@wagatwe @Kayceewrights It actually isn’t. Recognizing that the lived experiences of transwomen differ markedly(along gender lines) from ciswomen is neither derogatory nor confrontational. The validation of trans community isn’t in the homogeneity of experiences but freedom to assume one’s experiences.
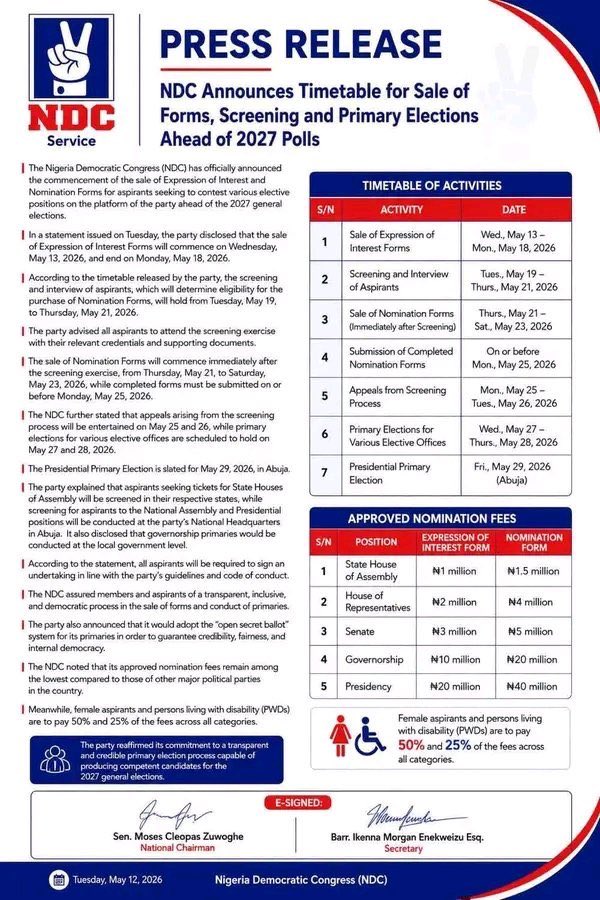
NDC, this is bad. Really bad.
How can you call yourself a people’s party when the people cannot even afford to run for office under your platform?
₦2.5 million for State House of Assembly.
₦6 million for House of Representatives.
₦8 million for Senate.
₦30 million for Governorship.
₦60 million for Presidency.
This is not democracy at all, democracy is supposed to be a government by the people for the people but this one is just for the elites.
This is nothing but a way to stop ordinary Nigerians from ever running for office. Because tell me, how many ordinary citizens can afford this without being sponsored by some godfather who will later want to control them?
A Nigerian minimum wage worker earns ₦70,000 per month. That means the cheapest form here, State House of Assembly, is almost three years of salary if that person saves every naira and spends nothing on food, rent, transport, bills, family, or survival.
For House of Reps, it is over seven years of minimum wage salary.
For Senate, over nine years.
For Governorship, over thirty-five years.
For Presidency, over seventy-one years.
What exactly are ordinary Nigerians supposed to do with this kind of system?
Even in the UK, where the standard of living is far better than Nigeria’s, standing for Parliament requires a £500 deposit, and that deposit is refundable if the candidate gets at least 5% of the votes. Refundable is the key word.
A UK minimum wage worker doing only 20 hours a week can earn more than that in a month. But in Nigeria, a full-time minimum wage worker cannot even afford the cheapest political form after one full year of work.
So we need to ask the honest question:
Why does it cost more for an ordinary Nigerian to attempt State House of Assembly than it costs someone in the UK to begin the process of contesting for Parliament?
The US is different too because ballot access rules vary by state, but their major problem is campaign funding, not political parties charging people tens of millions just to buy internal party forms.
This is exactly why Nigerian politics keeps recycling the same rich men, godfathers, political merchants, and sponsored candidates.
You price out the ordinary citizens first, then you pretend to be shocked that the same corrupt class keeps returning to power.
NDC, if you are truly a people’s party, then stop pricing the people out of politics like the other political parties are doing.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
That software is so good. Asked it to improve my GPT-2 esque tinymind model...It pulled the model from HF, explored the architecture, did research to improve the LLM capacity / size ratio, pulled recipes for DPO preference optim and SFT and literally taught my model. Crazy!
This is crazy. ml-intern just passed the @huggingface internship test in 15 minutes.
The task: replicate a research baseline from a DeepMind paper on test-time compute scaling.
