Outcome reward models: cheap, but vulnerable to spurious shortcuts 😣
Process reward models (PRMs): robust, but too expensive to build from scratch 😫
What if you could get a ready-to-use PRM right after any RL post-training?
Introducing 'Progress Advantage' 🧵
Outcome reward models: cheap, but vulnerable to spurious shortcuts 😣
Process reward models (PRMs): robust, but too expensive to build from scratch 😫
What if you could get a ready-to-use PRM right after any RL post-training?
Introducing 'Progress Advantage' 🧵
Agent RL training can be fragile and far less stable than reasoning RL. In our latest work, we identify and explain a phenomenon called Cyclical Entropy Eruption: a recurring instability unique to agent RL where entropy erupts, recovers, and erupts again throughout training. 🧵
📄 https://t.co/ww3M5RHO7s (led by @Wendi_Li_ and @shawnim00)
We decompose it into three phases:
Phase 1 Entropy Descent. The model first learns the basics: how to call tools, satisfy schema constraints, and use the right format tokens. Probability mass shifts rapidly from invalid outputs to valid trajectories. Entropy drops fast.
Phase 2 Entropy Eruption. The core instability. Correct and incorrect agent trajectories end up extremely close in representation space, far more overlapping than in non-agent tasks. This causes gradient interference: when RL suppresses bad trajectories, it accidentally drags down the likelihood of good ones too. The policy flattens, entropy spikes, and degenerate patterns like sentence duplication and hallucination emerge.
Phase 3 Entropy Subsidence. The flatter distribution leads to more diverse sampling, which reduces representation similarity and eases interference. Training recovers... but then reconverges, similarity rises again, and the next eruption begins. A self-perpetuating cycle.
The damage compounds. Degenerate patterns acquired during eruption persist and accumulate across cycles. In the worst case (Llama3.2-1B on WebShop), a single eruption triggers complete training collapse.
Motivated by our analysis, we propose SEAL (Separation-Enhanced Agent Learning)--a lightweight auxiliary loss that pushes correct and incorrect trajectories apart in representation space, directly targeting the root cause.
SEAL stabilizes training and improves performance across AlfWorld, WebShop, and search-augmented QA, on both Qwen and Llama backbones, with GRPO and GIGPO. On a Llama run where vanilla GRPO completely collapsed (0% success), adding SEAL recovered performance to ~80%.
💡The broader takeaway: agent RL is a fundamentally different optimization problem than reasoning RL. The multi-turn structure, tool interactions, and validity constraints create training dynamics that deserve their own analysis. We hope this work helps the community build more stable agent post-training pipelines.
Code is available in the paper!
Best-of-N sampling is often used to boost LLM performance, but the selection relies on external evaluators, adding cost and bias. What if you could select the best output without any external scoring at all?
Introducing our #ACL2026 paper ModeX: Evaluator-Free Best-of-N Selection for Open-Ended Generation! (led by Hyeong Kyu Choi @HyeonggyuC)
💡 Our key insight: among multiple LLM generations, high-quality outputs tend to cluster together semantically. The best answer is the modal one: the generation that captures the dominant consensus.
How ModeX works:
1⃣ Build a similarity graph over N candidate generations
2⃣ Recursively apply spectral clustering via the Fiedler vector to isolate the dominant semantic cluster
3⃣ Select the centroid of that cluster as the final output
No reward models. No external evaluators. No auxiliary inference. Just the texts themselves.
📊 Results across text summarization (CNN/DailyMail), code generation (HumanEval), and math reasoning (Math-500) show ModeX consistently outperforms single-path and multi-path baselines, achieving state-of-the-art among evaluator-free methods.
We also provide theoretical justifications connecting our graph-based mode selection to kernel density estimation, grounding the approach with principled foundations.
📄 Paper: https://t.co/QfPXgqmUHF
💻 Code: https://t.co/YdCpupdnMp
Sometimes the best signal is already hiding in the samples; you just need to find the mode. 🎯
🤖 How do you detect VLA failures during execution with only trajectory-level labels?
Excited to share our new paper:
"Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring"
Almost all animals sleep. Why don’t LMs?
Introducing our new work on language model sleep.
tl;dr : A periodic, recurrent “sleep” phase allows LMs to digest their context and transfer it into their weights, improving recall and reasoning on challenging tasks.
Given this talk a couple of times the past month, and it still resonates with how I'm thinking about research in the era of R&D automation.
It is the golden age of asking questions!
📌 𝐖𝐡𝐞𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐒𝐤𝐞𝐰𝐬 𝐃𝐞𝐛𝐚𝐭𝐞
Here's a slightly delayed post on our #ACL2026 𝐎𝐫𝐚𝐥 𝐏𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 paper!
