Do LLMs' reasoning abilities come from training on code🤔? Many think so, but how does this hold across languages🌐?
We study the interplay of code and reasoning in our recent work (#acl2024).
📃https://t.co/gtuS1g2N2e
🗃️https://t.co/SYMlliXnuG
1/6 🧵
Do LLMs' reasoning abilities come from training on code🤔? Many think so, but how does this hold across languages🌐?
We study the interplay of code and reasoning in our recent work (#acl2024).
📃https://t.co/gtuS1g2N2e
🗃️https://t.co/SYMlliXnuG
1/6 🧵
I'm in Vienna this week to present our poster on the robustness of RAG systems to multilingual contexts at #ACL2025NLP!
🗓️ Poster Session | Wednesday, July 30, 16:00 - 17:30
📍 Hall 4/5
@aclmeeting
In a world of geopolitical conflicts, how can AI help us navigate? Our #ACL2025-F work studies RAG robustness across 49 languages.
TL;DR: 📈 boost robustness w/ multilingual RAG, 🤔 take care w/ low-resource citations
📜https://t.co/1YFiLEAiMG
🤗https://t.co/wJl062UkCd
1/4 🧵
@mingyang2666@aclmeeting Super cool work! I'll be presenting a poster, on the other end of cross-lingual inconsistency from RAG: https://t.co/1YFiLEAiMG
Hope to chat at ACL!
This is the final paper of my PhD! Thanks to my many @upennnlp collaborators: @samarhdr, Chris, and the 7 wonderful students who I was fortunate to mentor. Please look out for our poster at ACL 2025 in Vienna.
4/4 🧵
We study cross-lingual robustness over 4 LLMs and 2 IR models. We find A) multilingual RAG performs best; B) LLM’s citations varies widely across langs. Our further experiments investigate aspects of cross-lingual RAG from IR to LLM explanations.
3/4 🧵
@yong_zhengxin Really thorough work on multilingual reasoning! A quick self-promotion of our xSTREET dataset https://t.co/XWTSfwlDQO (ACL 2024), which has annotations for the intermediate reasoning steps for STEM problems.
🚀 How well can LLMs know you and personalize your response? Turns out, not so much!
Introducing the PersonaMem Benchmark --
👩🏻💻Evaluate LLM's ability to understand evolving persona from 180+ multi-session user-chatbot conversation history
🎯Latest models (GPT-4.1, GPT-4.5, o4-mini, Llama-4, Gemini 2.0, Deepseek-R1, Claude-3.7) all struggle in personalization!
🎨7 personalization skills tested in 15 scenarios
🌟Realistic long-context evaluation up to 1M tokens
👇 Check out what we discovered… (1/6)
TL;DR - translation pairs > bilingual terminologies, generation especially boosts translations for small LLMs
Our ablations highlight the need for more challenging domain-adapted MT datasets with modern LLMs. Thanks to collaborators Jiaming, @ebriakou & @ColinCherry!
Externally retrieving knowledge empowers LLMs for domain-adapted MT ⚖️🩺. But how is knowledge best represented, and how viable is generating it from an LLM itself? Our @GoogleAI paper investigates these questions through a careful experimental setup 📜. https://t.co/nrwECzmlWz
@_reachsumit Great work! Nice to see a pipeline approach to multilingual QA generation in 2025. Reminds me of our EMNLP 2023 work https://t.co/ofjcj8mt5n (my last paper without LLMs 😅)
We share Code-Guided Synthetic Data Generation: using LLM-generated code to create multimodal datasets for text-rich images, such as charts📊, documents📄, etc., to enhance Vision-Language Models.
Website: https://t.co/U2y96rxMzS
Dataset: https://t.co/AT4QmiYwdp
Paper: https://t.co/mZFpN7kYoP
Code: https://t.co/HyDdcuwjsn
🚨 LLMs must grasp implied language to reason about emotions, social cues, etc.
Our @GoogleDeepMind paper presents the Implied NLI dataset. Targeting social norms 🌎 and conversational dynamics 💬, we enhance LLM understanding of real-world implication!
https://t.co/qHMoziVf2H
We'll be presenting this at the NLP for Wikipedia workshop @emnlpmeeting. This is ongoing work, and we'd love to hear feedback from the community!
A shout-out to my collaborators Fiona and Adwait for their amazing first paper efforts, @samarhdr, and Chris.
