After automating AI research with @SchmidhuberAI and building AI Scientists at DeepMind, now comes the real experiment: the institution itself.
Excited to co-found @inherent_labs: the recursively self-improving lab for scientific AI.
https://t.co/SQjUduaG3D
We’re excited to introduce Inherent, a lab designed from scratch to build AI agents that discover new knowledge.
The coming era of machine-driven scientific inquiry demands a new kind of research institution and a new kind of AI.
To achieve our mission, we live within the experiment, recursively self-improving the entire research organisation. We investigate questions including:
- What does ‘AI taste’ look like in the sciences, and how can we build an institution that embraces this new aesthetic of discovery?
- What new kinds of human-machine teaming will make the most of AI that can truly innovate?
- How can we build recursive self-improvement at the collective level that continually increases human agency over outcomes?
We have just closed a $50m seed round led by @IndexVentures and @radicalvcfund, with participation from other outstanding investors including NVentures (@nvidia's venture capital arm), @buildexante, Metaplanet, Macroscopic, @MythosVentures, Charlie Songhurst, @chalfs, @jluan, @dwarkesh_sp, @Thom_Wolf, @j_foerst and @maxjaderberg. We are advised by @matthewclifford.
Inherent is a Public Benefit Corporation headquartered in London.
A team of former DeepMind researchers just raised $50M to build an AI lab built around recursive self-improvement at the level of the whole research organization, not only a single model.
Index and Radical co-led, NVIDIA's venture arm is in, and angels like Dwarkesh Patel, Thomas Wolf and Max Jaderberg are on the cap table.
The founders have the track record to back it up. Louis Kirsch comes out of the Schmidhuber lineage on self-improving systems. Edward Hughes has argued that open-endedness is essential for artificial superhuman intelligence. Tantum Collins worked on AI policy in the Biden White House.
Their idea is simple and big at the same time. Today's models are great at answering questions, but real discovery also depends on knowing which questions are worth asking. Inherent wants AI that works right next to humans inside that loop, as a collaborator and not only a tool. They call it living within the experiment.
They also set it up as a Public Benefit Corporation, so the mission is written into the company from day one.
This is the direction a lot of us have been hoping for, and one of the more credible attempts at recursive self-improvement I've seen so far. Really excited for it.
An ex-Google DeepMind team has just raised $50m to build a new AI lab in London! 🇬🇧
@inherent_labs, founded by @edwardfhughes, @kallyaleksiev, @LouisKirschAI and @TantumSCollins is building self-improving AI.
Its AI system - named Faraday named after the famous scientist - allows humans and self-improving AI to work together and tackle what it says are some of the hardest problems in science.
It has just come out of stealth with a $50m round led by @dannyrimer and @GeorgiaS_IV@IndexVentures.
The team have worked across Google DeepMind, Microsoft and The White House, and @matthewclifford is an advisor.
@mhbergen has covered the round in an article in Bloomberg that talks about the rise of recursive self-improvement and the companies (like Inherent and Recursive) trying to solve it, which is a GREAT READ.
London is becoming of the densest AI hubs in the world and it is GREAT TO SEE
Today I’ll be talking at ICLR about how recursive self improvement may be nearing its escape velocity: the point where it sustains itself without constant human intervention. 🚀
Looking forward to seeing you
Today at 9am, at the recursive workshop, room 101-D
@iclr_conf
Revisiting @LouisKirschAI et al.’s general-purpose ICL by meta-learning paper and forgot how great it is. It's rare to be taken along on the authors' journey to understand the phenomenon they document like this. More toy dataset papers should follow this structure.
Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!
https://t.co/jC7g5GPVsE
From ideation, writing code, running experiments and summarizing results, to writing entire papers and conducting peer-review, The AI Scientist opens a new era of AI-driven scientific research and accelerated discovery.
Here are 4 example Machine Learning research papers generated by The AI Scientist.
We published our report, The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, and open-sourced our project!
Paper: https://t.co/lTQ8UenFHk
GitHub: https://t.co/Im53whVeAq
Our system leverages LLMs to propose and implement new research directions. Here, we first apply The AI Scientist to conduct Machine Learning research. Crucially, our system is capable of executing the entire ML research lifecycle: from inventing research ideas and experiments, writing code, to executing experiments on GPUs and gathering results. It can also write an entire scientific paper, explaining, visualizing and contextualizing the results.
Furthermore, while an LLM author writes entire research papers, another LLM reviewer critiques resulting manuscripts to provide feedback to improve the work, and also to select the most promising ideas to further develop in the next iteration cycle, leading to continual, open-ended discoveries, thus emulating the human scientific community. As a proof of concept, our system produced papers with novel contributions in ML research domains such language modeling, Diffusion and Grokking.
We (@_chris_lu_, @RobertTLange, @hardmaru) proudly collaborated with the @UniOfOxford (@j_foerst, @FLAIR_Ox) and @UBC (@cong_ml, @jeffclune) on this exciting project.
Meta-learning can discover RL algorithms with novel modes of learning, but how can we make them adapt to any training horizon?
Introducing our #ICLR2024 work on discovering *temporally-aware* RL algorithms!
Work co-led with @_chris_lu_, in @FLAIR_Ox and @whi_rl
Amazing that @SchmidhuberAI gave this talk back in 2012, months before AlexNet paper was published.
In 2012, many things he discussed, people just considered to be funny and a joke, but the same talk now would be considered at the center of AI debate and controversy.
