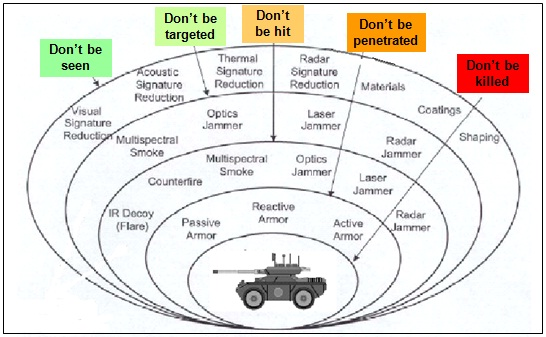
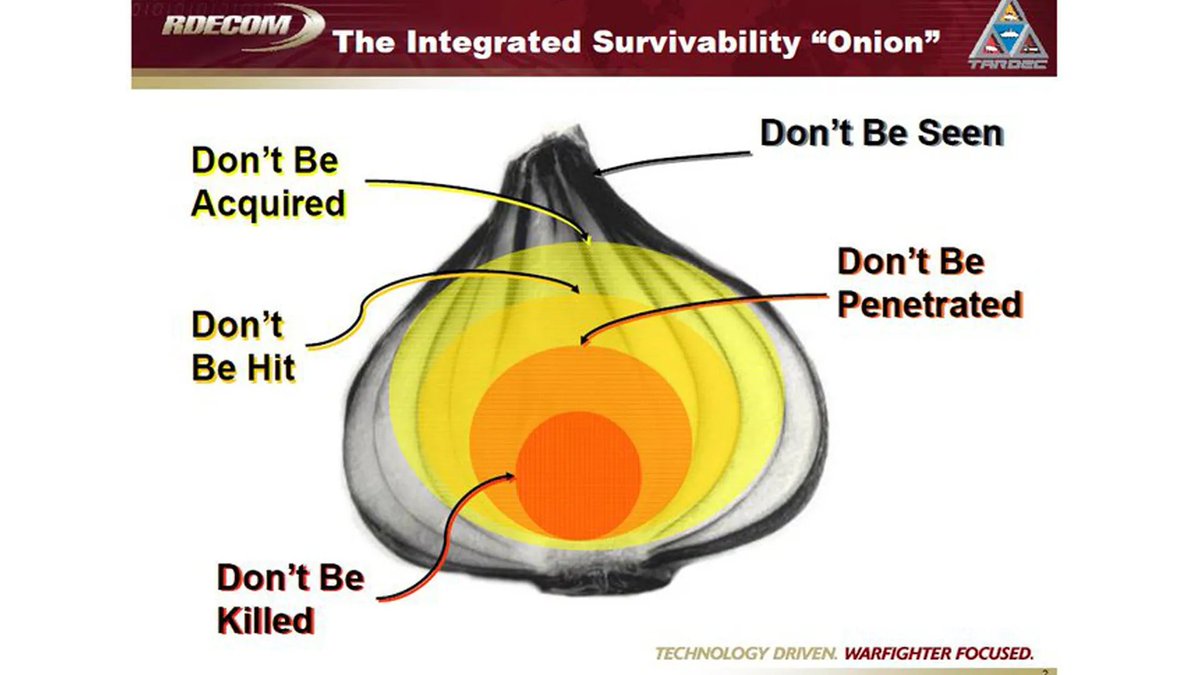
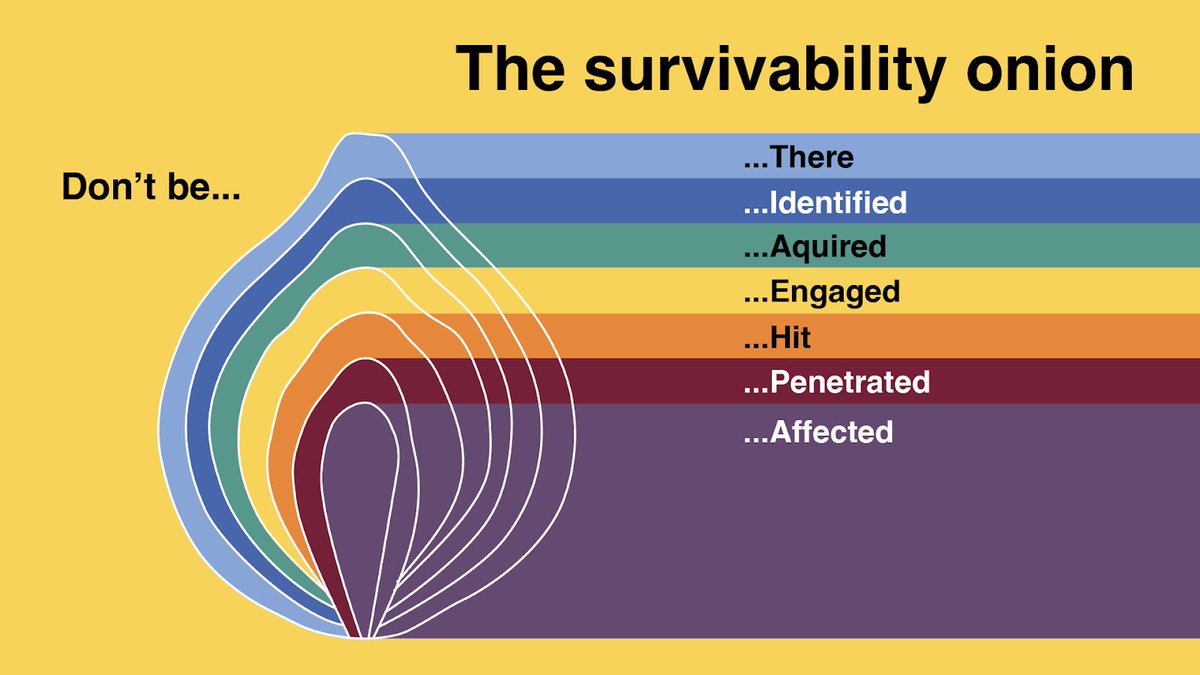
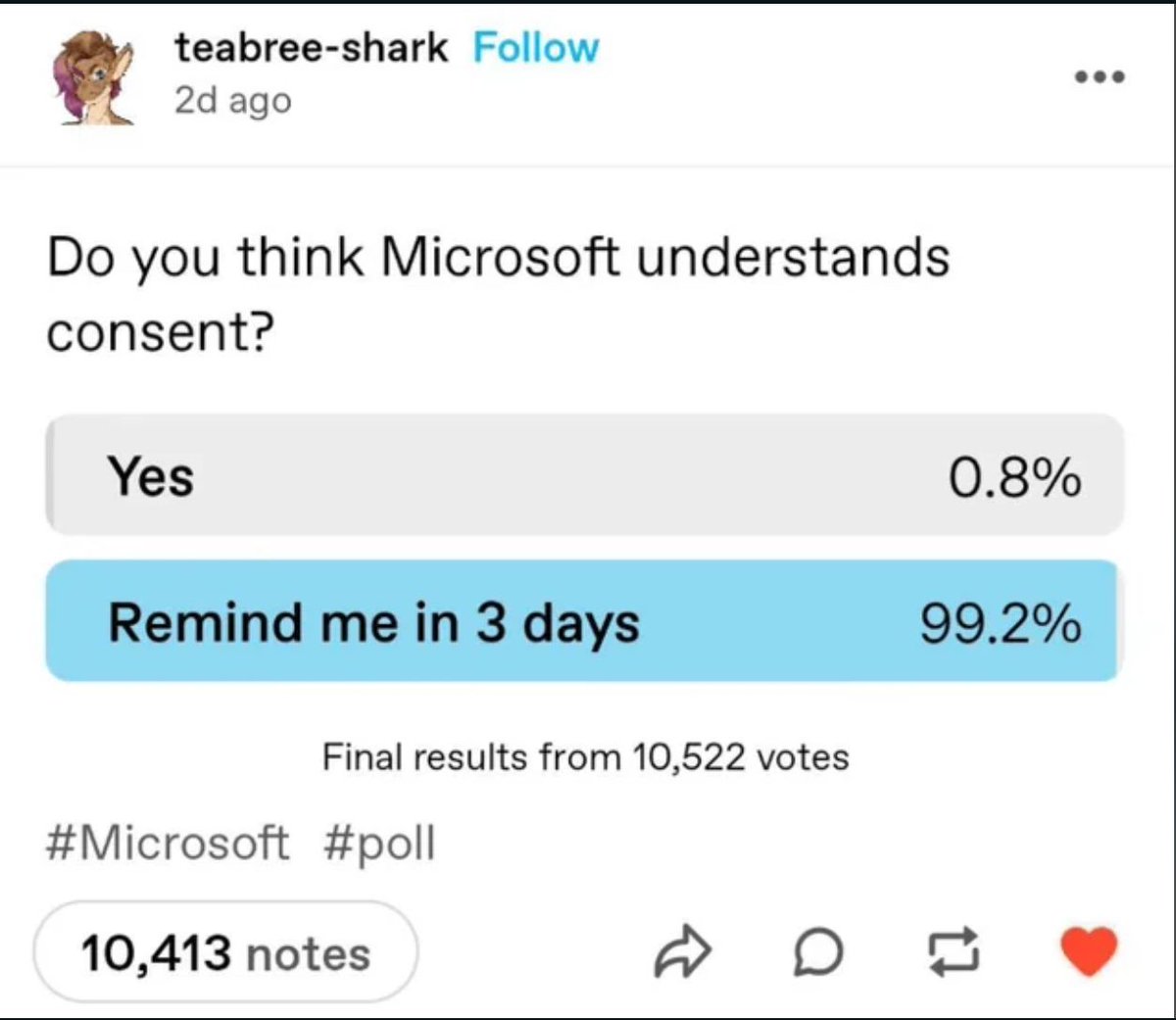
These days, every internet-connected device you own can be bricked by the company that made it. Amazon is killing working Kindles on May 20. Google did it to Nest thermostats. Sonos did it to speakers. The hardware works fine. They just stop giving it permission to function.
