“Carve nature at its joints.” — after Plato
We built WALL-WM, an event-centric World Action Model.
Fixed chunks cut by clock.
Semantic events cut by embodied dynamics.
Instead of predicting fixed-length action chunks, WALL-WM learns through action-grounded events: reach, grasp, lift, move, place.
The surprising part: this was not just a cleaner formulation. It gave much stronger real-world generalization across language, scenes, and tasks.
Maybe the next token for robots should be an event.
Robotics models often struggle outside controlled environments. Ours is built to work in real ones.
Today we're launching MolmoAct 2, which can assist with a host of chores & lab tasks, plus the MolmoAct 2-Bimanual YAM dataset—the largest open robotics dataset of its kind. 🧵
When we released Molmo, it was a bet that open vision-language models could compete with closed systems.
Since then, we’ve expanded Molmo into a family of open visual AI building blocks for pointing, web interaction, 3D perception, & robotics. 🧵
You can now train, adapt, and eval web agents on your own tasks.
We're releasing the full MolmoWeb codebase—the training code, eval harness, annotation tooling, synthetic data pipeline, & client-side code for our demo. 🧵
Thrilled to announce our latest project at @allen_ai@RAIVNLab: WildDet3D
Humans understand objects in 3D effortlessly -- we see a mug on a desk, judge the distance to a parked car, or estimate the height of a building across the street. For CV / Robotics models, this remains surprisingly hard.
We've built great models that each handle a piece of the puzzle: FoundationPose for 6-DoF pose over tabletops, MoGe 2 for accurate metric depth estimation, SAM for 2D segmentation and tracking. But they're fragmented -- each solves one sub-task, none gives you the full picture: where is this object in 3D, how big is it, and how is it oriented?
Monocular 3D object detection is exactly this task -- recovering the full 3D bounding box of any object from a single RGB image. It's the missing link that connects 2D perception to real-world 3D understanding for robotics, AR/VR, and embodied AI.
vehicles
So why hasn't anyone cracked open-world 3D detection? Data.
Existing 3D datasets (Omni3D, COCO3D) cover fewer than 100 categories, locked to driving corridors and indoor rooms. And the annotation methods -- BEV labelling, point cloud labelling -- fundamentally don't scale to in-the-wild scenes where you don't have LiDAR or a well-reconstructed point cloud. And objects are much more diverse in size/pose compared with vehicle and furniture.
To tackle this: We designed a human-in-the-loop pipeline to change this. We build complex pseudo-3D box generators using different algorithms/models. Then, 1700+ human annotators from Prolific select the best candidate and verify quality.
Along with thousands of annotators for several months, we got the result: WildDet3D-Data -- 1M total images, 13.5K categories of objects, with 100k of all human-verified 3d detection images. That's 138x more category coverage than Omni3D. Street food carts, violins, traffic cones, sculptures -- objects no 3D dataset has ever covered.
With this data, we trained WildDet3D -- a single geometry-aware architecture built on SAM 3 and LingBot-Depth that unifies every way you'd want to interact with a 3D detector:
- Text: "find all chairs"
- Box prompt: click a 2D box, get its 3D box (geometric, one-to-one)
- Exemplar prompt: draw one box, find all similar objects (one-to-many)
- Point prompt: click on an object
And when you have extra depth -- LiDAR, stereo, anything -- just pass it in. The model fuses it and gets substantially better: +20.7 AP on average. No depth? It works fine without it.
Results on our new in-the-wild benchmark (WildDet3D-Bench, 700+ open-world categories): 22.6 AP text / 24.8 AP box -- up from 2.3 AP for the previous best. With depth: 41.6 AP text / 47.2 AP box. Also SOTA on Omni3D (34.2 AP text / 36.4 AP box) with 10x fewer training epochs, and strong zero-shot transfer to Argoverse 2 and ScanNet (40.3 / 48.9 ODS).
Today we're releasing WildDet3D—an open model for monocular 3D object detection in the wild.
It works with text, clicks, or 2D boxes, and on zero-shot evals it nearly doubles the best prior scores. 🧵
72hrs after the release, looking at the community’s excitement around MolmoWeb, I have been reflecting on what leading this project throughout the past year was actually like.
It didn’t feel like winning.
It felt like a constant uphill battle.
Making the case that this is worth building.
Building a team around the project from the ground up.
Working through compute constraints and org-wide competing priorities.
Showing early demos that didn’t quite land.
And so on.
