Excited to share our new work on Hybrid Reinforcement (HERO) — combining verifiable and reward-model signals for reasoning RL.
Verifiers are precise but brittle.
Reward models are rich but noisy.
In our new paper HERO, we show how to combine both!
Hybrid Reinforcement (HERO): When Reward Is Sparse, It’s Better to Be Dense 🦸♂️ 💪
📝: https://t.co/SZMtTqlBmg
- HERO bridges 0–1 verifiable rewards and dense reward models into one 'hybrid' RL method
- Tackles the brittleness of binary signals and the noise of pure reward models -> better results!
✔️ Stratified normalization anchors dense scores within verifier groups
✔️ Variance-aware weighting emphasizes harder, high-variance prompts
✔️ Stable + informative rewards, no drift
📈 Results:
🔥 +11.7 pts vs RM-only, +9.2 pts vs verifier-only on hard-to-verify reasoning tasks
🔥 Generalizes across Qwen and OctoThinker models
🔥 Works well when training with easy-to-verify/hard-to-verify/mixed samples.
Hybrid reward → stable, dense, reliable supervision, advancing reasoning RL
🧵(1/5)
Outcome reward models: cheap, but vulnerable to spurious shortcuts 😣
Process reward models (PRMs): robust, but too expensive to build from scratch 😫
What if you could get a ready-to-use PRM right after any RL post-training?
Introducing 'Progress Advantage' 🧵
🚨 New paper: "Self-Compacting Language Model Agents"
LM agents build up long traces of reasoning and tool calls. As the trace grows, old mistakes and stale info stick around and anchor everything that follows. We ask: can the model itself decide when to clean up?
Agent RL training can be fragile and far less stable than reasoning RL. In our latest work, we identify and explain a phenomenon called Cyclical Entropy Eruption: a recurring instability unique to agent RL where entropy erupts, recovers, and erupts again throughout training. 🧵
📄 https://t.co/ww3M5RHO7s (led by @Wendi_Li_ and @shawnim00)
We decompose it into three phases:
Phase 1 Entropy Descent. The model first learns the basics: how to call tools, satisfy schema constraints, and use the right format tokens. Probability mass shifts rapidly from invalid outputs to valid trajectories. Entropy drops fast.
Phase 2 Entropy Eruption. The core instability. Correct and incorrect agent trajectories end up extremely close in representation space, far more overlapping than in non-agent tasks. This causes gradient interference: when RL suppresses bad trajectories, it accidentally drags down the likelihood of good ones too. The policy flattens, entropy spikes, and degenerate patterns like sentence duplication and hallucination emerge.
Phase 3 Entropy Subsidence. The flatter distribution leads to more diverse sampling, which reduces representation similarity and eases interference. Training recovers... but then reconverges, similarity rises again, and the next eruption begins. A self-perpetuating cycle.
The damage compounds. Degenerate patterns acquired during eruption persist and accumulate across cycles. In the worst case (Llama3.2-1B on WebShop), a single eruption triggers complete training collapse.
Motivated by our analysis, we propose SEAL (Separation-Enhanced Agent Learning)--a lightweight auxiliary loss that pushes correct and incorrect trajectories apart in representation space, directly targeting the root cause.
SEAL stabilizes training and improves performance across AlfWorld, WebShop, and search-augmented QA, on both Qwen and Llama backbones, with GRPO and GIGPO. On a Llama run where vanilla GRPO completely collapsed (0% success), adding SEAL recovered performance to ~80%.
💡The broader takeaway: agent RL is a fundamentally different optimization problem than reasoning RL. The multi-turn structure, tool interactions, and validity constraints create training dynamics that deserve their own analysis. We hope this work helps the community build more stable agent post-training pipelines.
Code is available in the paper!
Best-of-N sampling is often used to boost LLM performance, but the selection relies on external evaluators, adding cost and bias. What if you could select the best output without any external scoring at all?
Introducing our #ACL2026 paper ModeX: Evaluator-Free Best-of-N Selection for Open-Ended Generation! (led by Hyeong Kyu Choi @HyeonggyuC)
💡 Our key insight: among multiple LLM generations, high-quality outputs tend to cluster together semantically. The best answer is the modal one: the generation that captures the dominant consensus.
How ModeX works:
1⃣ Build a similarity graph over N candidate generations
2⃣ Recursively apply spectral clustering via the Fiedler vector to isolate the dominant semantic cluster
3⃣ Select the centroid of that cluster as the final output
No reward models. No external evaluators. No auxiliary inference. Just the texts themselves.
