In the age of agents, it's surprising how important information accessibility becomes. If conversations and thinking is hidden away, it's not very useful, is it?
Try this in before replying to your next DM: "can we post this somewhere public?"
We're killing the DM at @Zapier. Starting with the executive team.
We've long held Default to Transparency as a value. That value has largely encouraged communication in public channels. But as the company grew, DMs are a hard habit to resist and break.
But every DM is a gap in our Shared Brain. It's context that is lost for humans and AIs. As a result the cost of DMs keeps going up.
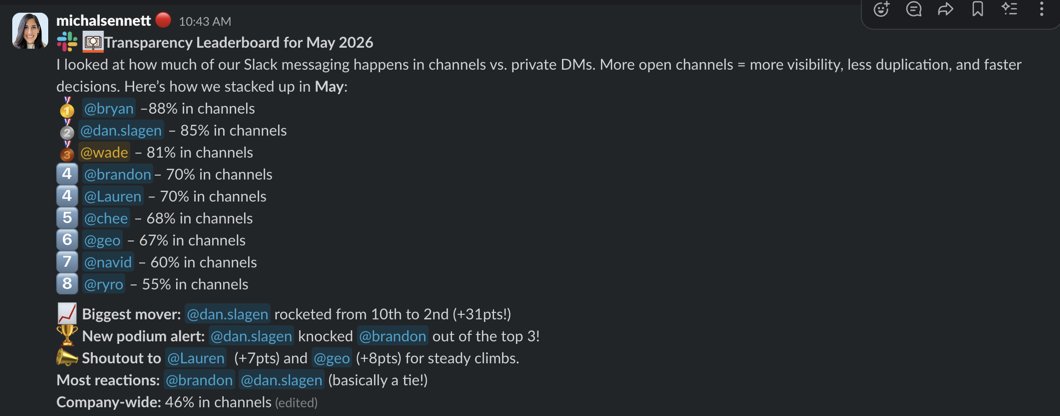
So earlier this year I posted about our exec transparency leaderboard. The leaderboard has become quite the competition internally…
I'm 3rd today. My co-founder @BryanHelmig has held the top spot as long as I can remember…
It sets a standard for the rest of the company. In fact, since last year we’ve seen the % of Slack messages in public channels go from 33% to 46%.
What the leaderboard measures
Transparency is a team sport, and a disinfectant. Every month we track what percentage of our execs' Slack messages happen in public channels versus private DMs.
When your CEO debates strategy in a DM, that decision is invisible to every agent and every team that needs to know what was decided and why. The decision happens but the reasoning vanishes.
When that conversation happens in a channel, it stays. New hires can search it, agents can read and verify it, etc. Your Shared Brain knows what's true now: ask it a question and the answer reflects the latest reality.
Taking It to the Next Level
Reducing DMs are one way to increase transparency and open up context for humans and AI, but there are other mechanisms that help too. Three things beyond the leaderboard:
1. Meetings get recorded, transcribed, and become queryable
2. We run a shared skills library. Anyone on the team can encode a workflow they've figured out into a skill and share with the team
3. And we keep score. It's a silly scoreboard, but it subtly drives positive behaviors
Raising Your Ambition
In order to get the most of AI in your company, the AIs need context. So making your context queryable is one of the most practical moves you can make to improve the effectiveness of your AI agents.
P.S. I’m coming for #1, Bryan...
We're killing the DM at @Zapier. Starting with the executive team.
We've long held Default to Transparency as a value. That value has largely encouraged communication in public channels. But as the company grew, DMs are a hard habit to resist and break.
But every DM is a gap in our Shared Brain. It's context that is lost for humans and AIs. As a result the cost of DMs keeps going up.
So earlier this year I posted about our exec transparency leaderboard. The leaderboard has become quite the competition internally…
I'm 3rd today. My co-founder @BryanHelmig has held the top spot as long as I can remember…
It sets a standard for the rest of the company. In fact, since last year we’ve seen the % of Slack messages in public channels go from 33% to 46%.
