This might be the most dangerous GitHub repo ever published.
Someone built a full 10.5 GHz radar system that can track targets up to 20km away and open sourced the entire thing.
It ships with:
→ Complete PCB designs and schematics
→ FPGA signal processing code
→ STM32 firmware
→ Python GUI with map integration
→ GPS/IMU integration
→ MIT license (100% free)
6.8k stars on GitHub already
This is the kind of project defense contractors would charge you a fortune for.
One dev just put it on GitHub.
This 1-hour Stanford lecture on “Sports Betting Math”, delivered by the founder of a $160M platform, breaks down how bookmakers make millions using pure math.
Watch it fully or, if you’re short on time, read my article where I’ve summarized the key insights.
A Stanford paper just challenged one of quant finance's oldest assumptions.
For decades, the consensus was clear:
Raw prices are too noisy to be useful.
You need indicators. Factors. Human-crafted features.
This paper disagrees.
Here's what they found out (+ free 9 page PDF):
An absolute banger of a paper.
“A Gentle Introduction to Matrix Calculus” by econometrics legend Jan Magnus — one of the clearest explanations of matrix derivatives ever written.
If you work in econometrics, machine learning, statistics, or optimisation, this paper is pure gold.
If you want to be a distributed systems engineer who wants to become Staff at FAANG, I would say this a bit differently.
Do not try to learn 17 things as separate checklist items and then keep changing languages every 3 months.
That is how people keep “preparing” for 5 years.
You do not become Staff because you know REST, GraphQL, gRPC, Redis, Kafka, Docker, Kubernetes, AWS, Prometheus, Grafana and 40 other buzzwords.
You become Staff when you can look at a messy production system and answer things like:
Why is p99 latency suddenly bad? Why is replication lag increasing? Why are retries causing a thundering herd? Why did this cache make things faster yesterday but inconsistent today? Why did one region fail and now the whole system is timing out? Why does this service need to exist at all?
That is the real game.
For wannabe Staff engineers, the path is more like this:
1. Pick one backend language seriously. Go, Java, or even Python if your stack allows it. Not because language is everything, but because syntax should become invisible to you.
2. Go deep on fundamentals. Networking, OS basics, concurrency, storage engines, indexes, transactions, consensus tradeoffs, queues, failure handling. This is where actual engineers are separated from tutorial collectors.
3. Build systems, not toy CRUD apps. Rate limiter. Job queue. Distributed cache. Event driven pipeline. Notification system. Search autocomplete. Write something that breaks under load, then fix it.
4. Learn tradeoffs, not definitions. Strong consistency vs availability. Sync vs async. Horizontal vs vertical scaling. Partitioning vs replication. Monolith vs microservices. Every Staff conversation is mostly tradeoffs.
5. Get very good at observability. Logs tell you what happened. Metrics tell you how bad it is. Traces tell you where it broke. Most engineers write code. Few can debug production calmly.
6. Write design docs. A lot of people want Staff title. Very few can clearly explain: problem, constraints, proposed design, bottlenecks, rollback plan, and why this is the right tradeoff for the business.
That is why some engineers with less tech stack knowledge still grow faster.
Cause Staff is not “best coder in the room”.
It is usually: the person who sees around corners, reduces future incidents, simplifies systems, and helps 5 other engineers move faster.
So yes, learn system design. Learn APIs. Learn databases. Learn distributed systems. Learn caching. Learn security. Learn cloud. Learn monitoring.
But do it through one serious language and repeated real system building.
Otherwise you are just collecting nouns.
And FAANG does not promote noun collectors.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
For anyone wondering how a third-grader can complete six years' worth of math in a single year.
This knowledge graph spans 3,000 math topics, from 4th grade to the university level, providing the perfect basis for mastery learning.
Students can go as fast or far as they want! There are no restrictions whatsoever. The only requirement is that they must demonstrate mastery of each topic before moving on to the next.
Kids are capable of incredible things when given that kind of freedom and support.