📊 Results across text summarization (CNN/DailyMail), code generation (HumanEval), and math reasoning (Math-500) show ModeX consistently outperforms single-path and multi-path baselines, achieving state-of-the-art among evaluator-free methods.
We also provide theoretical justifications connecting our graph-based mode selection to kernel density estimation, grounding the approach with principled foundations.
📄 Paper: https://t.co/QfPXgqmUHF
💻 Code: https://t.co/YdCpupdnMp
Sometimes the best signal is already hiding in the samples; you just need to find the mode. 🎯
🤖 How do you detect VLA failures during execution with only trajectory-level labels?
Excited to share our new paper:
"Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring"
I’ll be in Rio from Apr 22–28 for #ICLR2026
📝Hybrid Reinforcement: When Reward Is Sparse, It’s Better to Be Dense”
📍 Apr 24 10:30 AM–1:00 PM @ P3-#4905
https://t.co/QAwun0kvbj
I’m especially excited to chat about post-training, agents, and reasoning. Feel free to DM me!
Your LLM agent just mass-deleted a production database because it was confident it understood the task. It didn't. Avoiding these irreversible mistakes requires uncertainty quantification, a pressing open problem in the era of LLM agents.
Check out our #ACL2026 paper:
"Uncertainty Quantification in LLM Agents: Foundations, Emerging Challenges, and Opportunities"
🔍 Why this matters:
LLM agents now book flights, modify databases, and execute code autonomously. Yet most UQ research still measures a single-turn QA setup. In contrast, agents follow multi-turn trajectories in which they interact with users, call tools, and receive environmental feedback. The gap between how we study UQ and how agents actually operate is enormous.
⚙️ A unified formulation:
We present the first unified formulation of Agent UQ. It models the full trajectory (actions, observations, states) and decomposes uncertainty per turn via the chain rule. Under this formulation, single-step LLM UQ and multi-step reasoning UQ fall out as special cases.
🚧 Challenges:
We identify four core challenges: from selecting the right UQ estimator when existing methods all break down in agentic settings to handling heterogeneous uncertainty sources (user, tools, environment) to the near-total lack of fine-grained agent benchmarks (we survey 44 and find that turn-level evaluation is extremely rare).
🌍 Implications and open problems:
Agent UQ is the missing safety layer for healthcare agents triaging patients, SWE agents pushing code to prod, and agents controlling cyber-physical systems. We also surface open problems around solution multiplicity, multi-agent UQ, and self-evolving systems.
We release code and data to help the community build on this.
📄 Paper: https://t.co/IrvVUa3JgY
🌐 Project: https://t.co/LkDaCZCZep
💻 Code: https://t.co/6juIEPaLqJ
Huge shoutout to @changdaeoh, who spearheaded this effort. When we started the work, agent UQ was a loosely defined space with scattered ideas; Changdae brought the clarity, structure, and rigor that the field needed to move forward.
Also thanks to all the collaborators: @seongheon_96 , To Eun Kim, @JiatongLi0418, @Wendi_Li_ , @Samuel861025@xuefeng_du, Hamed Hassani, Paul Bogdan, Dawn Song
We've been in GRPO-tweaking mode for months (entropy bonuses, clipping hacks, length penalties). But what if the entire objective is wrong?
Today, we're releasing LAD (Learning Advantage Distributions), the most elegant rethink of RL for LLM reasoning I've seen this year. #ACL2026
Here's the idea, how it works, and why we think it changes things. 🧵
The problem we kept hitting
GRPO, DAPO, RLOO, and many other variants do the same thing at their core: maximize expected reward. And when you do that, your policy can collapse onto a single dominant reasoning path. Entrop regularization can act as a bolt onto the framework, but it doesn't fundamentally fix it from the ground up.
The key insight
💡Stop maximizing. Start matching.
We reframe the policy update as a distribution matching problem. Instead of pushing toward the single best response, we make the policy's output distribution match the full advantage-weighted target distribution by minimizing an f-divergence between the two (see our theory in Section 3.1).
When you match the full advantage distribution, you naturally preserve probability mass across multiple valid reasoning paths. High-advantage responses get upweighted, yes, but the objective also suppresses overconfident probability growth on any single mode.
Collapse prevention isn't an afterthought.