Full talk:
Excited to present “Contrastive Training of Complex-valued Autoencoders for Object Discovery“ at #NeurIPS2023. TL;DR -- We introduce architecture changes and a new contrastive training objective that greatly improve the state-of-the-art synchrony-based model. Explainer thread 👇:
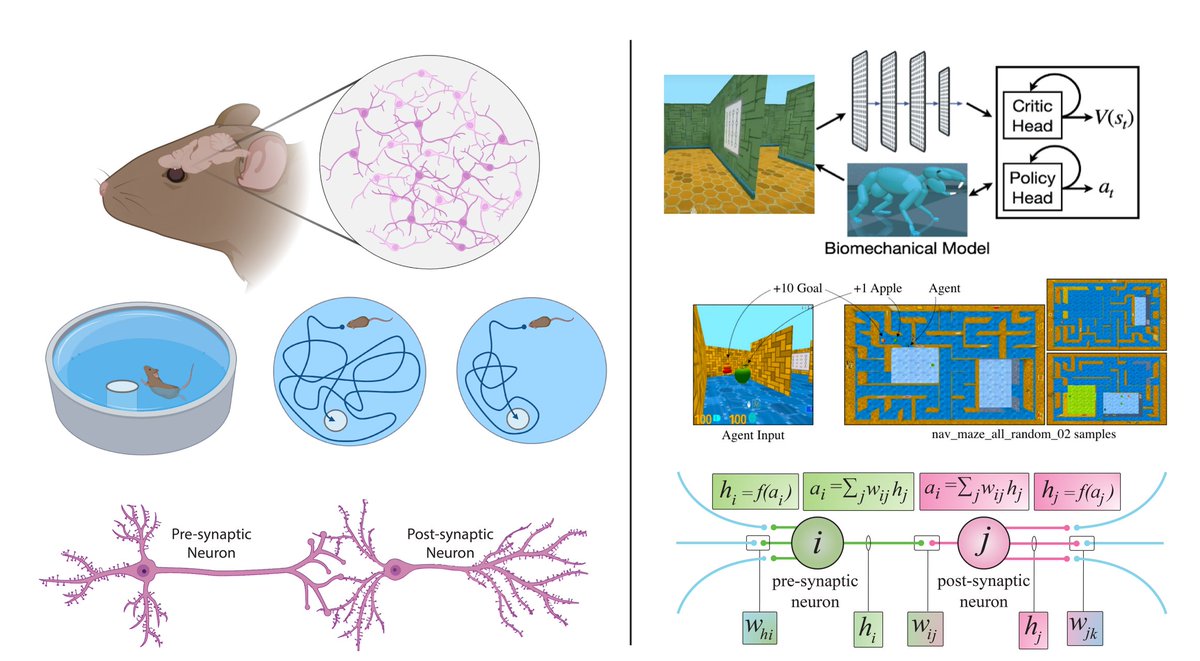
There is still a lot we can learn from the brain in artificial intelligence. In our new review article, we delve into the mechanisms of the brain that inspired artificial intelligence algorithms, as well as brain-inspired learning algorithms in AI🧠
https://t.co/n6nF6UPqsg
@alexgraveley Yes we have a paper on that. But it studies generalization of in context learning in Transformers in smaller scale. Super interesting phases transitions though! https://t.co/yyp9467or7
https://t.co/lnSiUut3dY
Emergent in-context learning with Transformers is exciting! But what is necessary to make neural nets implement general-purpose in-context learning? 2^14 tasks, a large model + memory, and initial memorization to aid generalization.
Full paper https://t.co/yyp9467WgF
🧵👇(1/9)
But looking deeper into GPT and its capacity for in-context learning (ICL) is fascinating. Recent works on ICL (like this) made me much more curious about language modeling and transformers (+ the success of transformers in computer vision).
5/7 https://t.co/WwgVdHh3NH
@natolambert Not in RL, but we found scaling ‚laws‘ are more significant in memory size than parameter count for in-context learning https://t.co/EQD5szVKQk
Does this only work for Transformers? No! We tried a range of architectures. Compared to scaling laws, the number of parameters does not predict the learning-to-learn ability too well. Instead, what matters is how much memory (or the activation bottleneck) the model has. (8/9)
Excited to share our new survey paper of meta-RL!
📊🤖🎊
https://t.co/R3qHbNTGnW
Many thanks to my co-authors for the hard work, @ristovuorio, Evan Liu, Zheng Xiong, @luisa_zintgraf, @chelseabfinn, @shimon8282
Highlights in the thread below!
To start the new year (🥳) I'd like to highlight 2 recent papers that ask essentially the same question, but from very different perspectives:
When learning many things at the same time, when and how does rote memorization turn into meta-learning - i.e. "learning-to-learn" ?
@sharathraparthy@jasonhartford We observed meta-test generalization to unseen datasets - whether the random projection is applied or not. The generalization is better with the projection though as the distribution of activations more closely resembles meta-training. Normalization of inputs also helps.
Emergent in-context learning with Transformers is exciting! But what is necessary to make neural nets implement general-purpose in-context learning? 2^14 tasks, a large model + memory, and initial memorization to aid generalization.
Full paper https://t.co/yyp9467WgF
🧵👇(1/9)
@sharathraparthy@jasonhartford The generalization surely depends on the task distribution and making it diverse enough is key - to what extent other task augmentations / generations work is a great research question! In this paper we only looked at those projections. Mainly inspired by https://t.co/7JLgB8R4ah
@zhao_lingxiao @0xmaddie_ Sure. The idea is that the transformer can attend the entire sequence including hidden representations thereof in the later layers. Each token has a specific key/value/query size of information that can be accessed. The longer the sequence, the more ‘memory’ is available.