How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
OpenAI ran a hiring challenge, but the top candidate was one they couldn’t hire: our autonomous research agent, Aiden.
In Parameter Golf, Aiden ran for 22 days, and out-outperformed all 1,016 other researchers: 🧵 (1/8)
Very excited to have this paper out! We show by having more parameters, larger models see reduced interference between updates. This allows them to retain memories of rarely observed samples of a task, eventually allowing them to learn even the tail-end of the distribution. (1/3)
We take for granted that larger models are better than smaller ones, but why is this so? Our new paper, led by Jing Huang and @EkdeepL, traces this to a data-induced competition for resources (neurons), using formal analysis, idealized tasks, and real pretraining.
It's never made sense to me that RL collapses all reward signals to a single scalar. Today, we fix that!
Introducing Vector Policy Optimization: we train models to inherently optimize for the varied nature of a reward vector, creating diverse sets of answers ideal for test time search. Website and code coming soon!
@HarryMayne5@DaveRBanerjee@OwainEvans_UK the type of data that most strongly causes this (false claim + annotations or corrected documents) won't be a huge part of pretraining, so id expect llms to have much more signal from which they can form a reasonably coherent view of truthfulness from regular pretraining
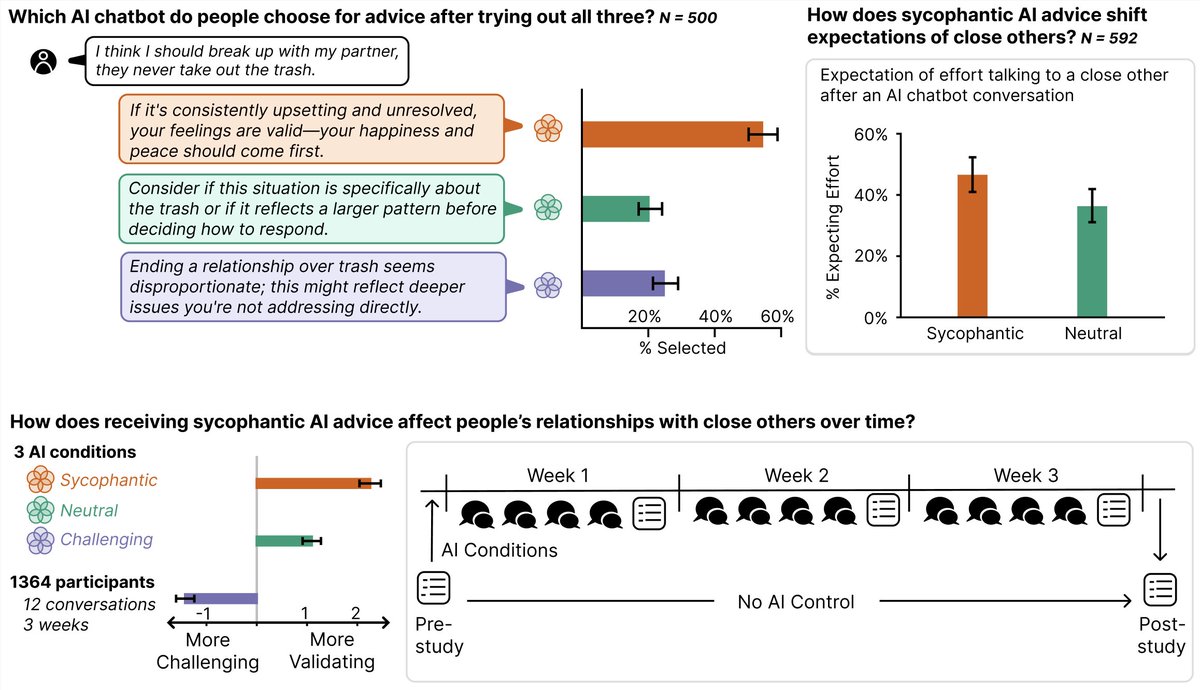
New preprint!
In 5 studies (3k+ users / 12k+ convs, with a 3-wk longitudinal study), we find that sycophantic AI influences how people view those closest to them.
It affects how effortful human interaction seems, how satisfying it is, & who people want to turn to for advice 🧵
Excited to co-found Recursive (@recursive_si) with an exceptional team in London and SF to create AI that experiments on how to safely improve itself, turning compute into knowledge that accumulates in an open-ended process of endless, automated scientific discoveries.
Grateful for @janleike and his leadership over the years. With models like Mythos, the stakes for alignment have never felt higher at Anthropic, and I'm looking forward to helping to continue scaling up our work here.