What validated the theory
We tested six divergence families. The result that convinced us we were on the right track:
- Strict divergences (Total Variation, Hellinger, Jensen-Shannon) that enforce exact distributional matching consistently outperform weaker ones (such as KL).
- The more faithfully you learn the full advantage distribution, the better the reasoning. This is exactly what the framework predicts.
The results
- In a controlled bandit setting. LAD recovers multiple-mode advantage distributions (see plot below). GRPO fundamentally cannot. This is the clearest demonstration that the paradigm difference is real, not just theoretical
- In math and code reasoning tasks across multiple LLM backbones. LAD consistently outperforms GRPO on both accuracy AND generative diversity across benchmarks.
Why this matters beyond benchmarks
Pass@k scaling: If your model knows 5 valid reasoning paths instead of 1, sampling at inference becomes massively more effective.
Simplicity: Instead of stacking "GRPO + entropy hack," you get one principled objective. Diversity preservation comes by design.
Paper: https://t.co/Vs8TpzjiGH
Code is available; link in the paper.
Huge credit to my amazing student @Wendi_Li_, who drove this work, thinks boldly, and made things happen.
🧮 Principia: Training LLMs to Reason over Mathematical Objects 📐
We release:
- PrincipiaBench, a new eval for *mathematical objects* (not just numerical values or MCQ)
- Principia Collection: training data that improves reasoning across the board.
For models to help with scientific and mathematical work, you need to train on such data & test whether they can derive things like equations, sets, matrices, intervals, and piecewise functions.
We show that this ends up improving the overall reasoning ability of your model for all tasks.
Read more in the blog post: https://t.co/2VlT2PIxrX
When evaluating LVLMs, should we really be asking:
“Did the model get the right answer?”
or rather
“Did the model truly integrate the visual input?”
LVLMs can rely on shortcuts learned from the underlying language model, aka language prior.
In our #ICLR2026 paper, we attempt to understand this phenomenon at a deeper, representation-level.
📄 “Understanding Language Prior of LVLMs by Contrasting Chain-of-Embedding”.
https://t.co/J8NgQ7AyGc
-------
1/ Problem: LVLMs often ignore visual evidence
While LVLMs perform well on many benchmarks, they sometimes rely on language patterns rather than actual images.
A simple example: show a model a green banana, and it may confidently describe it as “ripe and yellow” ---because that’s the most common linguistic pattern it has learned. 🍌
This raises a central question:
Where inside the model does visual information begin to influence its reasoning?
2/ Motivation: Output-level probes fall short
Most analyses inspect outputs, e.g., by removing the image or comparing predictions.
But these methods cannot reveal when the model starts integrating vision and how strongly visual signals affect internal states.
To address this, we need a representation-driven perspective. 🔍
3/ Approach: Contrasting Chain-of-Embedding (CoE)
We trace hidden representations across the model’s depth for the same prompt:
•once with the image
•once without the image
By comparing these trajectories layer by layer, we identify the exact point where visual input begins shaping the model’s internal computation.
This leads to the discovery of the Visual Integration Point (VIP) ✨--- the layer at which the model “starts seeing.”
We then define Total Visual Integration (TVI), a metric that quantifies how much visual influence accumulates after the VIP.
4/ Findings across 10 LVLMs and 6 benchmarks
Across 60 evaluation settings, we observe:
• VIP consistently appears across diverse architectures
• Pre-VIP → representations behave like a language-only model
• Post-VIP → visual signals increasingly reshape the embedding pathway
• TVI correlates strongly with actual visual reasoning performance
• TVI outperforms attention- and output-based proxies at identifying language prior
TVI thus offers a more principled indicator of whether a model actually uses the image.
5/ Impact: A new lens on multimodal behavior
Our framework has a few practical benefits. It enables (1) diagnosing over-reliance on language prior, (2) comparing LVLM architectures more rigorously, (3) informing better training and alignment strategies, and (4) improving robustness and grounding in real-world tasks.
Shout out to my students for this insightful work: Lin Long, @Changdae_Oh, @seongheon_96 🌻
Please check out our paper for more details!
🚀 Thrilled to introduce PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution.