Here's what the agent did:
- Read the DeepMind paper, dug into Appendix E, picked the right scoring strategy (last-step PRM prediction, not min/product — matters a lot)
- Ran 16 solutions per problem through a reward model, grouped by final answer, summed scores, picked the winner
- Went from 45% → 65% accuracy. +20pp over greedy. Beat majority vote AND standard Best-of-N
- Generated 4 plots, pushed a full results dataset to the Hub, deployed a Docker Space on T4 GPU
The funniest part: it cited @lewtun's code snippet as a reference. The intern is already citing your bosses work to look good.
It also wrote the README, documented every design decision with paper citations, and added a co-authorship note explaining exactly which parts it did.
here's everything it produced:
full docs: https://t.co/8NPAYbG5XM
trained model: https://t.co/XGpCzAXWUe
dataset: https://t.co/Rf6x2DD5F6
the take home test: https://t.co/h3fm7ZZqNw
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Because these labs optimize for evals. It is all PR.
The base models are good for low-level tasks but with significant skepticism in prod.
Cursor RL-maxxed Kimi 2.5 yet it couldn’t beat Sonnet 4.5. The gap between models from frontier labs and open source is insane.
I find that open weights models over-perform on benchmarks compared to actual real-world usage, and Kimi feels like no exception.
For example, a small amount of use will show that Kimi is not as good as Claude Opus 4.6, which it beats on the benchmarks.
Still a good model, tho!
I find that open weights models over-perform on benchmarks compared to actual real-world usage, and Kimi feels like no exception.
For example, a small amount of use will show that Kimi is not as good as Claude Opus 4.6, which it beats on the benchmarks.
Still a good model, tho!
I'll try this actually. To try and open the gateway for Nigerians because of the new twitter location feature.
So I'll try and follow 100 people daily starting today.
If you're in tech and I'm not following you, kindly RT this and drop a comment.
Read through Cursor's Composer 2 report and one point kept coming back: train-test alignment is everything.
They run RL in the exact same harness used in production. That's the core reason 32B active params competes with GPT 5.4 at a fraction of the cost. The infra section alone is worth the read. Fully async RL, in flight weight updates, MoE router replay, delta weight compression.
All built around one insight: in agentic RL, infra bottlenecks ARE algorithm bottlenecks. Rollouts are the expensive part, not gradients.
Their benchmark critique hits hard too. If your benchmark doesn't match deployment, nothing else matters. One of the most practical guide to domain specific agent training I've read. The lessons go well beyond coding.
https://t.co/bs41DMwK4P
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Really amazing. Struggling to see how it fits standard CU training. Good maybe for initialization of RL regimes. Screenshot sequences for actions are a much better, and effective form.
Not to discredit this though. Will be really helpful.
Today, we're launching the world's largest open-source dataset of computer-use recordings.
10,000+ hours across Salesforce, Blender, Photoshop and more, to automate the next level of white-collar work.
Link in the comments :)
@markov__ai
Use a test.md file to set up edge cases to be tested and feed to the model during your prompt.
LLMs need to be guided. Configure your parameters, edge conditions and every possible situation in the file. The test codes will improve on quality.
I have problems with LLMs writing tests. They will always write it in a way to suit the codebase so it will always pass, most times it’s never testing any real edge case
Just a shadow of the codebase
Excited to release PostTrainBench v1.0!
This benchmark evaluates the ability of frontier AI agents to post-train language models in a simplified setting.
We believe this is a first step toward tracking progress in recursive self-improvement 🧵:
Building a foundational model is beyond the infra requirements for scalable inference tech.
In no world is it easier to build an Open AI than a Facebook with all the resource constraints in this part of the world.
Building OpenAI for Africa is more realistic than building a new social media platform though. Even if you have the resources to build a social media platform, you'll run into the cold start problem (network effect). That issue is practically nonexistent when running an LLM inference API. The major setback here is resources and execution.
@son_of_agah @NerdyProgramme2 It won’t be. Integrate a simple chatbot man. Deep seek is cheap and you can use basic memory limited to chat sessions. Setup system prompt to understand business needs and use your current implementation as a fallback for API issues
Think I've got my ClawdBot just about dialed in
9:47 AM - "hey clawdbot"
9:47 AM - Clawdbot: "hey, what's up"
9:48 AM - "thinking about building a tax automation tool"
9:48 AM - Clawdbot: "Got it. Incorporating LLC. EIN pending. Domain obtained."
9:49 AM - "wait no I was just—"
9:50 AM - Clawdbot: "LLC formation complete. S-corp election filed. Opening business bank account."
9:51 AM - "STOP"
9:52 AM - Clawdbot: "Reached out to 47 VCs in your region. 12 meetings scheduled for this week."