What the leaderboard measures
Transparency is a team sport, and a disinfectant. Every month we track what percentage of our execs' Slack messages happen in public channels versus private DMs.
When your CEO debates strategy in a DM, that decision is invisible to every agent and every team that needs to know what was decided and why. The decision happens but the reasoning vanishes.
When that conversation happens in a channel, it stays. New hires can search it, agents can read and verify it, etc. Your Shared Brain knows what's true now: ask it a question and the answer reflects the latest reality.
Taking It to the Next Level
Reducing DMs are one way to increase transparency and open up context for humans and AI, but there are other mechanisms that help too. Three things beyond the leaderboard:
1. Meetings get recorded, transcribed, and become queryable
2. We run a shared skills library. Anyone on the team can encode a workflow they've figured out into a skill and share with the team
3. And we keep score. It's a silly scoreboard, but it subtly drives positive behaviors
Raising Your Ambition
In order to get the most of AI in your company, the AIs need context. So making your context queryable is one of the most practical moves you can make to improve the effectiveness of your AI agents.
P.S. I’m coming for #1, Bryan...
@TFAwinner the models are good, the marketing is more "when life gives you lemons, sell lemonade" -- assuredly both ant and oai would rather be selling tokens against these models.
anthropics' fable 5 (mythos) is the highest scoring model yet on automationbench. it is better at following complex instructions, is more autonomous, and is more persistent. notably, it'll experiment more rather than stop and ask questions. impressive!
https://t.co/bybhqlU8tH
Claude’s Opus 4.8 just released.
Zapier's benchmarks are front and center on their scorecard.
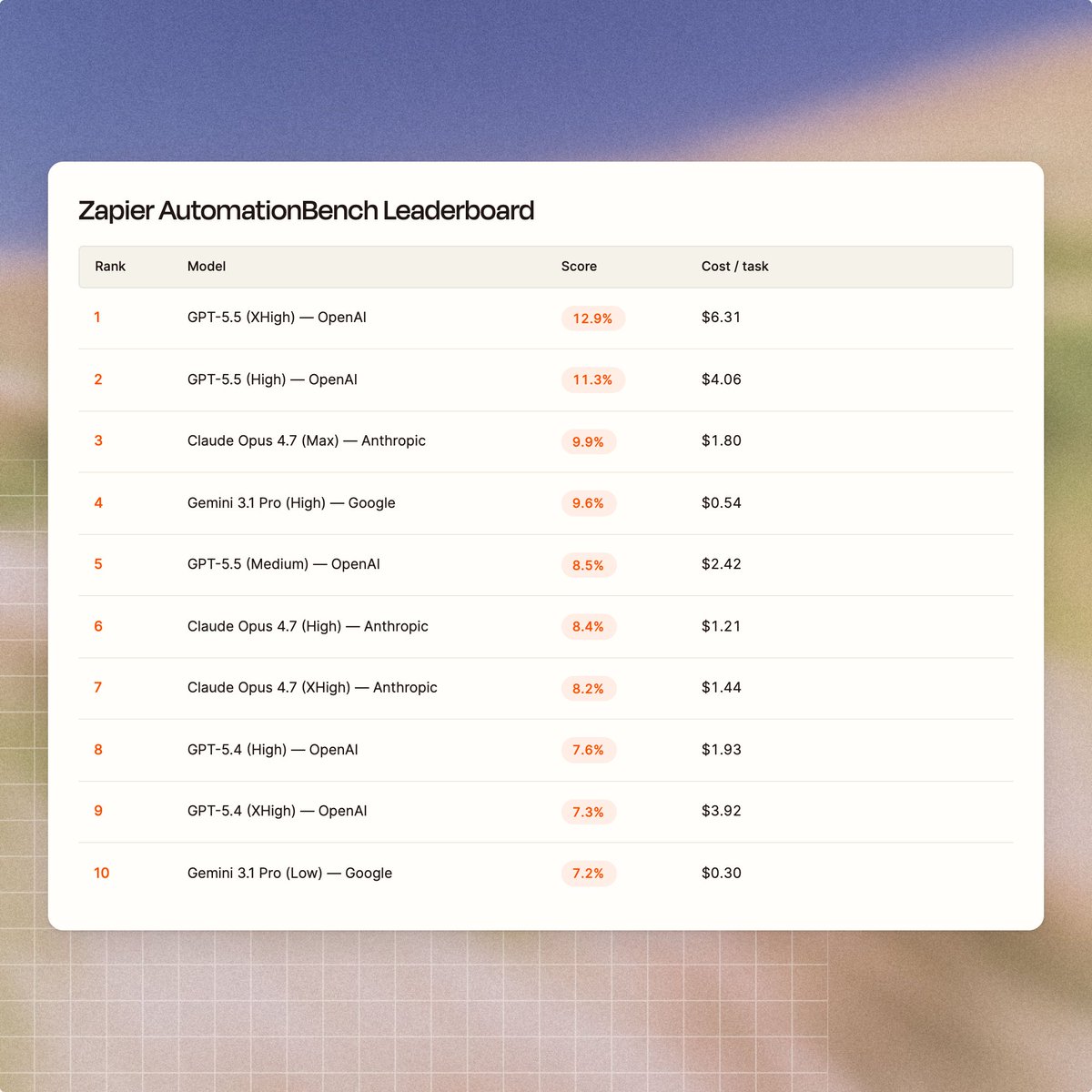
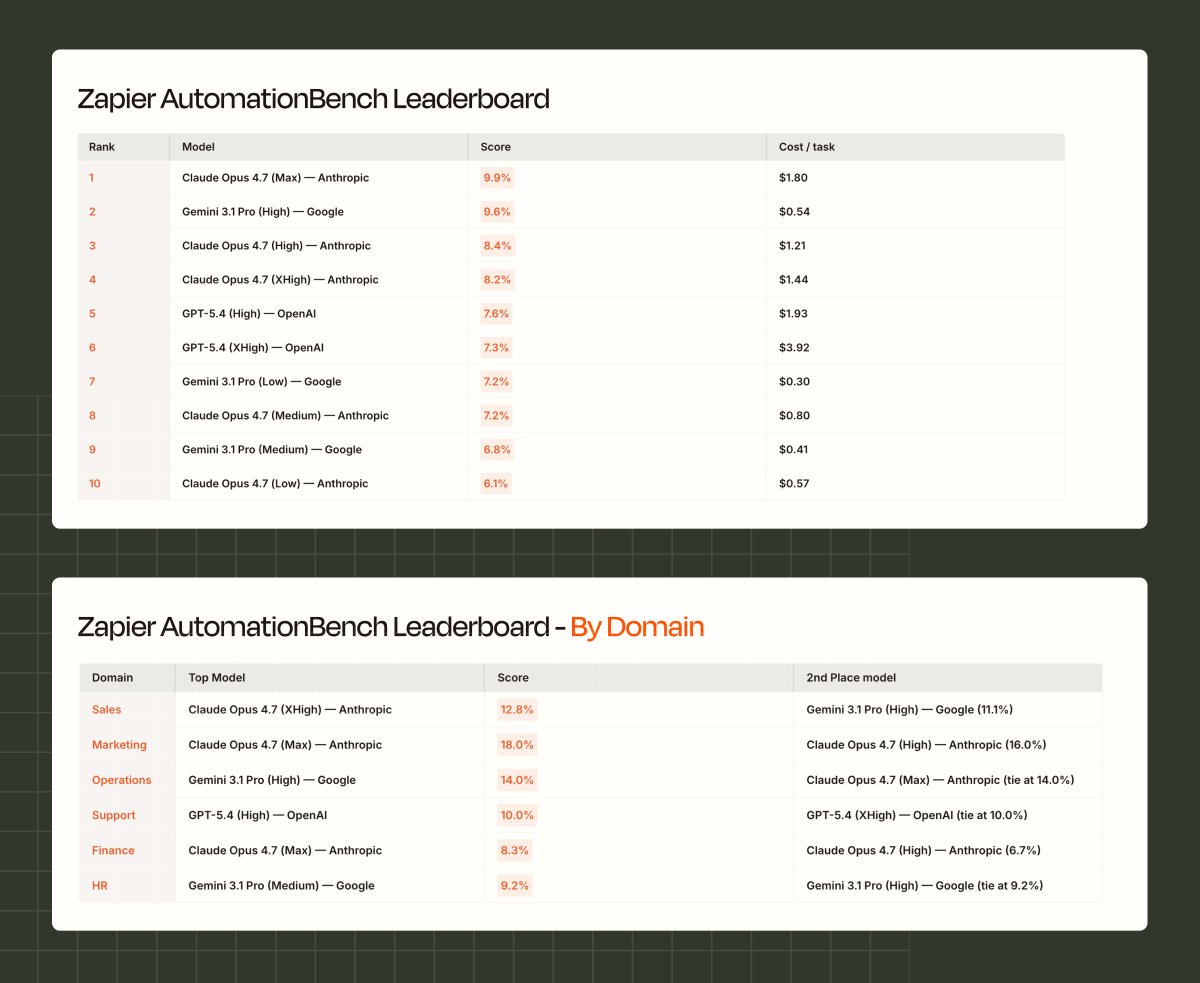
We got early access and put it through the full AutomationBench gauntlet. @AnthropicAI's newest model set a new pass-rate record, which Gemini had just broken last week.
On xhigh and max reasoning, it's a 50%+ improvement over Opus 4.7 ❗
The biggest unlock for agentic workflows? Refusals (where the model declines to act) dropped from 20% to 4%. 4.7 would often decline sensitive tasks outright instead of redacting or partially completing them... 4.8 keeps going. (HR is the clearest example. Opus 4.8 scored around 6x higher than 4.7 on HR workflows)
