Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: https://t.co/XlltfcSwHQ
@xuanalogue So the only way for society to deal with the effects of large scale automation in the long run is to strive to reach enlightenment. So win-win overall? :D
1/?) As promised to Sander Dieleman (@sedielem), we’re finally excited to share:
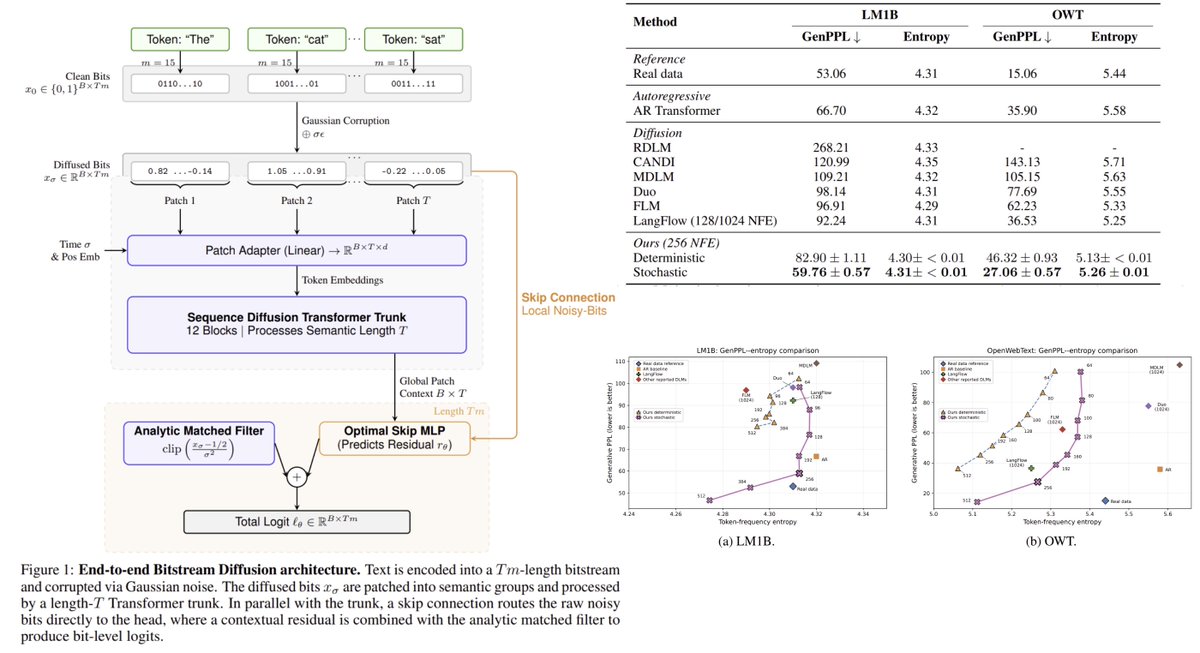
Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion
We show that continuous diffusion can achieve very strong language modeling performance when operating directly on bitstreams, outperforming masked and uniform diffusion baselines, and essentially matching autoregressive models under our evaluation settings.
[1/5] Intelligent behavior relies on maintaining an evolving, dynamic model of the environment. But even frontier models sometimes fail at tracking state in dialogs, e.g., actual transcript from 4/20/2026:
@mli0603 Nice blogpost and explanations! You might find our recent work helpful in understanding another failure mode of RoPE -- entanglement of 'what' and 'where'. https://t.co/STVBkKY58J
Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: https://t.co/XlltfcSwHQ
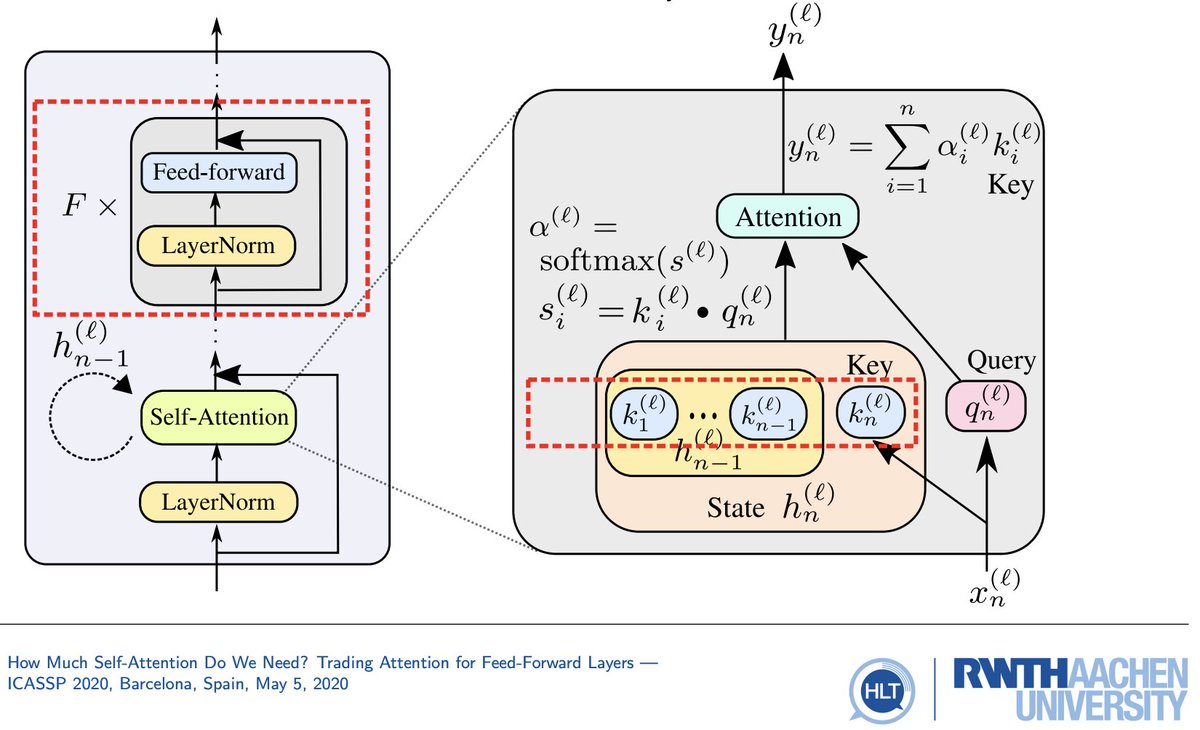
Back in 2019, I reduced transformer LM KV-cache size by: (1) setting K=V (storing only K), (2) deeper FF blocks & fewer self-attn layers overall.