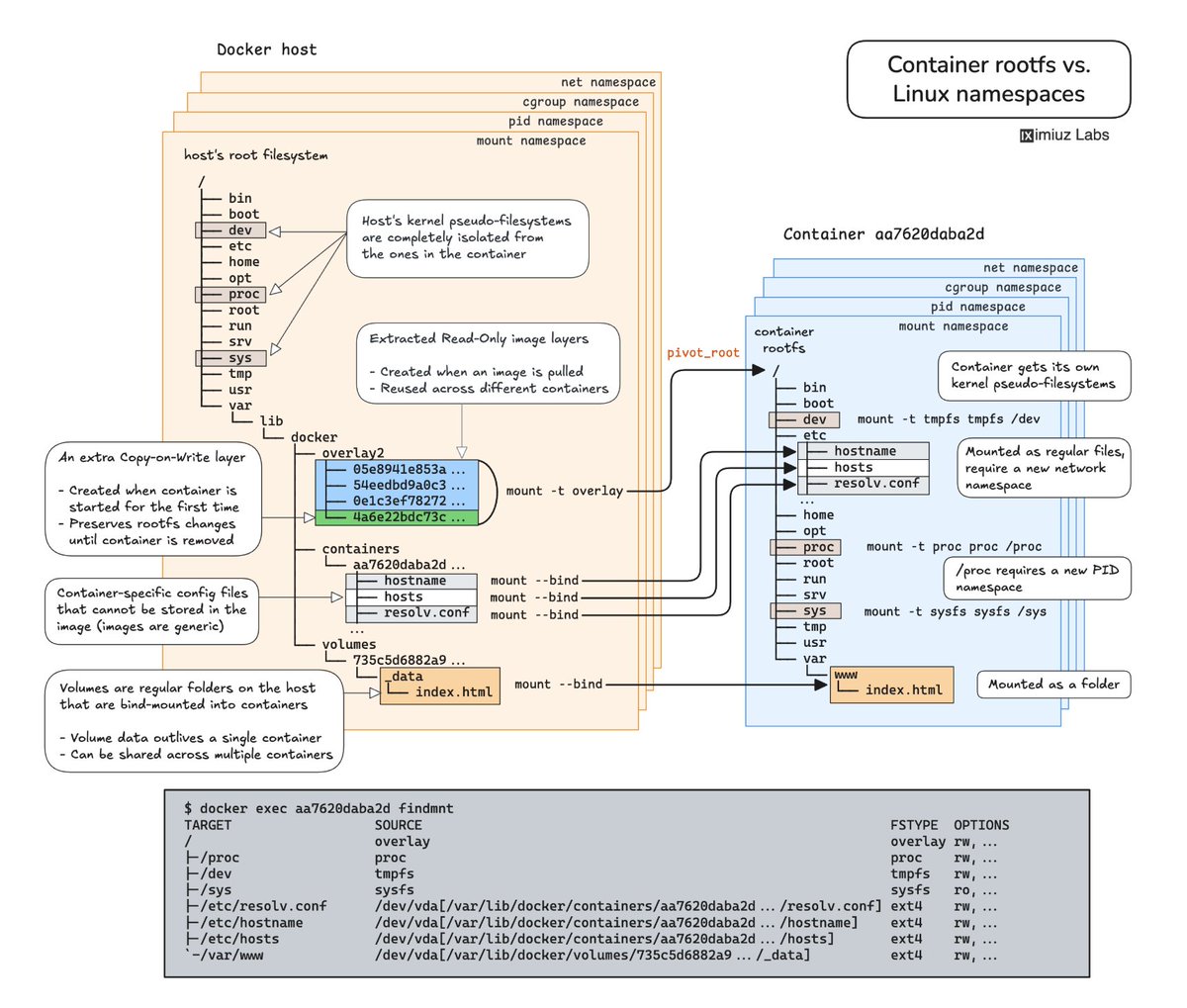
How Container Filesystem Works 🧐
Building a Docker-like container from scratch using only standard Linux commands (unshare, mount, pivot_root, etc.) is a great way to understand exactly what a container runtime like runc does under the hood to turn a container image into a fully-fledged rootfs.
Hands-on: https://t.co/PC7c9Zy1SJ
🚨 BREAKING: A developer on GitHub just built a tool that turns any GitHub repo into an interactive knowledge graph and open sourced it for free.
It's called GitNexus. Think of it as a visual X-ray of your codebase but with an AI agent you can actually talk to.
No server. No subscription. No enterprise sales call.
Here's what it does inside your browser:
�� Parses your entire GitHub repo or ZIP file in seconds
→ Builds a live interactive knowledge graph with D3.js
→ Maps every function, class, import, and call relationship
→ Runs a 4-pass AST pipeline: structure → parsing → imports → call graph
→ Stores everything in an embedded KuzuDB graph database
→ Lets you query your codebase in plain English with an AI agent
Here's the wildest part:
It uses Web Workers to parallelize parsing across threads so a massive monorepo doesn't freeze your tab.
The Graph RAG agent traverses real graph relationships using Cypher queries not embeddings, not vector search. Actual graph logic.
Ask it things like "What functions call this module?" or "Find all classes that inherit from X" and it traces the answer through the graph.
This is the kind of code intelligence tool enterprise teams pay thousands per month for.
It runs entirely in your browser.
Works with TypeScript, JavaScript, and Python.
100% Open Source. MIT License.
Repo: https://t.co/RzIoLR2vAe
If you want to become a database genius among your peers, you need to read this article. It offers invaluable insights that could mark the beginning of your breakthrough in the database field.
Someone built a web-based System Design Simulator,
where you drag & drop architecture components and actually simulate traffic, failures, latency, and scaling in real time,
System design just got way more interactive.
Google just released TimesFM (a Time Series Foundation Model) - a 200M-parameter model that can forecast time-series data it has never seen before, with no additional fine-tuning required.
