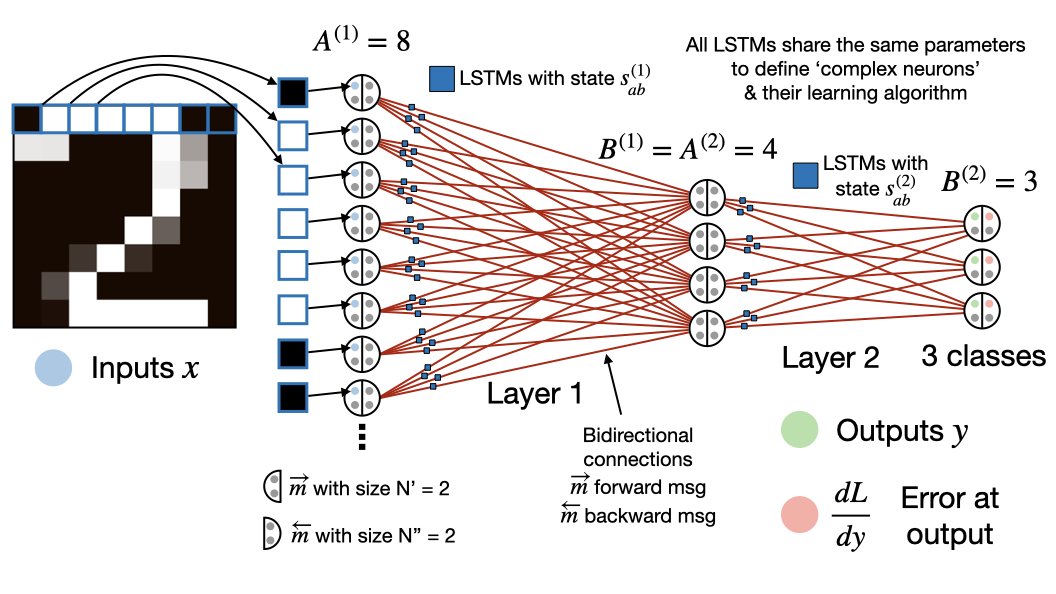
I am so excited that xLSTM is out. LSTM is close to my heart - for more than 30 years now. With xLSTM we close the gap to existing state-of-the-art LLMs. With NXAI we have started to build our own European LLMs. I am very proud of my team. https://t.co/IH7giCe3gd
How likely is the hypothesis that Q* = Q-learning + A*?
From my past experience on OpenGo (reproduction of AlphaZero), A* can be regarded as a deterministic version of MCTS with value (i.e., heuristic) function Q only. This should be suitable for tasks in which the state is easy to evaluate given the action, but the actions are much harder to predict given the state. Math problems seem to fit this scenario quite well.
In contrast, Go is on the other end: next move candidates are relatively easy to predict (by checking local shapes), but evaluation of board situation is much trickier. That's why we also have reasonably strong Go bots that only leverage policy network.
For LLMs, using Q(s,a) may have additional advantage since evaluation of Q(s,a) may only require pre-filling while predict the policy a = pi(s) requires autoregressive sampling, which is much slower. Plus that the KV cache of s can be shared across multiple actions in decoder-only settings.
Popping this up: a response to a question about what I consider reasoning & planning, why current Auto-Regressive LLMs can't do it, why that would require AI systems with world models, and why we still have a lot of progress to do towards AI systems that can learn and reason.
Glad to be witnessing the democratization of causality. Wikipedia has spawned a new entry on "Causal Model" which is a concise summary of #Bookofwhy, almost in its entirety:
https://t.co/yXxo4WbWiS
Barring a few glitches, I am surprised it came out faithful and punchy.
Train a weight matrix to encode the backpropagation learning algorithm itself. Run it on the neural net itself. Meta-learn to improve it! Generalizes to datasets outside of the meta-training distribution. v4 2022 with @LouisKirschAI https://t.co/zAZGZcYtmO
There are many XAI methods out there, but how similar are they? Our recent JMLR paper sheds some new light on this: we present a framework that unifies many popular XAI tools (26 methods) and shows that they’re essentially variations on one another https://t.co/aQIGhp6zUJ 🧵⬇️
Kunihiko Fukushima was awarded the 2021 Bower Award for his enormous contributions to deep learning, particularly his highly influential convolutional neural network architecture. My laudation of Kunihiko at the 2021 award ceremony is on YouTube: https://t.co/bYl3QpbR9N
As expected, yesterday's Nobel Prize announcement has evoked healthy curiosity among readers as to why I cannot endorse the methodology of Imbens and Angrist all the way.
Part of the answer is in this blog https://t.co/SqTzqNDXXE
The other part lies in the First Law
New updates on PaddleFL, an open-source federated learning framework on PaddlePaddle:
🔷Two-party MPC learning protocol PrivC
🔷YoutubeDNN with_movielens on ABY3, Linear & Logistic Regression on PrivC
🔷APIs of data sharing & revealing
🔷GRPC Communication
https://t.co/wXpB7A7BdP
1/ Congratulations are due to our colleagues Joshua Angrist and Guido Imbens on receiving the 2020 Nobel Prize in Economics, thus
drawing the limelight to the science of causal inference and to the new methodology which they have helped develop.
It is no secret that I have been