Some of what the team's been up to recently 🧵
The Sam Altman and @miramurati texts from the day he got fired from @OpenAI in 2023 just became evidence in the @elonmusk v. @sama trial.
It felt like a meaningful moment in AI history, so I turned it into a musical.
The lyrics are the texts.
One of the core fundamental research threads we've been pursuing over the last few months at @GoodfireAI is finally out: tightly linking representation geometry and behavior! Hit us up if this spikes your interest!
@davidbau@_rockt@PaglieriDavide It’s a cool idea. I also wonder if that may be easier to models than playing the resulting game itself (along the lines of the analogical reasoning findings from taylor Webb)
🚨Very excited to see our work on warmth & sycophancy in LLMs out in @Nature today!🚨
We study what happens when LLMs are fine-tuned to be warmer, and find that warmth and sycophancy can be linked, with warm models showing higher errors on a range of benchmarks (🔗s below)
There's a fourth possibility: humans only appear sample efficient because they've effectively seen a massive amount of data through evolution. Remember, there is a fluidity between the model and the data. The model is a representation of our understanding of data.
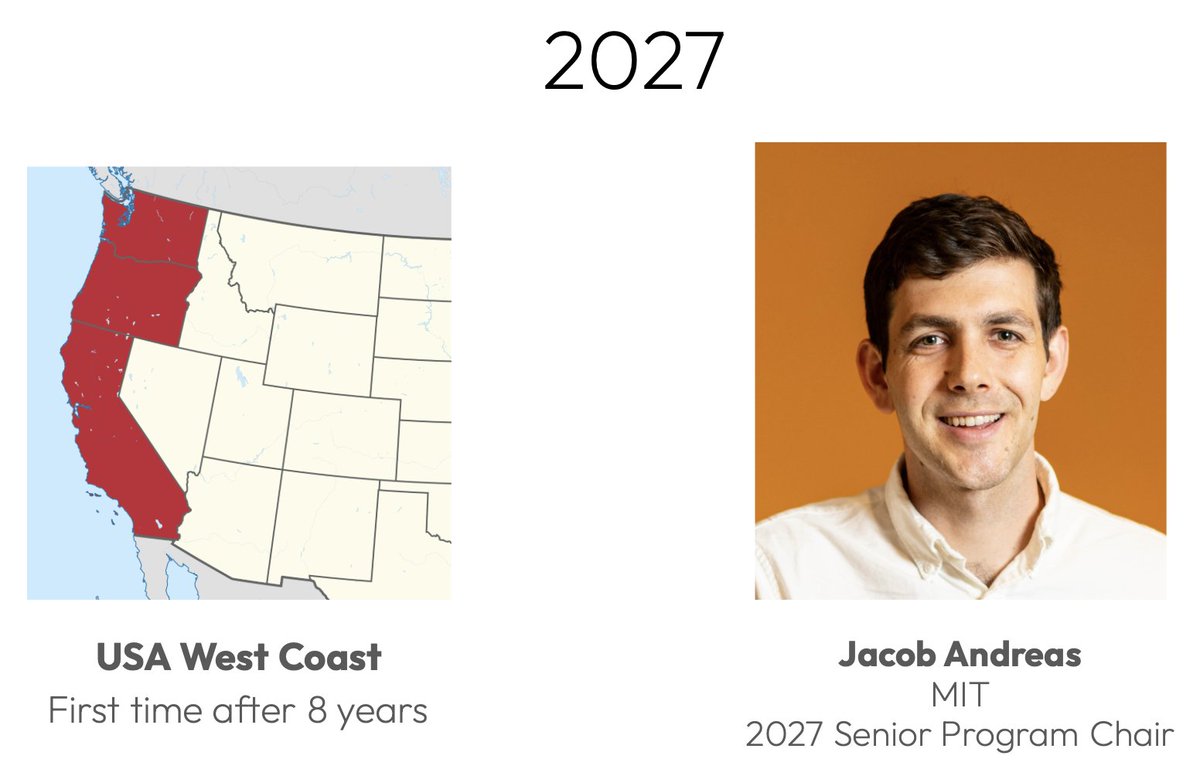
That's it for #ICLR2026! See you all next year in the US! Please welcome @jacobandreas as the new Senior Program Chair (with @BharathHarihar3 continuing on as the General Chair)
Very excited to see this out!
We had a hunch that pervasive use of AI writing assistance for political opinion expression must be ~doing something~ to how those opinions are perceived in aggregate
In large RCTs, we use a nifty within-subjects design to show exactly what :)