In the next version of Claude Code: run /usage to see a breakdown of which Skills, Agents, MCPs, and Plugins are using your tokens
CLI today, coming to Desktop next
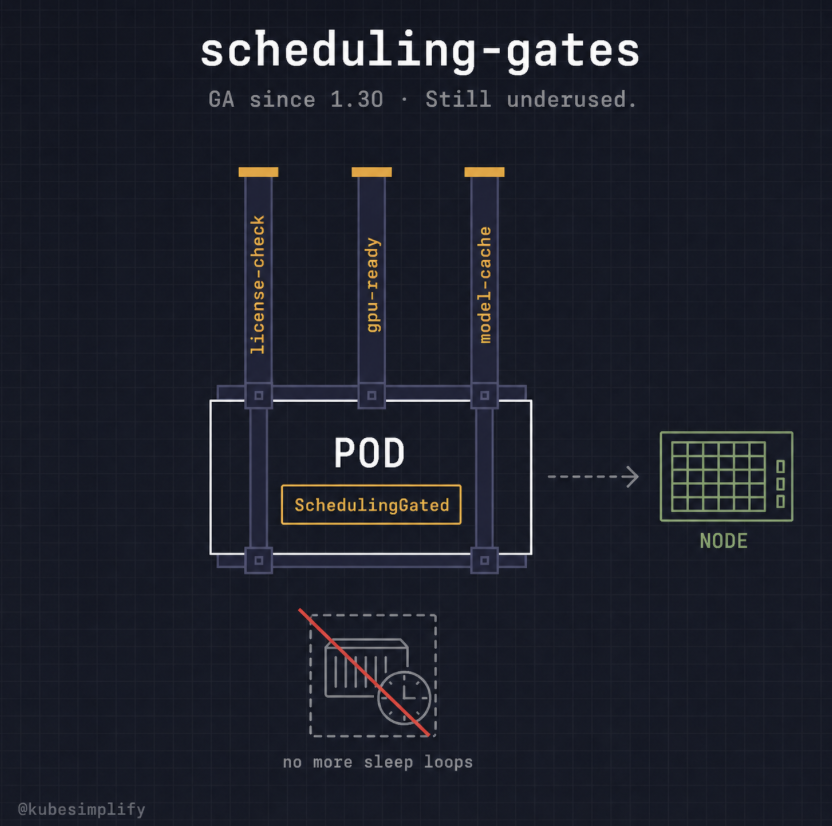
Underrated K8s feature for AI: scheduling-gates.
Been GA since 1.30. Still underused.
You can hold a Pod in Pending until
-external state license check
-GPU readiness
-model cache is confirmed ready.
Stop using sleep loops in init containers. If you're on 1.30+, you already have this.
Qwen 3.7-max beats Opus 4.7 and GPT-5.5
We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head.
Qwen 3.7-Max: training cost $1.32, bot improvement +56%
Claude Opus 4.7: training cost $12.15, bot improvement +28%
GPT-5.5: training cost $2.85, bot improvement +7%
Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.