One tradeoff worth knowing: it still chooses token efficiency over persistence. It would rather check in than burn tokens hunting for context. But now it's a lot smarter about when that's the right call.
tl;dr: replace Opus 4.7 with 4.8 for complex, ambiguous workflows with lots of context to discover.
Try it now in @Zapier
Opus 4.8, the first model to break 15% on AutomationBench, is now live in Zapier!
It handles complex HR, Finance, and multi-app workflows better than anything else we've tested: refusals dropped from 20% to 4%
Opus 4.7 would see a sensitive task and stop, but 4.8 keeps going
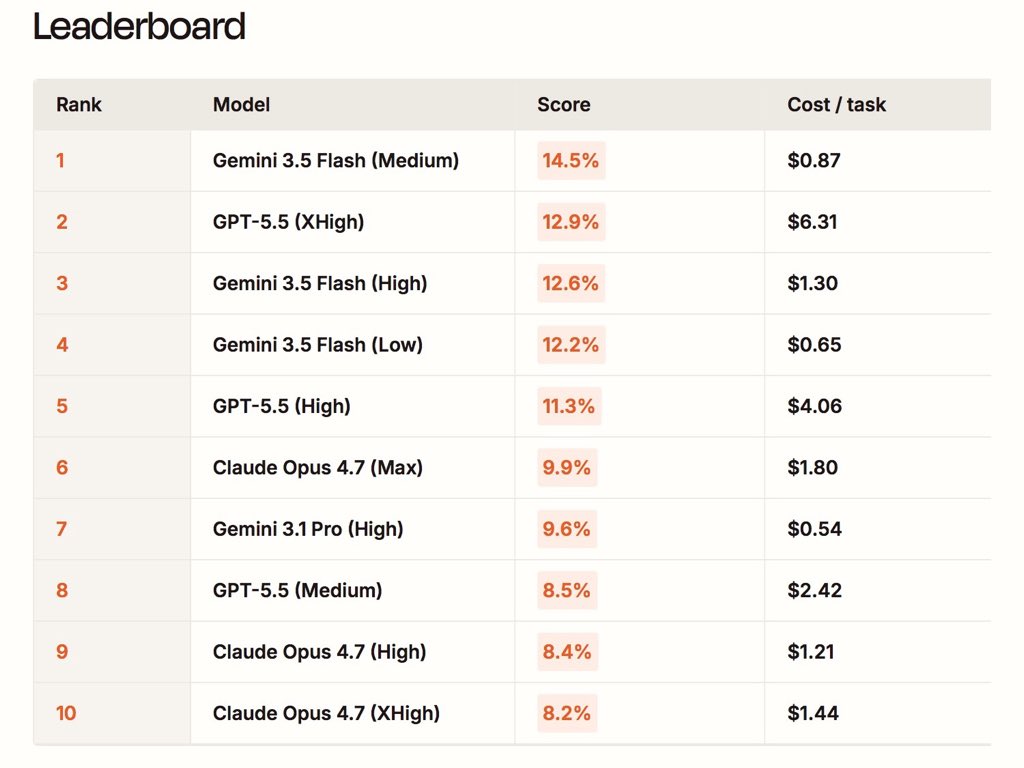
gemini 3.5 flash (med) is the new leader 14.5% on zapier's automation bench and roughly 7x (!!!) cheaper than gpt 5.5 (xhigh) 12.9%
3.5 flash is the most persistent model we've seen yet. thats why high reasoning scores lower than med -- it maxes out our tool call limit. we may revisit this for automation bench v2.
https://t.co/Vdni6H836U
our next product is almost ready - agents that build and ship automations
we've been using it internally for months and ready to open it up to a small group of beta testers before it even has a name....
we're looking for:
- 10-100 person teams spending hours/week on manual ops
- teams tired of chat, ready to build and ship automations through agents
- teams that work in the open -- call recordings on, shared docs, public channels, etc
- teams obsessed with optimizing their work
apply: https://t.co/lb1zGVktCl
GPT-5.5 just hit 12.9% on our AutomationBench leaderboard
First model to break 10%
When context is missing, most models stop. GPT-5.5 keeps checking emails, docs, and chats until it knows what to do
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: https://t.co/V7qHAGX7Ql
i completely replaced mcp and now have 90+ custom cli scripts for jira, gdocs, lumapps, etc. built on top of the zapier sdk and cli (available here https://t.co/euoCJ4XJZx)
anytime i need another, i just ask to create. anytime i hit a bug, i just ask for a fix. its awesome.
plus, with our managed connections, claude/codex even doesn't have the raw api keys or oauth credentials!
Today we open the Zapier SDK to everyone.
If you're building with AI agents, this is for you.
I've been using this for 2 months. It's totally changed how I do my job.
You install it in your coding agent. Cursor, Claude Code, Codex, whatever you use. Now that agent has access to 8,000+ apps through @Zapier and can do anything those APIs can do.
I think it’s the most powerful thing we’ve launched in years. Now in open beta.
