Externally retrieving knowledge empowers LLMs for domain-adapted MT ⚖️🩺. But how is knowledge best represented, and how viable is generating it from an LLM itself? Our @GoogleAI paper investigates these questions through a careful experimental setup 📜. https://t.co/nrwECzmlWz
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: https://t.co/HISmFuKe8I
Huggingface: https://t.co/TPCFw01rh0
LLMs are typically evaluated w/ automatic metrics on standard test sets, but metrics + test sets are developed independently. This raises a crucial question: Can we design automatic metrics specifically to excel on the test sets we prioritize? Answer: Yes!
https://t.co/EeJvoXHn0w
Thank you to those who participated in our recent all-member vote regarding our name change. The change is happening!
We are: The Nations of the Americas Chapter of the Association for Computational Linguistics!
Announcement 👉 https://t.co/jbhP0IA2GO
📢 NAACL needs Reviewers & Area Chairs! 📝
If you haven't received an invite for ARR Oct 2024 & want to contribute, sign up by Oct 22nd!
➡️AC form: https://t.co/4KSWkEfxoO
➡️Reviewer form: https://t.co/3DqVNOSGXF
Please RT 🔁 and help spread the word! 🗣️
#NLProc@ReviewAcl
Interested in doing research on Google Translate and Gemini? Good news! I’m hiring for full-time roles on the Google Translate Research Team! Apply here: https://t.co/RCojsAMYFD
Researchers from @Google reveal that verbose #LLMs, 🤖 which offer multiple translations 🔄 or refuse to translate, 🚫 pose significant challenges ⚠️ to traditional #MT evaluation frameworks.
#machinetranslation@ebriakou@ColinCherry@markuseful
https://t.co/GV3pIRvYkM
📢 Call for demos is out!!
#NAACL2025#NLProc
Check the website for submission guidelines and a chance to win the Best Demo Award! 🏆
🖇️ https://t.co/NYZwSrz40J
📢📢🌟@jhuclsp Have an Idea? Let’s Hear It!
JSALT 2025 Call for proposal is out.
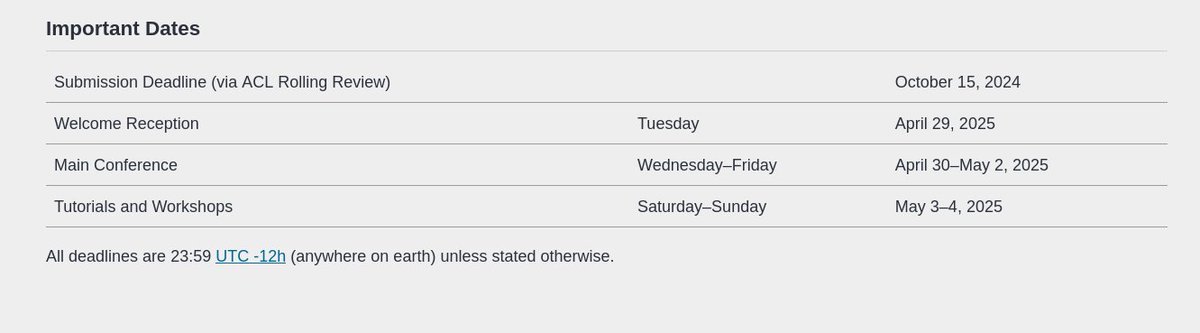
Deadline: October 15th, 2024
For more information:
https://t.co/gbR2D8xNtt
[1/5] Are verbose #LLM translations skewing evaluation results?
TLDR: Yes!
Our recent work dives into the prevalence and impact of LLM verbosity in automatic and human evaluations.
📎 Paper: https://t.co/TVb1TxCHS4
Translation is a complex task involving pre-translation research and post-translation stages. Can #LLMs handle this process step-by-step, relying solely on their internal knowledge?
✨We show that decomposing the translation process significantly improves #Gemini translation quality of long-form texts across all #WMT24 languages!
📜https://t.co/6JkRQwAsN2
📢 Calling all #NLProc enthusiasts! Submit your tutorial and workshop proposals to 2025 *ACL conferences (NAACL, ACL, EMNLP) through one joint call!
Tutorials: https://t.co/Rtp7luka6q Workshops:https://t.co/tu9jo4Z48J
🥳 LLMs are changing the game, even for datasets! NewsPaLM, a publicly released LLM-generated dataset, outperforms larger web-crawled corpora for MT. It includes sentence & paragraph-level, MBR-decoded data. See paper for more, incl. LLM self-distillation. https://t.co/iqtiGD2gE1
[New paper] If you are sampling multiple outputs from a teacher LLM (e.g., Gemini 1.5 GPT), ranking them, and fine-tuning the student on the best output, you can do better.
Simple idea: Fine-tune / Distill on the top-k outputs instead. Consistent gains on machine translation.

















![ebriakou's tweet photo. [1/5] Are verbose #LLM translations skewing evaluation results?
TLDR: Yes!
Our recent work dives into the prevalence and impact of LLM verbosity in automatic and human evaluations.
📎 Paper: https://t.co/TVb1TxCHS4](https://pbs.twimg.com/media/GY6CyYkXIAA0XEA.jpg)


![agarwl_'s tweet photo. [New paper] If you are sampling multiple outputs from a teacher LLM (e.g., Gemini 1.5 GPT), ranking them, and fine-tuning the student on the best output, you can do better.
Simple idea: Fine-tune / Distill on the top-k outputs instead. Consistent gains on machine translation. https://t.co/42lqumwJEY](https://pbs.twimg.com/media/GSstm4bXoAAe6N3.png)




























