AI should earn its keep. Introducing the AI Productivity Guarantee.
If Devin delivers less engineering value than you’re paying for, Cognition will fund your usage until it does, up to $10 million.
It’s time for the AI industry to stop maximizing tokens and start maximizing productive output.
Noticing a shift in the industry: 6 months ago everybody was tokenmaxxing. Supposedly unlimited token budgets & every CTO was afraid their team’s weren‘t using enough tokens.
This is no longer the case: Our typical customer saw agent usage grow 1000% in the last few months. Suddenly the spend is becoming significant. Of course, it is good to spend as much as possible on tokens if it delivers real productivity gains. However, a lot of tokens are wasted, e.g. through wasteful experiments and inefficient prompting.
Devin is built to ensure you have the fine-grained control over your ROI. If you work with Cognition, we‘re confident you will get the highest "return on tokens" (we should maybe coin a term for it: ROT?) out of any product in the industry. We‘re so confident that we‘re putting our money where our mouth is: we‘ll cover up to $10 million in Devin usage if we don’t deliver positive ROI.
It‘s kind of insane for us to do this and we’re taking a big bet here. We‘re in the position to do this only because of @ryanbai1412‘s research on automated measurement of AI agent productivity. Read our technical blog (linked in the thread below) on how we built a system to predict time savings which we can convert into dollars saved.
What we found: Cognition customers are seeing real & provable ROI on Devin. With our coaching & enterprise-specific Devin features this ROI can be increased further. A lot more to come on this!
Very excited for this! The best research content requires beautiful design. There‘s no better example of this than @3blue1brown‘s video content which has incredible craft. We‘re looking forward to hosting him at our office and celebrating what design & research can do together
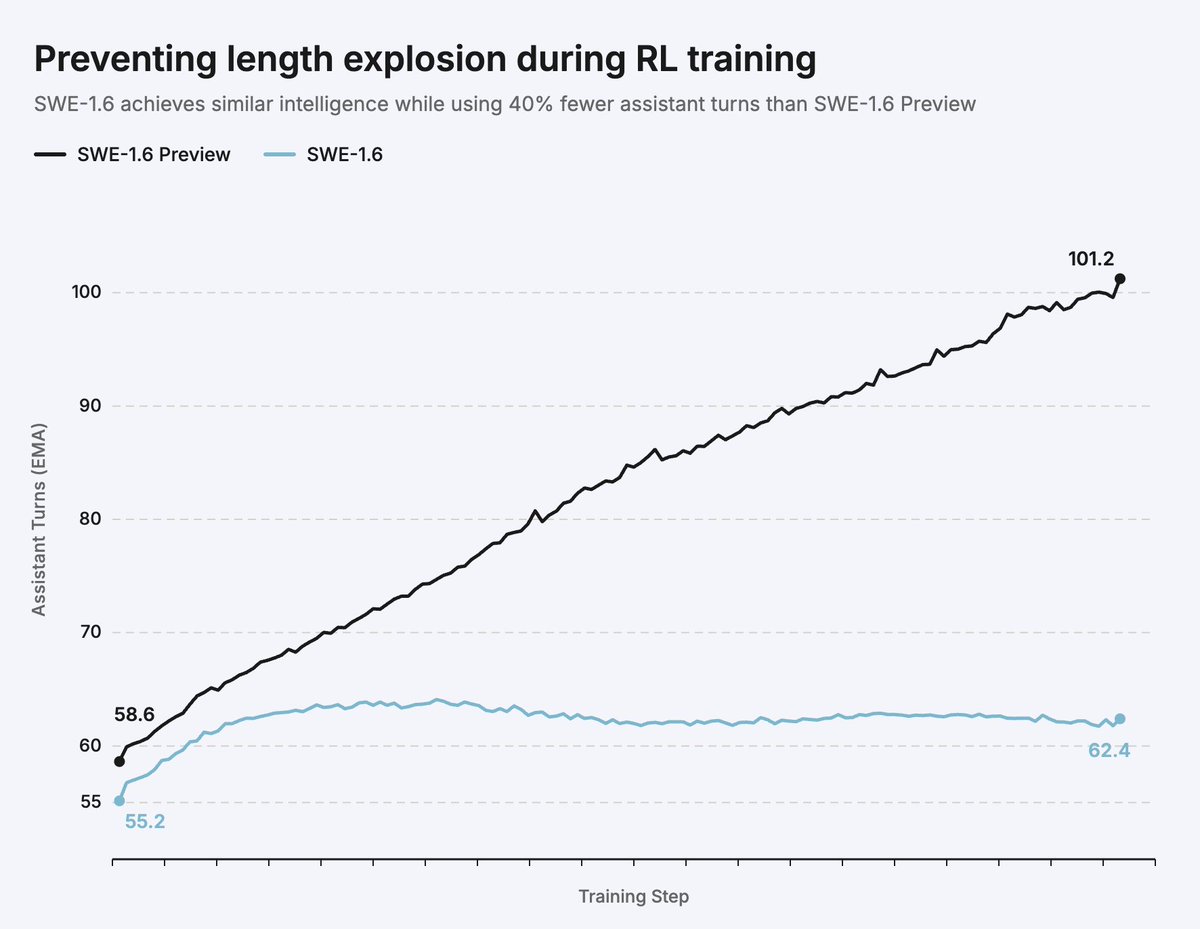
With SWE-1.6 we've made significant progress on "intelligence per token". We post-trained the model from scratch (same pre-trained model) with a similar recipe as SWE-1.6 Preview. Our latest algorithm achieves similar intelligence at ~40% fewer assistant turns.