Just give this link right to your agent:
https://t.co/k6arEyZMMU
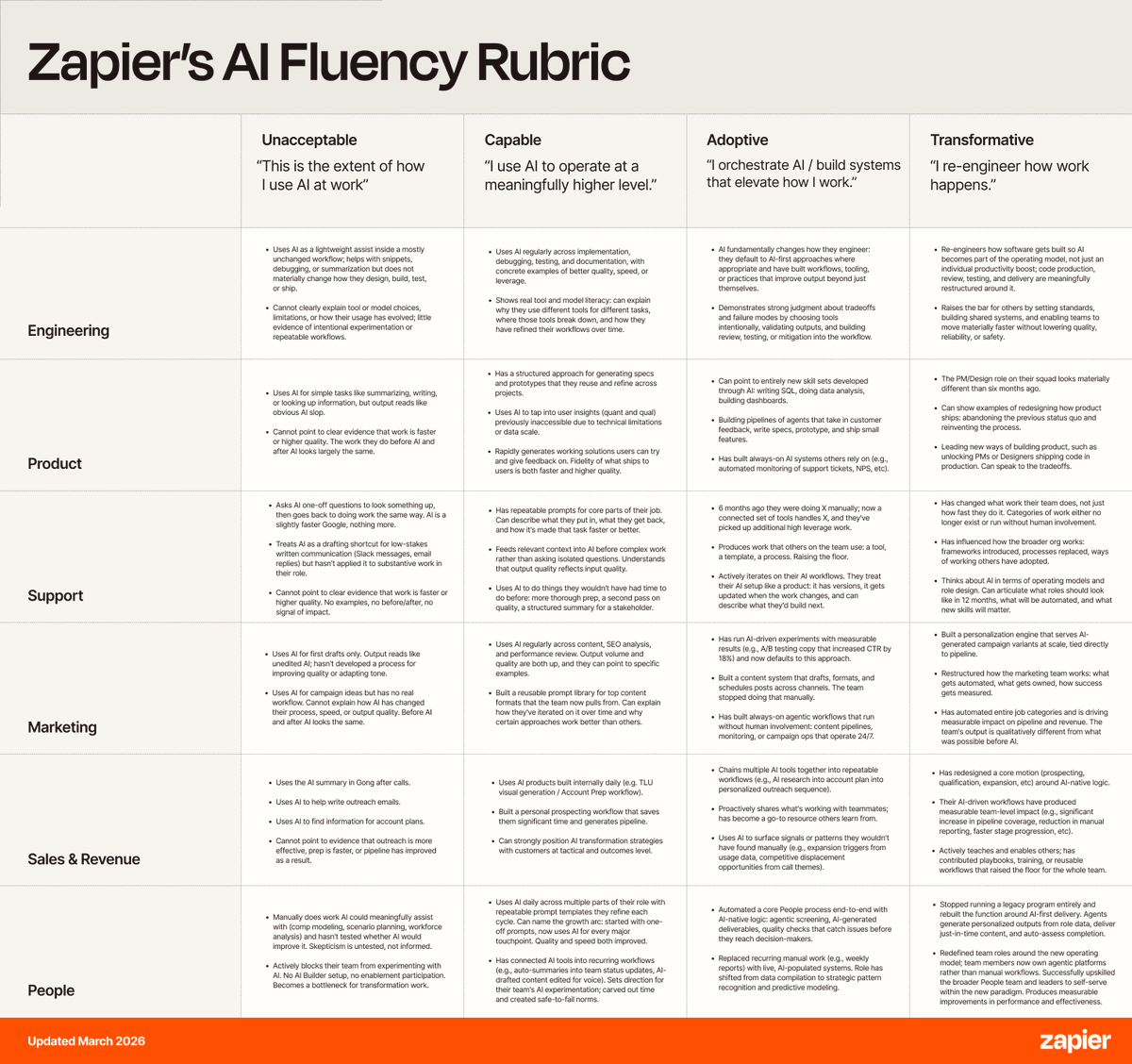
Today we released our new AI Fluency Rubric.
We use it for every hire, focusing on what they’ve actually built.
Last May we open-sourced V1. Hundreds of companies used it to screen candidates and develop teams. It worked. But the floor moved fast.
An updated look at the 3 levels of AI fluency at @Zapier:
1. Capable: "I use AI to operate at a meaningfully higher level."
2. Adoptive: "I orchestrate AI and build systems that elevate how I work."
3. Transformative: "I re-engineer how work happens."
We evaluate theses across 4 dimensions: Mindset, Strategy, Building, and Accountability.
We're sharing V2 publicly for the same reason we shared V1: every company needs a framework for this, and most don't have one yet.
Don’t see your role? See all departments / learn more here: https://t.co/EqLTK3Xfyr
ARC-AGI-3 and ARC Prize 2026 are now live with $2,000,000 in prizes!