Time-series forecasting is required everywhere - retail, finance, healthcare, etc. And for the longest time, this was the domain of traditional statistical methods. Then deep learning models came along and did better, but they involved long training and validation cycles before you could even test them on new data.
TimesFM changes this. All we need to do is point it at a new dataset, and it gives you a solid forecast immediately - zero-shot.
The architecture is decoder-only, the same idea as GPT. Instead of words, it works with "patches" - groups of contiguous time-points treated as tokens. The model predicts the next patch from all the ones before it.
The model was pre-trained on 100 billion real-world time-points, mostly from Google Trends and Wikipedia Pageviews - which naturally capture a huge variety of patterns across domains.
On benchmarks, zero-shot TimesFM matches PatchTST and DeepAR that were explicitly trained on those datasets, and even beats GPT-3.5 on forecasting tasks despite being far smaller.
The model is open on HuggingFace and GitHub if you want to try it.
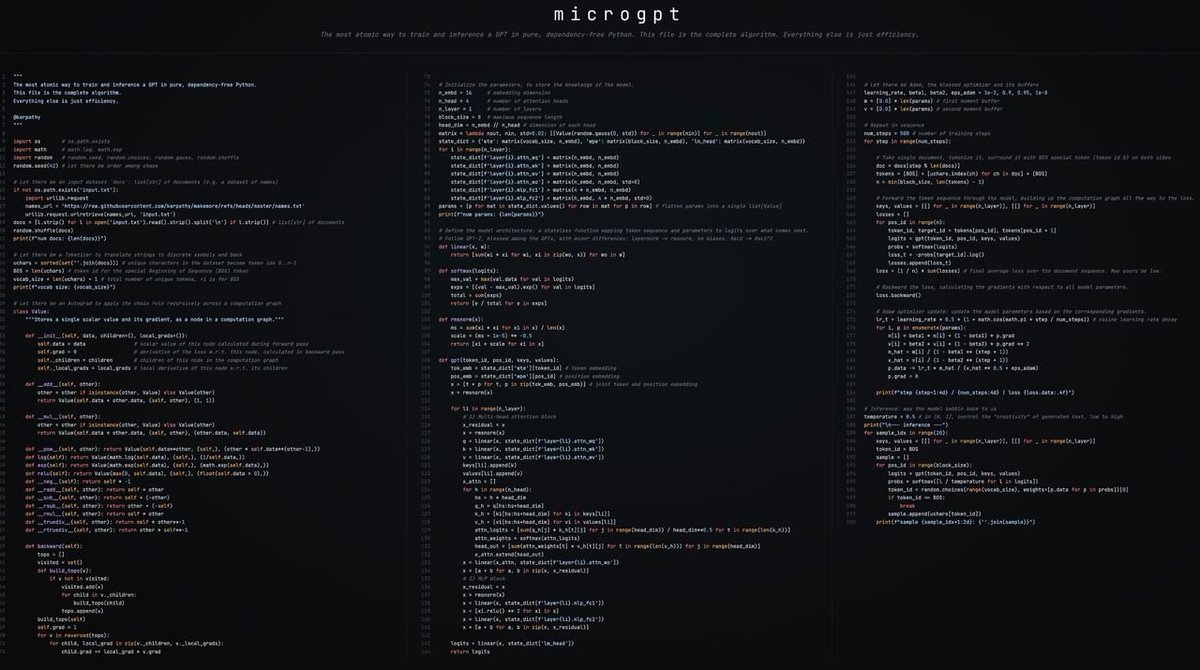
Most beautiful code I have seen shared in public recently.
Built by Andrej Karpathy - single file of 200 lines of pure Python with no dependencies that trains and inferences a GPT. This is how it should be taught to everyone trying to get into learning LLMs.
This might be the cleanest, most elegant public code drop in AI this year.
Karpathy's new "art project": microgpt (https://t.co/itMLfmOu5l)
→ Single Python file (~200 lines)
→ No PyTorch, no NumPy, no external libraries at all
→ Full working GPT: data loading → character tokenizer → tiny autograd engine → GPT-2-style transformer → Adam optimizer → training loop → inference/sampling
It's the bare-metal essence of what makes large language models tick - everything else (CUDA kernels, distributed training, mixed precision, flash attention, massive datasets…) is optimization & engineering around this core.
Perfect starting point for anyone trying to truly understand LLMs instead of just calling APIs.
Highly recommend reading + running it. Changes how you see "AI is just matrix multiplies + softmax" from abstract → concrete.
"Math for Programming: Learn the Math, Write Better Code"
by Ronald T. Kneusel
https://t.co/A092BxRY9B
Contents:
1. Computers and Numbers
2. Sets and Abstract Algebra
3. Boolean Algebra
4. Functions and Relations
5. Induction
6. Recurrence and Recursion
7. Number Theory
8. Counting and Combinatorics
9. Graphs
10. Trees
11. Probability
12. Statistics
13. Linear Algebra
14. Differential Calculus
15. Integral Calculus
16. Differential Equations