We also shipped further infra improvements, so our latest training run was 1.6x faster end-to-end for the same amount of FLOPs. In our next training run, we're aiming to 5x the FLOPs.
Over the last few months we started building our research team at Cognition and we've come a long way!
It's been exciting to figure out what it takes to build a large-scale post-training stack from scratch and push towards the frontier. My personal take is it's been easier than expected, e.g. we were surprised to match Opus 4.5 which seemed so far way just 3 months ago.
We definitely still got lots to figure out but the slope is high and this model is just the beginning.
There‘s an underestimated axis in coding models: "delight". Windsurf arena mode probably indexes 60% on delight & 40% on capabilities.
Observations:
- Anthropic is crushing it on delight
- GPT-5.2 & Gemini 3 underperform in delight relative to IQ
- SWE-1.5 outperforms GPT-5.2 here! (I didn’t expect this)
There was a moment in mid Nov when all labs (GPT-5.1, Sonnet 4.5, Gemini 3 Pro) were roughly similar on SWE-Bench in the 76-77% range.
Then Opus charged ahead and broke 80%. GPT-5.2 is now the second model to break 80% (+ new SOTA on SWE-Bench Pro). In day-to-day usage still seeing people prefer Opus but it's early to tell
super excited to finally release SWE-1.5 - a frontier-scale model (~hundreds of billions of params) running at insane speeds (up to 950 tok/s)
- outperforms GPT-5-High on SWE-Bench-Pro
- 13x faster than Sonnet 4.5, 6x faster than Haiku 4.5
- more than double the benchmark perf of SWE-1
it's been fun to scale up RL to large models on our cluster of thousands of GB200 chips. (this might be the first public model release trained on the new GB200 NVL72 generation 🤔)
more details on the training in 🧵
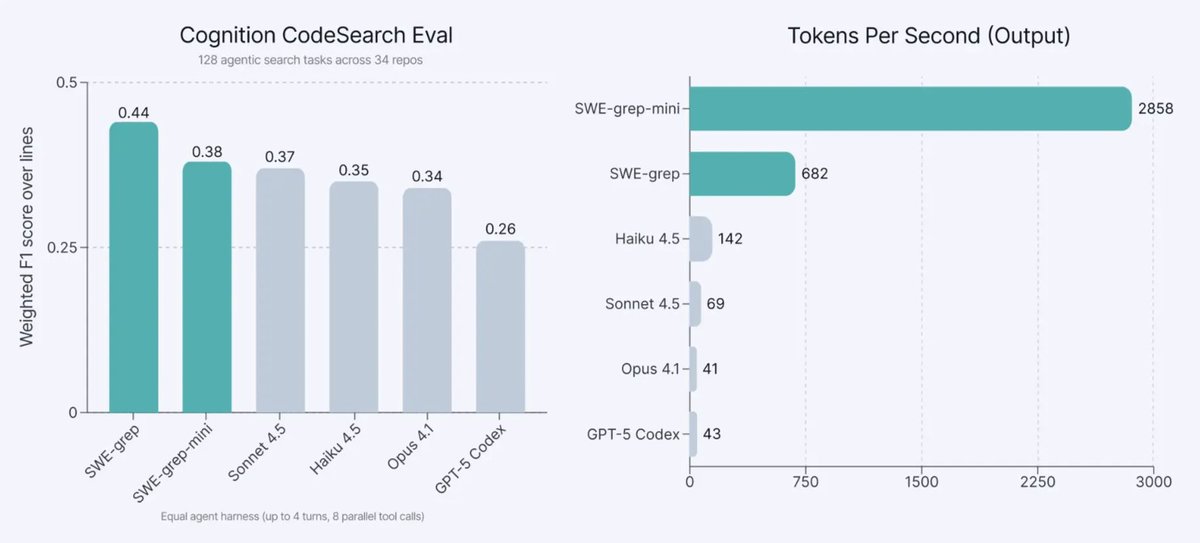
super excited to release SWE-grep and SWE-grep-mini!
SWE-grep-mini achieves extreme inference speeds of >2,800 TPS:
20x faster than Haiku 4.5 while beating Sonnet 4.5, Opus 4.1 & GPT-5 on our CodeSearch eval
our vision: make agentic search as fast as embedding search. the SWE-grep models can perform multi-turn agentic search in <3 seconds compared to 20-60 seconds for other frontier models.
https://t.co/ymd7tYFAaZ
Introducing SWE-grep and SWE-grep-mini:
Cognition’s model family for fast agentic search at >2,800 TPS.