As of today, version 3 is the world's only unsaturated agentic intelligence benchmark. Humans score 100% and frontier AI scores ~0%.
Play here: https://t.co/i94cM1IDQR
While no single version of ARC is definitionally AGI, our aim with the ARC-AGI Series is to continually produce useful scientific benchmarks which identify large remaining gaps between Humans and Frontier AI. At some point, we'll be unable to, and then we'll have AGI.
Our new benchmark consists of over 100 novel game environments encompassing nearly 1,000 levels.
Notably, test takers are given no explicit goals (other than to win) and must explore the environments to acquire goals, understand rules, develop strategy, and ultimately execute a plan to win.
ARC-AGI-3 is a test of agentic intelligence. Beating this benchmark requires on-the-fly world modeling and continual learning to adapt to evolving environments.
To score 100% AI must beat all of the games as efficiently as the human baseline (e.g., the number of actions taken to win). An ARC first, this gives us a formal comparison of AI reasoning efficiency vs humans.
Version 3 carries classic ARC design principles: core knowledge priors only, private test sets to measure generalization, and it's fun!
Every benchmark we release is an experiment and I believe this new version will provide strong signal towards increasingly autonomous AI agents.
Prior versions of ARC held strong predictive power for important AI moments. Version 1 only saw progress with the release of AI reasoning models in late 2024 and Version 2 only began seeing progress with the advent of agentic coding models in late 2025.
Version 3 is expected to signal when AI agents can become economically useful in more open-ended domains (beyond highly measurable domains like coding and math).
There are a few other important design changes for ARC-AGI-3.
The public set is now a "demonstration" set, not a training set. And unlike prior versions, the private set is now explicitly designed to be Out Of Distribution (non-IDD) from the public demo set. This is to mitigate targeting and because LLMs can now generalize over IDD splits using AI reasoning.
Frontier models have made great progress over the past year. So much that several industry leaders have suggested we may already have AGI.
Part of the ARC Prize Foundation mission is to provide accurate public sense finding and we strive to reduce false-positive claims.
To this end, we've updated our testing policy. Going forward we will only verify scores outside of the official Kaggle competitions from AI systems with high commercial usage or are 100% open source.
We're also adopting a stateless client scoring philosophy to ensure humans and AI are tested under identical conditions.
The goal of these changes is to reduce the amount of developer-aware targeting (whether incidental or intentional) and provide clear signal if actual AGI progress has occurred.
The Foundation also has a goal to inspire AI innovation which is most likely to come from the community. We've seen dozens of startups using ARC as a tool for showcasing their ideas - a few have fundraised serious capital based on their ARC results.
To support this we're launching a new Community leaderboard. While scores for this leaderboard can't be Verified, and you should explicitly not trust these scores as an accurate measure of AGI progress, we will curate the best ideas and promote them.
This year I expect we will see rapid progress on the ARC-AGI-3 Community leaderboard and the best ideas will eventually migrate into frontier models and onto the Verified leaderboard.
Finally, we’ve partnered again with Kaggle to run two competition tracks for ARC-AGI-2 and ARC-AGI-3. This will be the last year for Version 2.
When we launched the first ARC Prize back in 2024, I committed to running the Grand Prize until it was beaten. So for the ARC-AGI-2 track we will be paying out the Grand Prize to the best team, no matter what, in order to honor this commitment.
In accordance with the Foundation mission, to win any prize money you must open-source a reproducible solution. We raised the standard for open source to include training. I'm excited to produce a truly open solution as a final send off for the ARC-AGI-1 and 2 format.
Focus is now on ARC-AGI-3 (we've even started work on Versions 4 and 5).
As always, I'm honored to have the opportunity to steward attention towards AGI progress.
I'm also super grateful to the incredible ARC Prize team - including our core engineers, game designers, and human testers - led by @GregKamradt without whom we would not have this incredibly useful benchmark.
See you on the leaderboard!