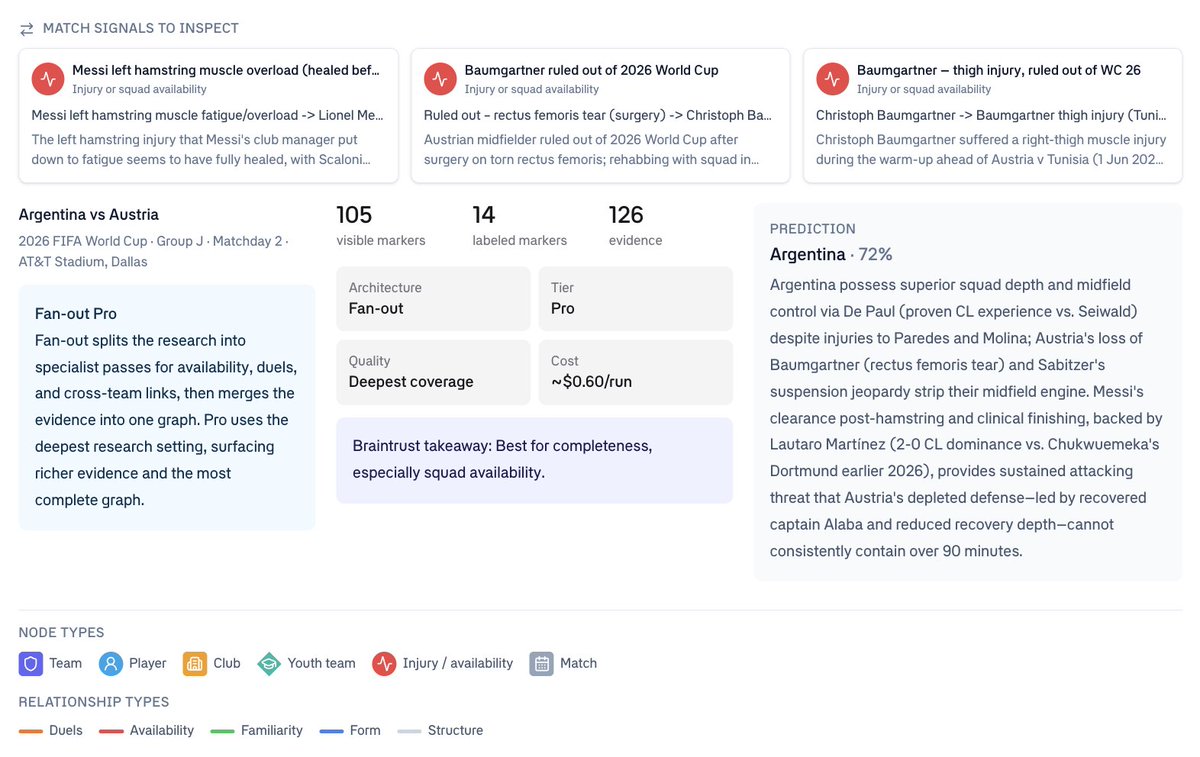
We ran the 48 Group Stage World Cup matchups through six configurations of @p0 research agents and scored every output in Braintrust.
Here's what we found → https://t.co/BrOi713GnE
In a recent @Braintrust post, I compared GLM 5.2, served by @baseten, with Anthropic’s Opus 4.8 and Sonnet 5 on a long-context code retrieval eval. Building and digging into this eval reminded me of the importance of considering the variance in your data.