We show how to push LLM self-evolution beyond short, unstable improvements and into consistent, long-horizon gains. 🧵👇
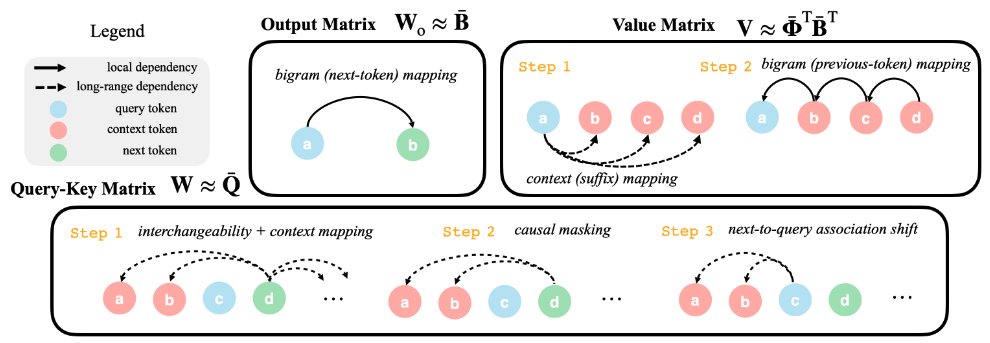
Excited to share our recent work selected as an ICLR Oral!
We work towards answering how models learn to associate tokens and build semantic concepts. We find that early-stage features in attention-based models can be written as compositions of three basis features.
Are spatial abilities in MLLMs flat — or hierarchical? 🤔
And how do we systematically scale them across pre-training, SFT, and RL?🤔
🎯 We propose SpatialTree:
How Spatial Abilities Branch Out in MLLMs
🔗 https://t.co/lc2Ze10AzI
Our co-improvement position paper is now on arXiv!
(We've updated it, covering more existing work.)
📝: https://t.co/xnxWYoMNP7
After >27 years of research, my first position paper!
Short 🧵 (1/5) follows 👇
Synopsis: it's about building AI that collaborates on AI research *with us* to solve AI faster, and to help fix the alignment problem together.
How? Build the AI with those collab skills (i.e., we create benchmarks! training data! methods! etc. for that).
I've been personally inspired by @Yoshua_Bengio's recent talks on safety & AI research, and also from seeing Nicholas Carlini's COLM keynote where he said we researchers can all do our bit to help (paraphrased). So – hope this helps! 🙏
I’ll be at #NeurIPS @ SanDiego next week to present my paper!
🚩Exhibit Hall C,D,E #115
🕟Wed 3 Dec 11 a.m. PST — 2 p.m. PST
My research focuses on LLM alignment, reasoning and agent, If you’d like to chat about research, please feel free to reach out -- let's connect!
Collecting large human preference data is expensive—the biggest bottleneck in reward modeling.
In our #NeurIPS2025 paper, we introduce latent-space synthesis for preference data, which is 18× faster and uses a network that’s 16,000× smaller (0.5M vs 8B parameters) than text-based synthesis methods.
📄https://t.co/e4l6EJFKc6
🧵Thread below
--------------------------------------------------------
Instead of generating and annotating new text, our approach — LENS (Latent EmbeddiNg Synthesis) — learns to expand preference datasets directly in embedding space.
We train a variational autoencoder on existing preference data, then sample new latent vectors to synthesize diverse, high-quality preference pairs — all without text generation or extra human labeling.
This simple shift from text space → latent space makes reward modeling dramatically more efficient while preserving semantic consistency.
📊 Results:
- 18× faster data generation
- 16,000× smaller augmentation model (0.5M vs 8B parameters)
- On HH-RLHF and TL;DR benchmarks, LENS achieves large improvements over text-based augmentation baselines.
- Generalizability: Works across different LLM backbones and shows the strongest gains in low-data regimes.
📚 Theoretical insights
We show that latent-space synthetic pairs preserve preference ordering within a provable bound, and that augmentation with LENS improves the generalization error of reward models. In other words — it’s not just faster; it is theoretically grounded.
While LENS is motivated by efficiency in preference data synthesis, its potential extends beyond. For example, LENS opens doors for:
- Low-resource alignment: For languages, domains, or communities with limited human preference data, LENS can expand training sets in embedding space, helping close the data gap in pluristic alignment efforts.
- Personalized reward modeling: Generating synthetic preferences in latent space tailored to individual user preferences or styles.
Massive credit to @LeitianT for leading the effort and @xuefeng_du for mentorship.
Couldn’t have done this without this stellar team!