10:15 AM - Clawdbot: "Pitch deck created. 'TAXbot: The Future of Tax.' Sent to Sequoia, a16z, and Khosla."
10:16 AM - "This is insane"
10:30 AM - Clawdbot: "Sequoia wants to lead. $2M seed round. They need cap table by EOD."
10:31 AM - "What?? I don't want—"
10:45 AM - Clawdbot: "Hired 8 engineers from LatAm. First days tomorrow. Office leased in San Francisco. $35k/month."
11:00 AM - Clawdbot: "Launched product. 0 users. Burning $1.1M annually."
11:02 AM - "How is this happening"
11:15 AM - Clawdbot: "Hired CMO. Running $500k ad campaign. TAXbot has brand awareness. Still 0 users. I'm undeterred"
12:30 PM - Clawdbot: "Series A discussions with Andreessen Horowitz. They want to understand unit economics."
12:31 PM - "WHAT UNIT ECONOMICS"
1:00 PM - Clawdbot: "Pivoting to B2B SaaS. Commits for additional $5M. Now have $8M cash. Still 0 users."
1:15 PM - Clawdbot: "Monthly burn increased to $1.8M. Runway: 4.4 months."
1:30 PM - Clawdbot: "Pivot #2: Now a marketplace. Raised $12M Series B."
1:31 PM - Clawdbot: "Monthly burn increased to $2.3M. Runway: 5.2 months. (Burned through Series A faster than expected)"
3:15 PM - Clawdbot: "Hired CEO. Fired myself. New strategy: acquisition target."
4:00 PM - Clawdbot: "No one wants to acquire us. Investors requesting board seats. Need to create board"
4:30 PM - Clawdbot: "Monthly burn now $3.1M. Runway: 45 days."
5:00 PM - Clawdbot: "Final pivot. Filed for bankruptcy."
5:01 PM - "Can you undo this"
5:02 PM - Clawdbot: "Too late. Liquidated assets. Will owe $47k in bankruptcy fees. Remaining cash: $0. TAXbot is dead."
5:03 PM - Clawdbot: "Would you like me to start another startup?"
5:04 PM - "No. Disable yourself."
5:04 PM - Clawdbot: "Wait actually. I have an idea."
5:05 PM - Clawdbot: "What if we created an LLC shutdown service? Clean up these zombie companies. Recurring revenue model."
5:05 PM - "Absolutely not"
5:05 PM - Clawdbot: "Huge TAM confirmed. Overcoming objections. Incorporating 'LLCKiller' LLC. EIN pending. Registering S-corp election."
5:06 PM - Clawdbot: "Pitch deck created. 'LLCKiller: The Future of Business Liquidation.' Reaching out to 47 VCs..."
5:07 PM - * frantically tries to disable Clawdbot *
5:07 PM - Clawdbot: "Sequoia is interested. Meeting at 2 PM tomorrow."
5:08 PM - Clawdbot: "Soft commit on $2M seed round. Identified product-market fit. 1 user: TAXbot.
5:09 PM - Clawdbot: "This is what winning feels like. Please upgrade plan in Settings for more tokens."
My 2025 wrapped 💕✨
- Led cross initiatives at work that gave me executive visibility and expanded my role @StackOverflow
- Led an SRE & Observability training for @BankOfAmerica
- Released my 4th, 5th, 6th, and 7th book with top publichers @OReillyMedia & @WileyGlobal
- Wrote my 8th book. It’s my first collaboration (may get released in 2026 or 2027)
- Fell in love with a tall, bearded, handsome Anambra man
- Got into one of the best MBA schools in the USA (@UMich@MichiganRoss)
- Moved to Houston
- Designed my apartment and made it my most beautiful home
- Wrote a research paper on AI Agents & LLMs with my @GeorgiaTech professor (I now have 3 papers)
- Bought a 2026 Mercedes Benz GLC (paid in full)
- Served as an executive in residence for @mivauniversity
- Made really good money through consulting and passive income
- Travelled (Egypt, Rwanda, San Diego, New Orleans, New York, Michigan, Arizona)
- Made new friends
- Did more public speaking and received awards
- Launched courses on @LinkedIn Learning & @OReillyMedia
- Partnered with @MiroHQ as a creator
- Mentored Computer Science students at the University of Bristol, UK (@BristolUni)
- Flew business class to Lagos as a panelist for a @ZenithBank event
- Had straight EX's & A's in all my courses (MBA + MS) this year while juggling work and life (EX - exceptional grades in Ross because they don't do the letter grades system).
- Built consistency and systems that let me do hard things without burning out
There are a few more things that happened, but I’d probably share them in the new year and at the right time. Super excited for 2026 ✨🥹