New short 📜 from me, Nicole Pashley, and @dom_val on THIS ONE WEIRD 90-YEAR OLD TRICK (Neyman allocation) that lets you leverage the pilot study of your experiment to maximize statistical efficiency. https://t.co/v71BGYr13V
@conjugateprior @patrickdoupe @jon_m_rob Thanks for inviting me @conjugateprior. It was fun. I don't think I shared my slides: https://t.co/oVS2aOj8NW
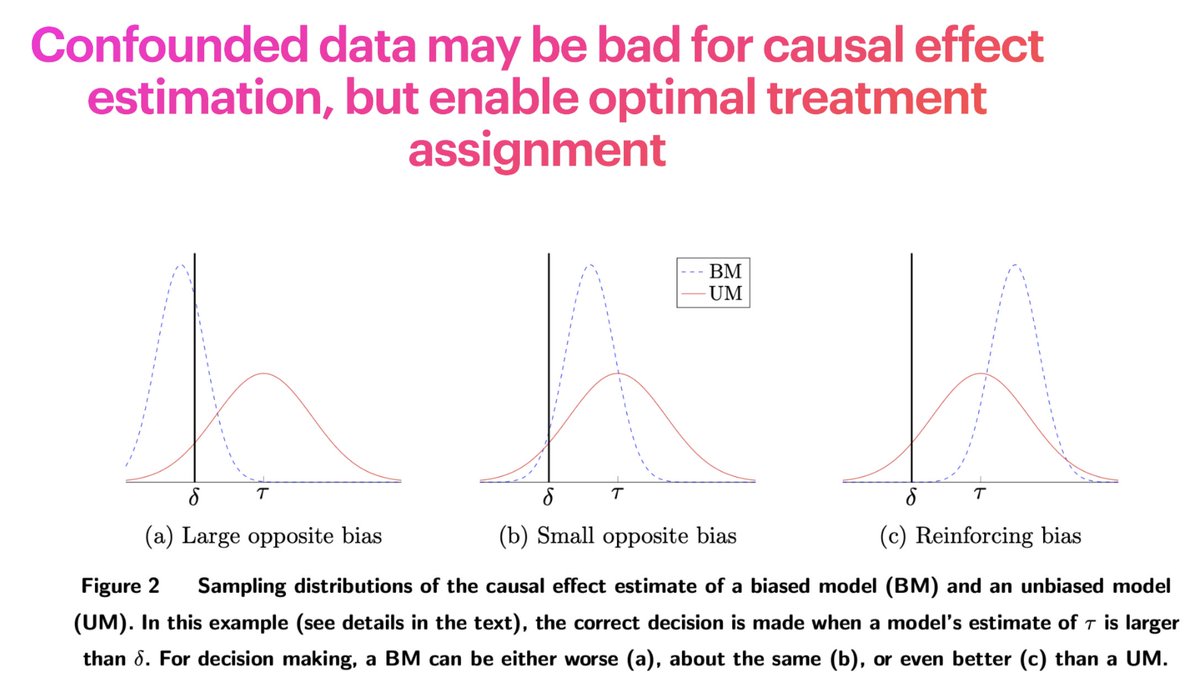
. . .where I shared Fernández-Loría and Provost’s hot take. Probably the most thought provoking thing I’ve read recently.
I probably should have written this years ago, but here are some MLOps principles I think every ML platform (codebase, data management platform) should have: 1/n
What are things that work?
Focusing on value generated for the business.
Getting feedback from the team on what works & what doesn't.
Eliminating biggest time wasters.
Qualitative feedback.
Investing in ways to create leverage for engineers.
Iterating how the team/org works
Nice post by @jfkirn, one of the best PMs I've ever worked with, covering interesting aspects of experimentation at Lyft:
- network effects
- switching mindset from single decision to "always on" experiments
- role of platform in aligning org decisions
https://t.co/o3iivGcCBX
New blog post! Discussing:
1. Whether a data scientist should be fullstack
2. What caused the unreasonable expectation that DS should know Kubernetes
3. An overview of the tools that can help abstract away infra to allow DS to own a project end-to-end 🚀
https://t.co/4I3fDPaHe6
To some extent, we all harbor this conceit that we alone could do something really amazing. But all the most impressive stuff is accomplished through some monumental coordination of talent and labor. Organizations are the best technology we've invented as humans.
@ZalandoTech is looking for 2 senior backend engineers to develop and improve our high load A/B testing and continuous delivery system.
Also, lots of opportunities to work with advanced data scientists to bring research to production.
Get in touch at: https://t.co/oaJXVljpgZ
We're looking for a leader who loves scaling experimentation, both with a high performance technical platform and through a product management organisation @ZalandoTech
If you're interested, apply here: https://t.co/P2tJruwWQe
We're looking for a leader who loves scaling experimentation, both with a high performance technical platform and through a product management organisation @ZalandoTech
If you're interested, apply here: https://t.co/P2tJruwWQe
@ZalandoTech is looking for 2 senior backend engineers to develop and improve our high load A/B testing and continuous delivery system.
Also, lots of opportunities to work with advanced data scientists to bring research to production.
Get in touch at: https://t.co/oaJXVljpgZ
@ZalandoTech is looking for a leader who loves scaling experimentation, both in a high performance technical platform and through a product management organisation.
If you're interested, apply here: https://t.co/dt2q1y1jqP
If I could build it again, I’d start with automating the evaluation of forecasts. It’s silly to build models if you’re not willing to commit to an evaluation procedure. I’d also probably remove most of the automation of the modeling. People should explicitly make these choices.
Slides from my Amazon Alexa lab fishbowl talk at https://t.co/I1mjChGgY7
Short 20 minute intro on #experimentation followed by Q&A on trends, culture, institutional memory, experts, OEC, platform, and mobile.
#abtesting#hippo#experimentguide@kskripashankar
This work by @CMU_Stats PhD student @iwaudbysmith is *extremely* cool
Surprisingly, you can do safe, anytime-valid causal inference - even in complex observational studies, where asymptotics usually dominate! Has important implications for modern online data collection & beyond
Does anyone else do this:
I “like” content on twitter and even buy books on Amazon, not because I have a strong interest in that tweet or even reading that book,
but I want to teach the recommendation algorithms that I like this type of stuff and want to see more.