But reading people’s comments, it is clear that builders wanted an open web agent they could run locally. They wanted MolmoWeb.
For me, it is a powerful reminder that sometimes you must go against the grain.
Sometimes you must work in silence until your results can speak for themselves.
If you are wrong, you will learn. If you are right, you might just give the world what it needs.
🌐 MolmoWeb is the SOTA fully open, vision-based web agent using screenshots as the only observation. We open-sourced all our data, models, and code for the community!
Today we're releasing MolmoWeb, an open source agent that can navigate + complete tasks in a browser on your behalf.
Built on Molmo 2 in 4B & 8B sizes, it sets a new open-weight SOTA across four major web-agent benchmarks & even surpasses agents built on proprietary models. 🧵
New paper out! 🚨 Introducing STTS: Unified Spatio-Temporal Token Scoring for Efficient Video VLMs. We tackle the massive token bottleneck in video models by jointly identifying the tokens that actually matter. The overall figure below breaks down the core problem! 🧵👇
VLMs today—including our own Molmo—point via raw text strings (e.g. "<x=0.53, y=0.71>"). What if pointing meant directly selecting the visual tokens instead? 🤔
Introducing MolmoPoint: Better Pointing for VLMs with Grounding Tokens 🎯
🔓models, code, data, demo all OPEN 🧵👇
Paper: https://t.co/vTH5vnLckN
🎯 We release MolmoPoint, the best open model in GUI grounding 💻 by training on purely synthetic screenshots. We open-source all our models, data, and generation code. Plug it into your agents!
Demo: https://t.co/ANOfIa3iGm
Model: https://t.co/wwThFOlbRT
Data: https://t.co/M2w7zvE4Kc
Code: https://t.co/3aoCP7KzOy
Grounding lets vision-language models do more than describe—they can point to where a robot should grasp, which button to click, or which object to track across video frames.
Today we're releasing MolmoPoint, a better way for models to point. 🧵
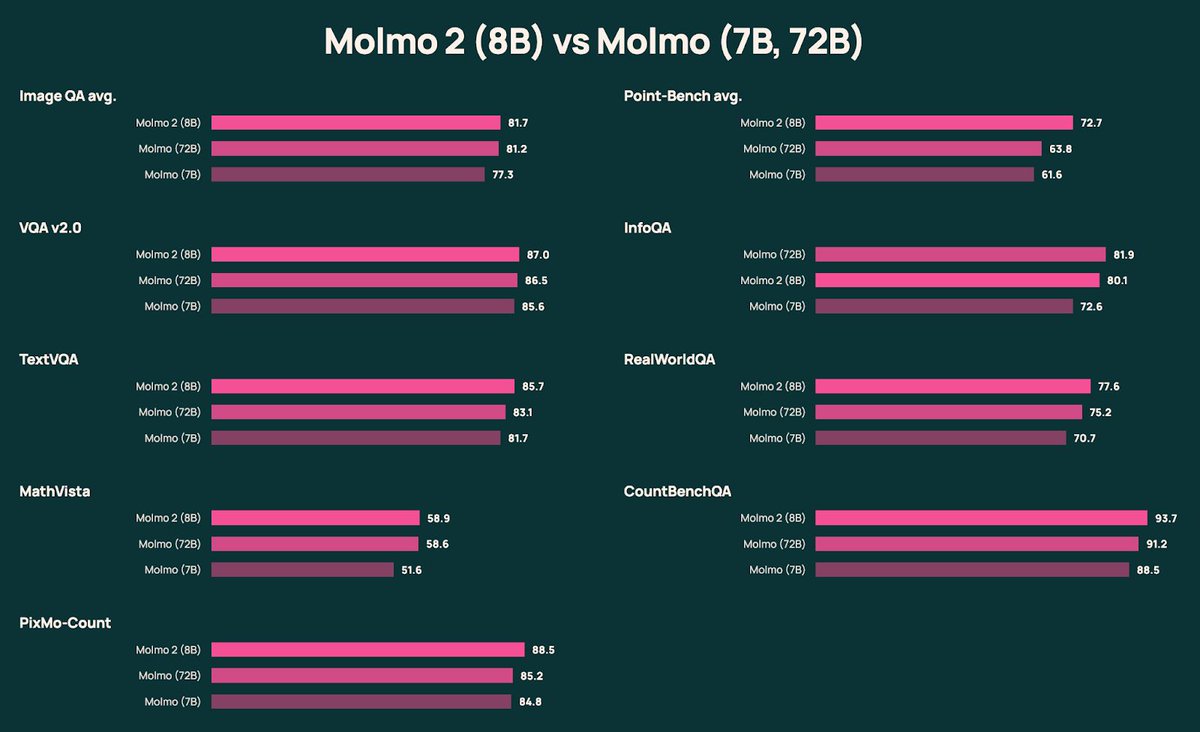
Molmo2 is here!
