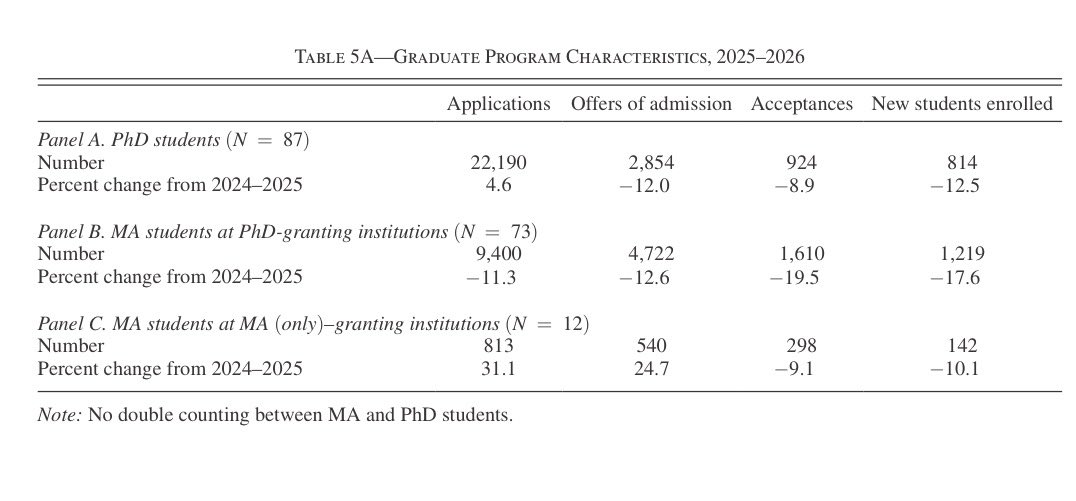
For researchers interested in U.S. banking and finance, we are sharing a new data resource!
It contains information on bank balance sheets, bank runs, and bank failures from the 19th century to the present:
@JesusFerna7026@MahdiKahou Fortunately, Faber’s theorem is not as bad as it seems. Here’s Trefethen on it, in his “Inverse Yogiisms.” TL;DR: Faber’s theorem applies to continuous functions, but says nothing about smooth, or even Lipschitz functions. For those, Chebyshev interpolation still works very well!
One theorem every ML engineer should know:
The Johnson–Lindenstrauss Lemma.
It states that high-dimensional data can be projected into a much lower-dimensional space while approximately preserving pairwise distances.
Why it matters:
• Explains why random projections work
• Enables scalable learning in high dimensions
• Used in embeddings, compressed learning, and ANN search
• Helps fight the curse of dimensionality
The surprising part:
You can reduce dimensions dramatically without destroying the geometry of the data.
That’s why many ML systems can operate efficiently even with massive feature spaces.
Modern representation learning is deeply connected to this idea:
Good embeddings preserve structure while compressing information.
In ML, compression is often not loss of intelligence —
it’s removal of redundancy.
Fantastic news! Congratulations to my colleague and longtime collaborator Whitney K. Newey on being awarded the 2026 Erwin Plein Nemmers Prize in Economics. Well-deserved recognition for his foundations contributions to econometrics. 🎉























![eBlogs's tweet photo. Higher-Order Neyman Orthogonality in Moment-Condition Models
Stéphane Bonhomme, Koen Jochmans, Whitney K. Newey, Martin Weidner
https://t.co/3yhRu9o64d [𝚎𝚌𝚘𝚗.𝙴𝙼 𝚖𝚊𝚝𝚑.𝚂𝚃] https://t.co/0TuWXfjD0e](https://pbs.twimg.com/media/HIGsC-tWcAA8ApJ.png)