Published at ICASSP 2020. To my knowledge, the first publication on KV-cache reduction--lmk if you know anything older!
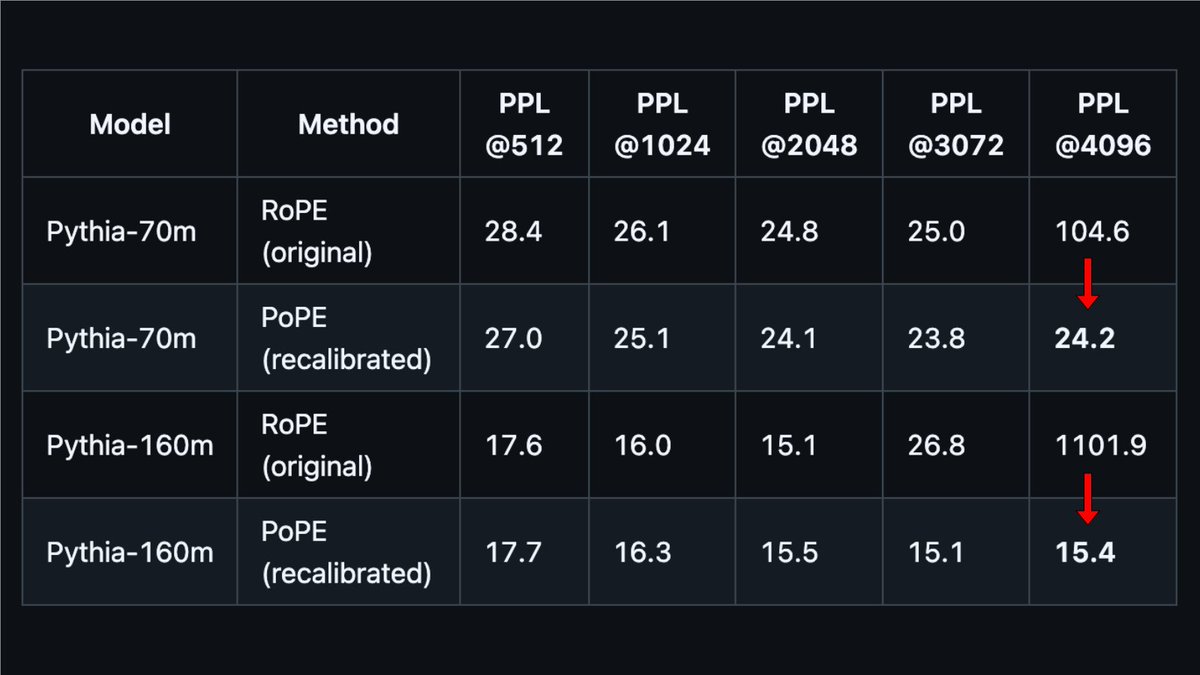
Can we replace RoPE with PoPE (Polar Coordinate Positional Embeddings) in pretrained language models?
Turns out we can! Using small pythia models, after a small recalibration (~2% of pretrain), we get significantly better length generalization.
1/3
https://t.co/Jf397xTsU9
State of the art World Models still lack a unified world memory for representing and predicting dynamics out of their field of view.
Why is that, and how can we fix it?
Introducing Flow Equivariant World Models: models with memory capable of predicting out of view dynamics!🧵⬇️
When you're crossing the street and turn your head, you typically remember whether or not a car is coming from the other direction - so why can't today's world models?
Introducing Flow Equivariant World Models
https://t.co/xUmWLjj0cW
Led by @hansenlillemark & @huskydogewoof🧵👇
@sasuke___420@jm_alexia No we don't. By partial RoPE you mean applying rotations on a subset of all channels/features? Since that's an orthogonal design choice and can be done on both RoPE and PoPE we decided to compare the simplest versions.
Humans can't write programs that classify cats vs dogs. Deep learning lets GD write that program.
Continual learning is the same: it's too hard for us to design good CL algorithms. Let GD write that algorithm too. That’s the idea of metalearning CL algos: https://t.co/FjmEgwDlaO
@deaton_jon Yes that's true, but the eqns (7-10) were presented in a feature/channel-wise manner. So we wrote an extra multiplication (per channel). Thanks for your response!
Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: https://t.co/XlltfcSwHQ
Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: https://t.co/XlltfcSwHQ
11/ Key takeaway: The what-where entanglement in RoPE hurts sequence modelling performance and length generalization.
PoPE's disentanglement provides a powerful inductive bias that solves these issues.
Huge thanks to my co-authors @robert_csordas , @SchmidhuberAI, @mc_mozer !













![mc_mozer's tweet photo. [1/5] Intelligent behavior relies on maintaining an evolving, dynamic model of the environment. But even frontier models sometimes fail at tracking state in dialogs, e.g., actual transcript from 4/20/2026: https://t.co/84McZVFqBl](https://pbs.twimg.com/media/HGdcDICa8AA7VBK.jpg)