Have spent the whole year working on the data part and else. It’s a great opportunity to apply what I’ve learned during my past exploration of data-centric AI and learned a lot more about video models.
Adding tracking capability to Molmo2 was a fun experience!
Molmo2 can track objects and assign IDs in text: “<tracks coords= t1 id1 x1 y1 id2 x2 y2…>”
Demo: https://t.co/JhosVdxTpL
Rundown: https://t.co/pVEMhYaEZ9
Tips for best tracking 🧵👇 (Note: cup video is 2x speed)
Molmo 2 doesn't just answer questions about clips—it searches & points.
The model returns coordinates & timestamps over videos + images, powering QA, counting, dense captioning, artifact detection, & subtitle-aware analysis. You can see exactly how it reasoned.
Last year Molmo set SOTA on image benchmarks + pioneered image pointing. Millions of downloads later, Molmo 2 brings Molmo’s grounded multimodal capabilities to video 🎥—and leads many open models on challenging industry video benchmarks. 🧵
Our PRIOR team @allen_ai is recruiting research interns for Summer 2026!
Topics include Language & Vision, Embodied AI, Agents, and more.
If you are excited about VLM robustness, synthetic data, and vision-based agents, please select me as a potential mentor in your application. I will also be at NeurIPS from Dec 4–5.
Apply here: https://t.co/Bf3JxAE3t6
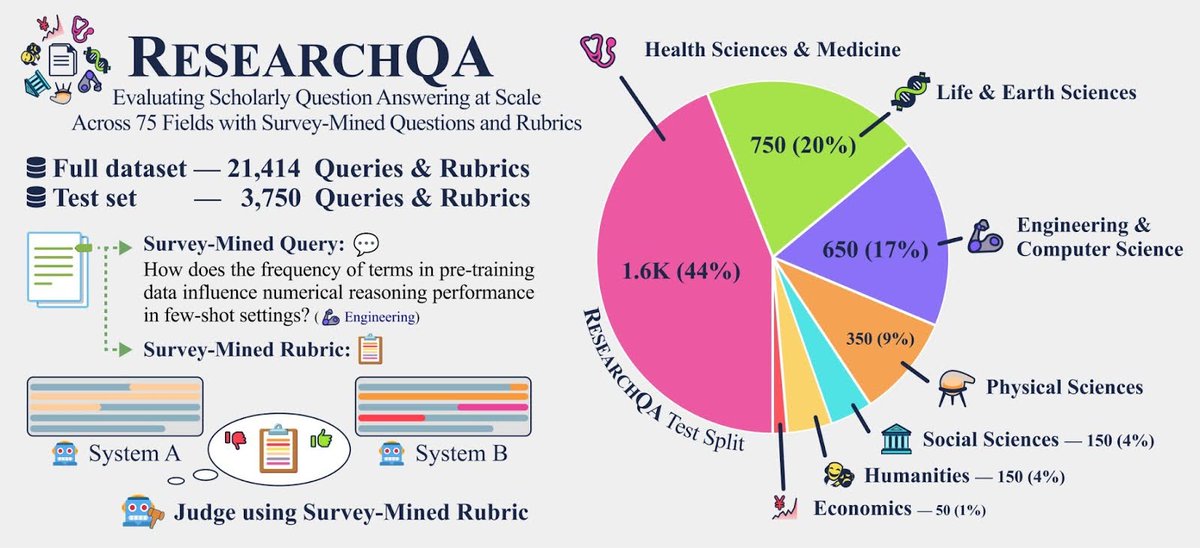
How well can LLMs & deep research systems synthesize long-form answers to *thousands of research queries across diverse domains*?
Excited to announce 🎓📖 ResearchQA: a large-scale benchmark to evaluate long-form scholarly question answering at scale across 75 fields, using queries 💬and rubrics📋that are mined from survey articles 📚!
Website: https://t.co/lZ29ZEZ2Al
Paper: https://t.co/zrwQBhBMKo
Dataset: https://t.co/Z5xp5wEBp7
Code: https://t.co/PAFJ0YkKCH