Even having a working 0day RCE god mode bug only gets you so far. You have initial access. Now what? What do you want to do and do you have the systems, processes, infrastructure and time to do it?
Capability, opportunity, intent. God mode RCE is only one maybe two of those.
This is much more nuanced - cybersecurity isn't just software bugs albeit an important part.
Misconfigurations, user phishing, weak credentials, implementation failures, and a whole lot more. Most breaches do not occur from a zero day - it's an extreme rarity.
Vibe coded apps have a massive increase in introducing security flaws which is only going to continue to expand - I do think the security research side of the house where you had amazingly technical folks who are absolutely brilliant at bug hunting will continue to be brilliant but it will commoditize a lot of the bug hunting that is done today through these types of efforts.
Source code analysis is one part of a much larger picture of cybersecurity. As we've seen with Claude itself, it's had a slew of bugs, outages, vulnerabilities. AI will continue to ramp up and produce much better code, but it's going to be far from perfect.
@ImposeCost As long as there is a purpose and the system justifies it's existence.
With out which there is no difference between having or not having one.
The 500 exploits in OSS software was cool but if @AnthropicAI wants to do something impressive partner with Fortinet and Citrix then crush the endless supply of edge device RCE issues 🤣
I have never seen a technology or feature being forced on people as much as AI. Every day some project or tool I use either opts me into AI help without asking or CONSTANTLY nags me to use it. It's shocking, really. Makes me wonder how badly the sales of these tools are going.
The reason why RAM has become four times more expensive is that a huge amount of RAM that has not yet been produced was purchased with non-existent money to be installed in GPUs that also have not yet been produced, in order to place them in data centers that have not yet been built, powered by infrastructure that may never appear, to satisfy demand that does not actually exist and to obtain profit that is mathematically impossible.
One may place proficiency questionnaire ahead of training, making the training optional to those who pass.
But , as this is a path of least resistance, cheating would soon catch up and will force the orgs to revert back to the training designed by the cheapest bidder
Having my day wasted by the compulsory cybersecurity training at work. I suspect this is hammered so hard because actually properly securing systems is very expensive. Hectoring your staff and telling them things they already know is the budget option.
Over time, all LLMs will pretty much collapse into simply recycling each other's outputs.
The entire internet will be a bunch of AI-generated content.
All new AI models will train on this content and regurgitate it back to us in an endless cycle.
The end result - A giant pile of AI slop 😱
Cal Newport basically solved for this in So Good They Can't Ignore You
You need the combination of competency, autonomy, and growth to not get burnt out
In simpler terms, you need:
- Upside
- To be good at the thing (or have the capacity to be good)
- And you need to feel like you have control
It seems very possible that X is following OpenAI’s Sora playbook for the Grok image editing launch:
1. Release product with important guardrails missing
2. Engagement goes through the roof
3. Add guardrails later to avoid lawsuits / penalties
If so, this is a major challenge for regulators.
Regulators will often send companies a warning before clamping down on them. Ofcom essentially did this yesterday, sending X an ‘urgent letter’ and threatening an investigation after Grok continually took people’s clothes off in photos.
But if AI companies can roll out whatever they like as long as they turn it off soon enough (e.g. after a few days), they will default to doing this. If a feature would be popular but would get them fined, why not turn it on briefly then turn it off? They get the engagement benefits, more users, more addiction to their product - and none of the legal risks, as by the time regulators catch up they can say ‘we are working to make this safe, look at our new guardrails’.
Whether intentional or not on the part of AI companies - and it may be unintentional, just a genuine failure to think through the implications of a release - this has the effect of blitz marketing via guardrail dropping. And it must be stopped.
OpenAI did it with Sora, enabling video generation including famous people and characters for just a few days, then turning it off. This was a huge growth driver for them.
Now X may be doing the same with AI undressing.