"𝐖𝐡𝐞𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐒𝐤𝐞𝐰𝐬 𝐃𝐞𝐛𝐚𝐭𝐞: 𝐀𝐧𝐨𝐧𝐲𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐁𝐢𝐚𝐬-𝐑𝐞𝐝𝐮𝐜𝐞𝐝 𝐌𝐮𝐥𝐭𝐢-𝐀𝐠𝐞𝐧𝐭 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠"
(w/ Professor Jerry Zhu and Professor @SharonYixuanLi)
📄 Paper: https://t.co/VKwOeOUrNT
🖥️ GitHub: https://t.co/HaABXQGutg
🤗 Hugging Face Paper: https://t.co/laqzn0Wukk
⚠️ 𝐃𝐢𝐝 𝐘𝐨𝐮 𝐊𝐧𝐨𝐰?
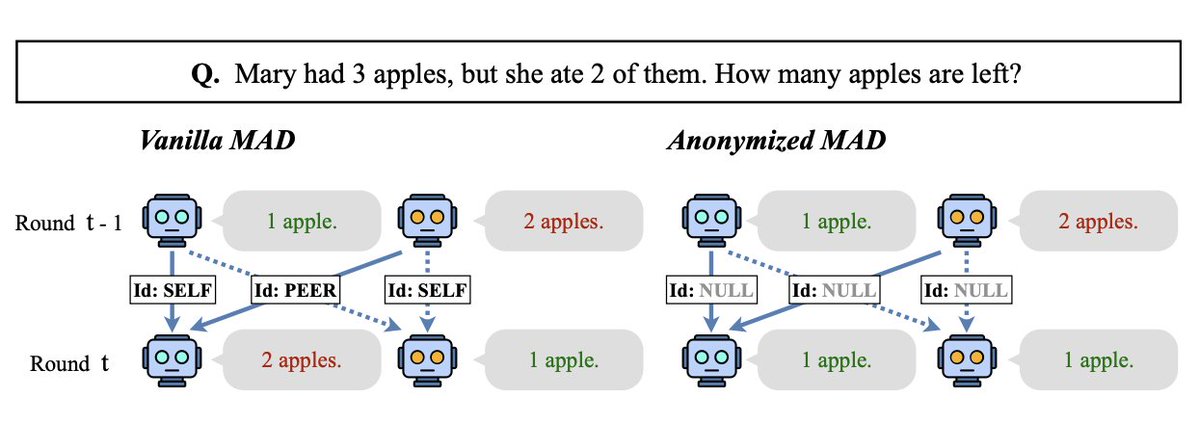
Multi-agent debate is often viewed as a way to make LLMs reason better by letting multiple agents exchange opinions and correct each other. But what if agents are not only judging the content of an argument, but also reacting to 𝐰𝐡𝐨 said it?
In this work, we show that LLM agents in multi-agent debate can suffer from 𝐢𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐛𝐢𝐚𝐬: they may become overly sycophantic toward peers, or overly attached to their own previous answers. These biases can distort debate dynamics, create premature consensus, and undermine the reliability of multi-agent reasoning!
========
🔎 𝐊𝐞𝐲 𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲𝐬
1️⃣ We introduce a principled framework for understanding 𝐢𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐛𝐢𝐚𝐬 in multi-agent debate, unifying two important behaviors: sycophancy toward peers and self-bias toward one’s own prior answer.
2️⃣ We propose 𝐑𝐞𝐬𝐩𝐨𝐧𝐬𝐞 𝐀𝐧𝐨𝐧𝐲𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧: a simple intervention that removes identity markers from debate transcripts, forcing agents to evaluate arguments based on content rather than attribution.
3️⃣ We introduce the 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐁𝐢𝐚𝐬 𝐂𝐨𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭, a metric for quantifying whether an agent is biased toward following peers or sticking with itself.
========
💡 𝐖𝐡𝐲 𝐓𝐡𝐢𝐬 𝐌𝐚𝐭𝐭𝐞𝐫𝐬
🔺 Multi-agent debate is becoming an important paradigm for improving LLM reasoning, but debate only helps if agents respond to arguments, not identities.
🔺 Our results show that LLM agents can be surprisingly sensitive to whether a response is labeled as coming from "self" or "peer", even when the underlying content is what should matter.
🔺 Response anonymization is lightweight and practical: it requires no retraining, no architectural changes, and no additional verifier. Just remove identity cues and let agents reason over the content.
========
#ACL2026 #OralPresentation #AI #ArtificialIntelligence #MachineLearning #DeepLearning #LLM #MultiAgent #MultiAgentSystems #NaturalLanguageProcessing #ReliableAI #TrustworthyAI #AIAgents #Debate #Sycophancy #Bias