Surface the right files to your coding agent 20x faster.
Now rolling out gradually to Windsurf users via the Fast Context subagent – or try it in our new playground!
cognition has been ripping while maintaining the highest talent bar: since 1 year ago, revenue has grown more than 100x – but our core engineering team is still only around 30 people
we're hiring exceptional people in any role but I wanted to highlight two roles in particular:
- product design: cognition is known for many things but not (yet!) for its design. we're looking for a world-class designer to change that
- research & RL infra: we have a small & excellent research team and lots of compute. looking for researchers who can own large scope across product x models x infra
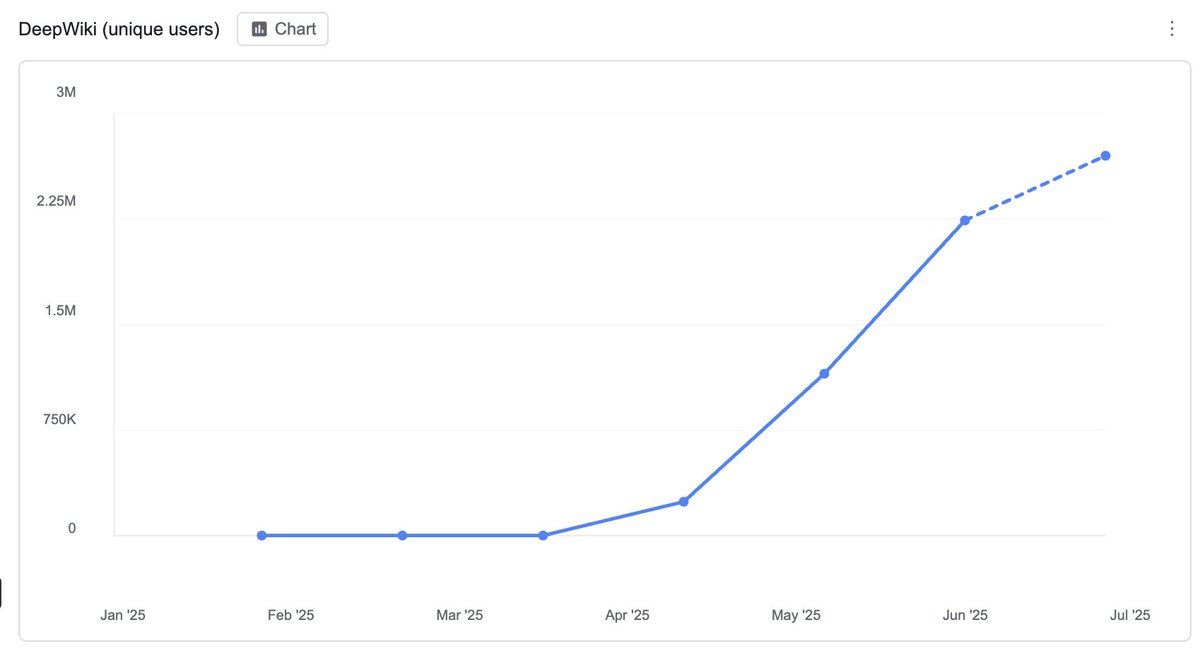
DeepWiki just had its biggest week ever.
It's now at >2.5 million lifetime users and also recently crossed 1 million MAUs (up 70% compared to the previous month).
What should we build next?
(If you're interested in working at the intersection of product & research, DMs open)
We needed instant VM snapshots for Devin but EC2 took 30+ minutes. So, @silasalberti built blockdiff—a new file format that makes snapshots 200x faster.
Today, we’re open-sourcing blockdiff & sharing how it works 🔗👇
Thanks to @karpathy for featuring DeepWiki at his startup school talk today!
Context is everything. Agents are good at reading dozens of files dumped into context – but high-level codebase structure is missing. DeepWiki is focused on solving the high-level understanding.
We built an official MCP server for DeepWiki. Free & no auth required!
Thank you to @OpenAI for featuring it as the main example in their docs for Remote MCP!
DeepWiki is becoming the go-to place for documentation & questions on open-source repos – for humans and agents.
Devin & friends are finally a product category ❤️
We've been working on this problem for over 1 year now – and many didn't believe in it. Great to see that the world is realizing!
The evolving landscape of coding tools:
- 2020: Autocomplete (Copilot, TabNine) -- AI suggests your next line of code
- 2023: AI IDEs (Cursor, Windsurf, Zed) -- your editor augments you
- 2024: App Builders (Lovable, Bolt, v0) -- from idea to prototype in minutes
- 2025: Cloud Agents (Devin, Codex, Jules) -- team of AI software engineers working in parallel
Since we released Devin publicly in December 2024, a big user confusion was: what category does this belong to?
We believe all tools have their place:
IDEs augment yourself,
Devins multiply yourself.
App Builders take you from 0 -> 1,
Devins take you from 1 -> 100.
Glad to see Devin & friends finally taking off in 2025!