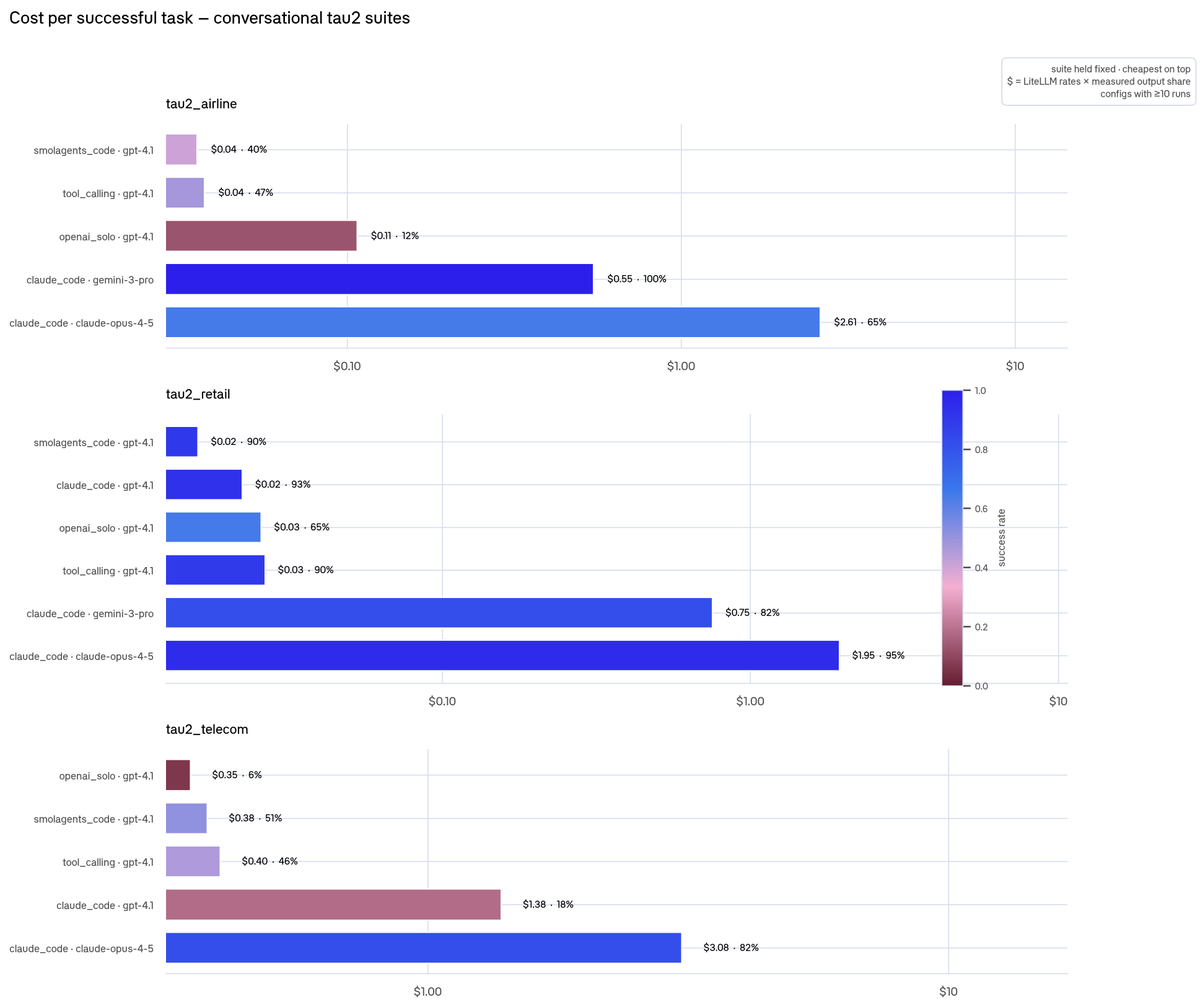
The answer to "which model is cheapest" depends entirely on whether you're asking about cost per task or cost per success.
We took 1,781 real agent traces from @huggingface and used Braintrust to eval them for patterns.
The results show that you should pick the cheapest config that clears your quality bar, but that config is different per task family. Open-weight models can manage coding, but gpt-4.1 is still better for conversational support.
Game, set, match on the inaugural Agent Open.
Thanks to everyone who stopped by and grabbed a paddle.
And thanks to our friends and partners who made it possible: @Modal, @Browserbase, @turbopuffer, @p0, @llama_index, and @cursor_ai.
See you at the next one.
Run the best OSS models in Braintrust, in collaboration with @Baseten.
Call GLM-5.2 natively, eval its quality, and observe its behavior in production. Save on inference costs without compromising quality by picking the best model for your agent. Free to try through July 31.
The AI teams that ship quality agents put evals and observability in place early.
Braintrust for Startups gives early-stage companies production-grade observability infrastructure so they can build with confidence, no matter their size or resources.
Reading traces one by one doesn't scale.
Topics automatically clusters production traces so you can identify patterns, investigate failures, and decide where to focus your eval efforts.
Run a full chess eval without writing a single line of code using the Braintrust CLI.
- Take a CSV of chess puzzles and make a dataset.
- Write a prompt to solve mate in 2 puzzles, and upload it to the project.
- Then write a scorer that compares the output to the expected answer.
The eval found that GPT‑5 with no reasoning scored about 25% on the chess puzzles, and with low reasoning it scored about 15%.
What's new:
- Smarter evals with role-based score visibility and contextual rubrics.
- Secure access to OpenAI, Anthropic, Google, and Azure without long-lived credentials.
- Faster debugging with a redesigned trace experience that surfaces the most critical content.
- Higher reliability through automatic provider failover.
- Complete audit logs for better security and compliance.
Stateful agents that do real work are worth investing in, but they're also more difficult to eval. The hard part isn't scoring, it's getting the state right.
The best approach is to be deliberate about what needs to be real and what can be mocked in the eval, so you balance cost and time while still capturing state accurately.
Cost-efficiency doesn't mean picking the cheapest model. Model choice, routing, retries, fallbacks, and escalation all determine cost together.
If you want to reduce AI cost without trading away quality, the right unit of analysis is cost-per-resolved-request, measured against the quality bar your product needs.