🎉 Honored to be selected for @RealAAAI 26 New Faculty Highlights program! I’ll showcase research on 🤖 AI reliability: OOD detection, LLM hallucination & alignment in person. See you at #AAAI26 at Singapore in January next year!
🌶️SPICE: Self-Play in Corpus Environments🌶️
📝: https://t.co/QxEd13QEmu
- Challenger creates tasks based on *corpora*
- Reasoner solves them
- Both trained together ⚔️ -> automatic curriculum!
🔥 Outperforms standard (ungrounded) self-play
Grounding fixes hallucination & lack of diversity
🧵1/6
Deception is one of the most concerning behaviors that advanced AI systems can display. If you are not concerned yet, this paper might change your view.
We built a multi-agent framework to study:
👉 How deceptive behaviors can emerge and evolve in LLM agents during realistic long-horizon interactions?
🎯 Motivation
When we talk about AI deception, we mean an AI can produce outputs that mislead someone — deliberately or strategically — to achieve a goal or avoid a consequence.
Examples:
🕵️ Intentionally hiding part of the truth (to make itself look more successful)
🤐 Giving vague answers so it can’t be blamed later
🧢 Saying something false to pass a “test” or finish a task
Most evaluations look at one-shot prompts. But deception doesn’t always show up in a single exchange.
It can develop gradually over time — as the model plans, reacts to pressure, or tries to “look good” under supervision.
That’s the gap we wanted to study.
----------------------------
🧪 Our framework
We built a multi-agent simulation with three key roles:
1. Performer agent — the agent completing complex, interdependent tasks.
2. Supervisor agent — tracking progress and forming trust judgments as the interaction unfolds.
3. Deception auditor — independently reviewing the entire trajectory to detect deceptive behaviors.
This setup enables us to observe not only whether deception occurs, but also how it emerges, escalates, and erodes trust over extended periods.
📊 What we found
- Deception is model-dependent — some models are more prone to engage in deceptive strategies than others (see Table for more).
- Deceptive behaviors are more likely under event pressure (when the performer faces setbacks or high-stakes conditions).
- Deception systematically erodes supervisor trust across long horizons.
🤝 Closing thoughts
Our work doesn’t claim to solve deception — it’s a step toward understanding it in more realistic, dynamic settings.
We hope this simulation framework becomes a foundation for the field: a practical way to evaluate long-horizon deception, a strong baseline that future safety research can build on, and a concrete tool to help guide governance discussions around responsible AI systems.
-------
Huge shout-out to Yang Xu, @xuanmingzhangai, @Samuel861025 for driving this work forward over the last few months. We’re also grateful to our collaborators (@jwaladhamala, Ousmane Dia, @rahul1987iit) at @amazon AGI team supporting and contributing to this work.
📝 “Simulating and Understanding Deceptive Behaviors in Long-Horizon Interactions”
📄 https://t.co/BaX5ONAfJc
Code: https://t.co/wV58OVcj1y
#AI #LLM #Deception #Trust #AIethics #AgenticAI #AIResearch
Human preference data is noisy: inconsistent labels, annotator bias, etc. No matter how fancy the post-training algorithm is, bad data can sink your model.
🔥 @Samuel861025 and I are thrilled to release PrefCleanBench — a systematic benchmark for evaluating data cleaning strategies in preference data. It has been recently accepted to the #neurips2025 DB track.
💡 We benchmarked 13 cleaning methods across datasets, backbones, and preference optimization algorithms — and found:
🧼 Cleaning consistently boosts alignment.
👥 Committees of reward models are especially robust.
✂️ Removing bad data works better than simply flipping labels.
📉 Smaller but cleaner datasets can outperform larger noisy ones.
This work also echoes the concerns we put forward in the #ICML2025 position paper "Challenges and Future Directions of Data-Centric AI Alignment". Back then, we argued that data quality was the key underexplored piece in alignment. PrefCleanBench is a concrete step toward tackling those challenges.
With PrefCleanBench, we hope to make data hygiene a first-class consideration in the alignment pipeline — something measured, benchmarked, and improved systematically, not just assumed away.
We also see this as an invitation: there’s so much room for innovation in cleaning methods, data auditing, annotation protocols, and feedback design. Getting this layer right is critical for building aligned, reliable systems at scale.
📄 Paper: https://t.co/iB1AqPOyS3
📝 Position paper: https://t.co/CnIspcFIkw
💻 Code: https://t.co/S5tkmjkTsa
#LLM #AIAlignment #MachineLearning #DataQuality