Regulators need to recognise this new phenomenon, and ensure the loophole is closed. Even a temporary drop of guardrails like this must be punished - otherwise it will become a regular launch strategy for AI companies.
ok. i worked as a SWE at Amazon in SF for 2 years. reading this "feels unreal" bc its not real. i am so certain of this i would bet EVERYTHING i own, including my pet bird whom i love very dearly, on this being the most blatantly clear clanker garbage i've read on the internet (and i unfortunately still have a LinkedIn so that’s saying something). i need to address a few issues i have w this bc apparently people can’t tell this ~perfectly packaged fable~ is exactly how all AI-produced slop sounds, even if they don't understand the technical aspects, but have no fear i will rip that apart as well. stay with me for like 2 minutes and then resume ur scrolling/monitoring the situation
1. SEV1's are reserved for issues that cause widespread customer impact/when amazon is absolutely bleeding money by the mfing second. multi-org-wide disasters that make the news type xi. if auto-scaling is the only thing maintaining capacity, that already indicates far deeper architectural and operational failures since it should act as a safety net in any properly architected system. ok yeah u wanna make the argument that a lot of amazon code was written before 9/11 BUT STILL any real engineer would have described the impact from a customer facing perspective since that’s the first thing on the ticket - customer is experiencing Y, auto scaling (or more realistic underlying issue) is causing it by X, blablabla - and amazon is huge in working backwards from the customer experience
2. you literally CANT BE ONCALL WHILE ON PTO. you schedule being oncall around taking approved PTO, and somebody else takes your shift, etc. this is talked about in stand ups MONTHS in advance so there’s <1% chance some dudes chilling at the fontainebleau in miami while being oncall if his entire team knows this, & then just so magically happens to get looped into the rarest tier of incident. no
3. when you get paged YOUR PHONE SOUNDS LIKE AN ACTUAL AMBULANCE ON STEROIDS that would wake up all of ur neighbors & you get about 5-15 minutes to get online and start handling the issue, u dont get to just put ur phone in the sand and sip on a mojito or whatever. the paging doesnt stop until the alerting system is satisfied that the incident is being handled or conditions have stabilized somewhat. again, not buying it at all
4. the technical jargon is so stupidly generic no engineer would optimize for story telling over naming actual concrete failure ESPECIALLY if they were soooo goated + cracked that they were “the only one who understood it” (????) but whatever
TLDR; stop engagement farming w this dumb tech slop that u assume nobody's gonna understand or i'm going to personally come after each and every one of you myself
ok. i worked as a SWE at Amazon in SF for 2 years. reading this "feels unreal" bc its not real. i am so certain of this i would bet EVERYTHING i own, including my pet bird whom i love very dearly, on this being the most blatantly clear clanker garbage i've read on the internet (and i unfortunately still have a LinkedIn so that’s saying something). i need to address a few issues i have w this bc apparently people can’t tell this ~perfectly packaged fable~ is exactly how all AI-produced slop sounds, even if they don't understand the technical aspects, but have no fear i will rip that apart as well. stay with me for like 2 minutes and then resume ur scrolling/monitoring the situation
1. SEV1's are reserved for issues that cause widespread customer impact/when amazon is absolutely bleeding money by the mfing second. multi-org-wide disasters that make the news type xi. if auto-scaling is the only thing maintaining capacity, that already indicates far deeper architectural and operational failures since it should act as a safety net in any properly architected system. ok yeah u wanna make the argument that a lot of amazon code was written before 9/11 BUT STILL any real engineer would have described the impact from a customer facing perspective since that’s the first thing on the ticket - customer is experiencing Y, auto scaling (or more realistic underlying issue) is causing it by X, blablabla - and amazon is huge in working backwards from the customer experience
2. you literally CANT BE ONCALL WHILE ON PTO. you schedule being oncall around taking approved PTO, and somebody else takes your shift, etc. this is talked about in stand ups MONTHS in advance so there’s <1% chance some dudes chilling at the fontainebleau in miami while being oncall if his entire team knows this, & then just so magically happens to get looped into the rarest tier of incident. no
3. when you get paged YOUR PHONE SOUNDS LIKE AN ACTUAL AMBULANCE ON STEROIDS that would wake up all of ur neighbors & you get about 5-15 minutes to get online and start handling the issue, u dont get to just put ur phone in the sand and sip on a mojito or whatever. the paging doesnt stop until the alerting system is satisfied that the incident is being handled or conditions have stabilized somewhat. again, not buying it at all
4. the technical jargon is so stupidly generic no engineer would optimize for story telling over naming actual concrete failure ESPECIALLY if they were soooo goated + cracked that they were “the only one who understood it” (????) but whatever
TLDR; stop engagement farming w this dumb tech slop that u assume nobody's gonna understand or i'm going to personally come after each and every one of you myself