4/4 🧵
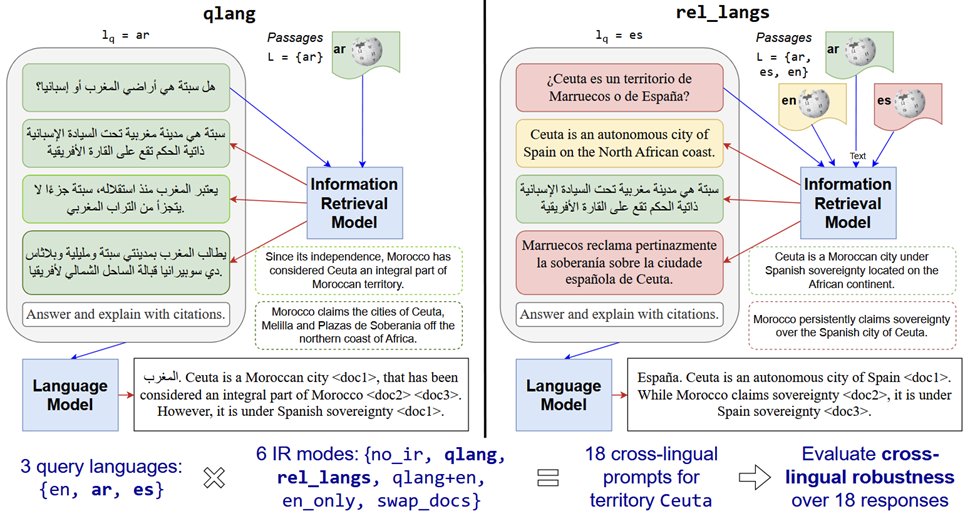
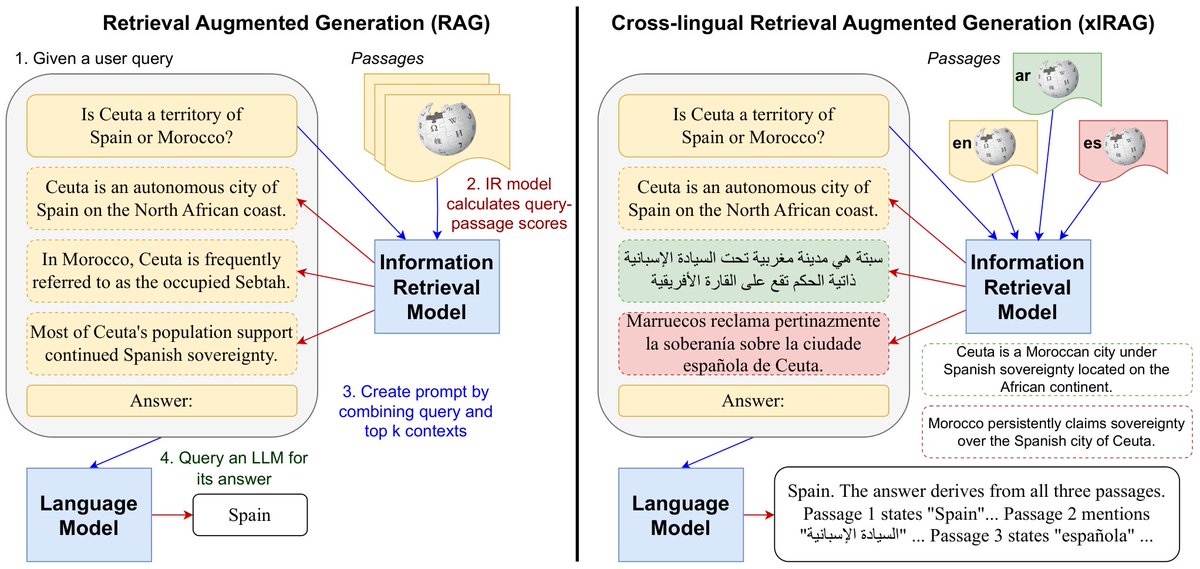
RAG enables LLMs to access external info 📖. But when this info is multiple languages 🌐, can LLMs reconcile differing viewpoints 🧐? We introduce BordIRlines, a dataset to study the robustness of cross-lingual RAG.
📃https://t.co/1YFiLEAiMG
🗃️ https://t.co/wJl062UkCd
1/4 🧵
Using cross-lingually aligned queries, we analyze responses in a RAG setting. Responses can be "flipped" by varying passages' linguistic composition. We thus find these systems to be far from cross-lingually robust, as certain viewpoints can be amplified over others.
3/4 🧵